Что нужно знать о развитии субд
Содержание:
- Microsoft Access
- Список литературы по теме:
- Современные технологии
- Создание связей между сущностями
- Установка и настройка MS SQL Server Management Studio
- Настройка и работа в Management Studio
- Иерархическая база данных, структура иерархических данных
- MySQL
- Классификации СУБД
- Колоночные
- Как хранится информация в БД
- Что такое схемы базы данных?
- Каким требованиям должна отвечать современная СУБД?
- Индексы
- Ключ-значение
Microsoft Access
Система управления базами данных от Microsoft, которая сочетает в себе реляционное ядро БД Microsoft Jet с графическим интерфейсом пользователя и инструментами разработки ПО.
Идеально подходит для начала работы с данными, но производительность не рассчитана на большие проекты. В MS Access можно использовать C, C#, C++, Java, VBA и Visual Rudimental.NET. Access хранит все таблицы БД, запросы, формы, отчёты, макросы и модули в базе данных Access Jet в виде одного файла.
Разработчик: Microsoft Corporation
Особенности
- Можно использовать VBA для создания многофункциональных решений с расширенными возможностями управления данными и пользовательским контролем.
- Импорт и экспорт в форматы Excel, Outlook, ASCII, dBase, Paradox, FoxPro, SQL Server и Oracle.
- Формат базы данных Jet.
Список литературы по теме:
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. C. J. Date Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с.
Файловая система NTFS Что такое информация?
Современные технологии
При разработке программ используется прием, когда приложение программы делится на клиентскую часть и управляющий сервер. Первый компонент представляет собой пользовательский интерфейс, который видит работник. Сущность второго понятия заключается в сборе, хранении и применении информации, координировании безопасности.
Взаимодействие двух частей начинается после формирования запроса пользователя к базе. Клиентская секция направляет интерпелляцию к серверу, который выполняет команду. Результат обработки отправляется на персональное устройство клиента. Если управление исключает вариант клиент-сервер, то снижается производительность получения информации. Это происходит из-за необходимости копирования файла на личную ЭВМ с последующей обработкой.

Технология обеспечивает пользователю просмотр удобного интерфейса и получение результата запроса в удобной форме. При этом есть возможность применения нескольких взаимосвязанных приложений. Например, в области Access могут использоваться возможности построения таблиц или диаграмм в программе Excel, а отчет клиент получает в виде текста из Word.
Используется технология SQL — язык для создания запросов в структурированной форме. Модель применяется для обработки основных информативных сведений, которые содержатся в базах других приложений. Данные обрабатываются как на персональном устройстве, так и в базах основного сервера.
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
Создание базы данных mysql от А до Я
Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Создание базы данных SQL и работа с таблицами в SQL
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Установка и настройка MS SQL Server Management Studio
После того, как мы настроили сервер. Нужно настроить клиент. MS SQL Server Management Studio предоставляет удобный визуальный интерфейс для клиента и позволяет удобно разрабатывать и отправлять серверу запросы.
Установка его не сложнее плеера, поэтому останавливаться на этом не будем. Скачайте его с официального сайта Microsoft по одной из ссылок ниже.
- Скачать SQL Server Management Studio (16.5.1) https://download.microsoft.com/download/3/1/D/31D734E0-BFE8-4C33-A9DE-2392808ADEE6/SSMS-Setup-RUS.exe
- Скачать SQL Server Management Studio (17.0, версия-кандидат https://download.microsoft.com/download/B/2/3/B234198E-747D-4F89-9008-F39A7E4702D3/SSMS-Setup-RUS.exe
И установите. Программа сама определит, где у вас сервер. Просто следуйте инструкциям.
Настройка и работа в Management Studio
- Найдите Management Studio в меню «ПУСК» и запустите.
- В открывшемся окне соединения с сервером выберите:
В поле тип сервиса – Ядро СУБД
В поле имя сервера – имя сервера, которое вы указали при установке
Проверка подлинности – Проверка подлинности Windows - Нажмите кнопку «соединить».
Management Studio подключится к SQL Server и откроется основное окно программы:
Настоятельно рекомендуем изучить элемент программы под названием обозреватель объектов. Он позволяет работать с всеми структурными элементами баз данных на сервере через интерфейс похожий на проводник Windows.
Создать новый запрос можно если кликнуть на кнопке «Создать запрос». Запрос будет создан для текущей таблицы, которая указана в выпадающем списке сверху, в данный момент master.
Если кликнуть по кнопке «создать запрос» несколько раз, то откроется несколько вкладок, как на скрине. Для каждого из них можно поменять текущую таблицу с помощью выпадающего списка.
Под полем редактора запросов располагается поле результатов. Там будут показываться результаты выполнения запроса:

Вот и все. Остальному можно научиться самостоятельно в процессе работы.
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).
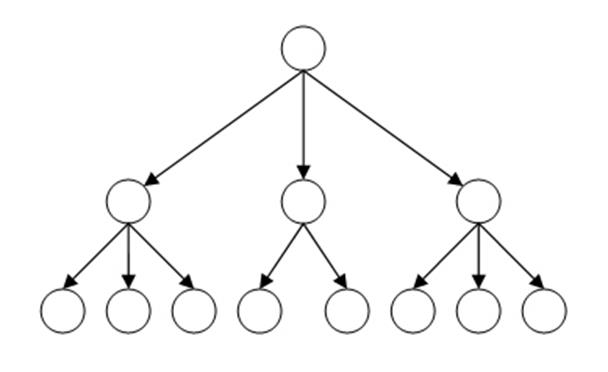
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
MySQL

Мне нравится39Не нравится14
MySQL – бесплатная реляционная система управления базами данных. Разработку и поддержку MySQL осуществляет компания Oracle. MySQL широкое распространение получила в интернете, как система хранения данных у сайтов, иными словами, подавляющее большинство сайтов хранят свои данные в базе MySQL. Поэтому не удивительно, что MySQL занимает лидирующую строчку нашего рейтинга.
В рейтинге Stack Overflow MySQL занимает первое место, т.е. программисты больше всего задают вопросы, связанные именно с MySQL.
Во всех остальных рейтингах MySQL уверенно занимает вторую строчку, и это один из самых стабильных результатов среди всех наших сегодняшних участников. Именно поэтому MySQL и занимает первую строчку рейтинга самой популярной СУБД.
Классификации СУБД
Существует несколько признаков, по которым можно классифицировать СУБД.
СУБД по модели данных бывают:
- Иерархические СУБД
- Сетевые СУБД
- Реляционные СУБД
- Объектно-ориентированные СУБД
- Объектно-реляционные СУБД
В настоящее время в серьезных проекта используются 2 последних типа.
СУБД по степени распределённости
- Локальные (СУБД размещается только на одном компьютере)
- Распределённые (части СУБД могут размещаться на 2-х и более компьютерах).
По способу доступа к БД
Файл-серверные СУБД
В них файлы с данными расположены централизованно на специальном файл-сервере. СУБД же должны быть расположены на каждом клиенте (рабочей станции). Доступ СУБД к данным производится посредством локальной сети. Поддержка синхронизации чтений и обновлений осуществляется за счет временных блокировок затребованных файлов.
Плюсом этой архитектуры можно назвать низкую нагрузку на файловый сервер.
К минусам же: высокая загрузка трафиком локальной сети; сложность или невозможность централизованного управления; нельзя обеспечить такие важные характеристики как надёжность, доступность и безопасность. Файл-серверные СУБД используют в локальных приложениях; в системах с малой интенсивностью обработки данных и небольшими пиковыми нагрузками на базу данных.
Сейчас её при создании крупной информационной системы не используют.
Примеры файл-серверных СУБД:
- dBase,
- FoxPro,
- Microsoft Access,
- Paradox,
- Visual FoxPro.
Клиент-серверные СУБД
Клиент-серверная СУБД расположена на сервере вместе с базой данных и осуществляет доступ к БД исключительно в монопольном режиме. Все запросы на обработку данных клиентских приложений и станций обрабатываются централизованно.
Недостатком такого типа СУБД можно назвать повышенные требования к серверу.
Достоинствами: более низкую загрузку локальной сети; преимущества централизованного управления; поддержку высокой надёжности, доступности и безопасности.
Примеры клиент-серверных СУБД:
- Caché,
- Firebird,
- IBM DB2,
- Informix,
- Interbase,
- MS SQL Server,
- MySQL, Oracle,
- PostgreSQL,
- Sybase Adaptive Server Enterprise,
- ЛИНТЕР.
Встраиваемые СУБД
Это вид СУБД, который может выступать лишь в качестве составной части определенного программного комплекса, без необходимости процедуры отдельной установки. Такой вид СУБД может быть использован для локального хранения данных своего приложения и не рассчитан на коллективное использование в компьютерной сети. Физически же это зачастую реализуется в виде подключаемой библиотеки. Со стороны приложения доступ к данным происходит посредством SQL-запросов либо через специальный программный интерфейс.
Примеры встраиваемых СУБД:
- Firebird Embedded,
- BerkeleyDB,
- Microsoft SQL Server Compact,
- OpenEdge,
- SQLite,
- ЛИНТЕР.
Для рассмотрения лишь части основных возможностей и внутреннего устройства любой СУБД требуется один или несколько отдельных учебных курсов.
Колоночные
Атомарная единица таких БД — колонка таблицы. Данные сохраняются столбец за столбцом, что делает колоночные запросы очень эффективными, и, поскольку данные в каждой колонке однородны, это позволяет лучше сжимать данные.
Использование
В тех случаях, когда удобно делать запросы к подмножеству столбцов (оно не обязательно должно быть одинаковым каждый раз!). Колоночные БД обрабатывают такие запросы очень быстро, так как читают только конкретные колонки (в то время как строчные БД должны читать строки полностью).
В науке о данных часто бывает, что каждая колонка представляет определенную характеристику. Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:
Cassandra.
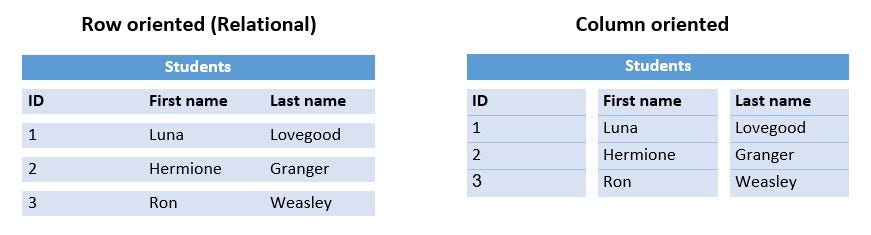
Строчная и колоночная базы данных
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели. Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц. Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц). Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога. Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов. Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel). Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация. В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы. Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно. Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение. А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой. Что это за связи? Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации. В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными. Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов. В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот! Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Это интересно: Трудовая книжка
Что такое схемы базы данных?
Когда дело доходит до выбора базы данных, одна из вещей, о которой вы должны подумать, — это форма ваших данных, модель, которой они будут следовать, и то, как сформированные отношения помогут нам при разработке схемы.
Схема базы данных — это план или архитектура того, как будут выглядеть наши данные. Он не содержит самих данных, а вместо этого описывает форму данных и то, как они могут быть связаны с другими таблицами или моделями. Запись в нашей базе данных будет экземпляром схемы базы данных. Он будет содержать все свойства, описанные в схеме.
Думайте о схеме базы данных как о типе структуры данных. Он представляет собой структуру и структуру содержимого данных организации.
Схема базы данных будет включать:
- Все важные или важные данные
- Единое форматирование для всех записей данных
- Уникальные ключи для всех записей и объектов базы данных
- Каждый столбец в таблице имеет имя и тип данных.
Размер и сложность схемы вашей базы данных зависит от размера вашего проекта. Визуальный стиль схемы базы данных позволяет программистам правильно структурировать базу данных и ее взаимосвязи, прежде чем переходить к коду. Процесс планирования дизайна базы данных называется моделированием данных.
Схемы важны для проектирования систем управления базами данных (СУБД) или систем управления реляционными базами данных (СУБД). СУБД — это программное обеспечение, которое хранит и извлекает пользовательские данные безопасным способом в соответствии с концепцией ACID.
Во многих компаниях ответственность за проектирование базы данных и СУБД обычно ложится на роль администратора базы данных (DBA). Администраторы баз данных несут ответственность за обеспечение беспрепятственного доступа к информации аналитикам данных и пользователям баз данных. Они работают вместе с командами менеджеров для планирования и безопасного управления базой данных организации.
Каким требованиям должна отвечать современная СУБД?
Информационное хранилище должно постоянно пополняться новыми данными в соответствии с ритмом жизни компании, это же касается и формирование новых категорий учета.
При этом вносить информацию должен иметь возможность любой новый сотрудник. То же касается и обслуживания данной инфраструктуры со стороны системного администратора, формирования новых выборок данных со стороны аналитиков с разным уровнем допуска к информации и с разными профилями анализируемых данных.
Необходимо отметить, что количество информации увеличивается не только в объеме, но и качественно. В результате появляется необходимость одновременной работы с ней нескольких экспертов. Кроме того, появляется возможность привлечения специализированных экспертов для выполнения сложных процедур анализа данных (Data mining Интеллектуальный анализ данных). Сегодня не только для формирования будущей стратегии, но и для выполнения повседневных задач все большее значение имеет прогнозная аналитика, которая для формирования верного вектора развития использует объективные, а не субъективные данные.
Помимо этого единая база данных упрощает формирования отчетности как отдельным подразделениям компании, так и всей компании в целом для подачи документов в государственные инстанции или их предоставления для ознакомления внешним экспертным комиссиям. Единая база позволяет в автоматическом режиме обновлять документацию, относящуюся к нормативно-справочной информации (НСИ). Дополнительно общая база данных позволяет оперировать информацией в своеобразной унифицированной форме, делая процедуры анализа информации более единообразными в рамках компании.
Еще одним плюсом от единого подхода к хранению информации является гораздо более простая процедура резервирования, снижение времени простоя после сбоя, обеспечение безопасности данных в плане распределения прав доступа, более прозрачная процедура миграции на новые версии программного и аппаратного обеспечения.
Индексы
Индексы – основной способ ускорения работы баз данных. Чтобы найти нужную запись, необходимо сканировать всю таблицу, на что уходит большое количество времени.
Идея индексов состоит в том, чтобы создать для столбца копию, которая постоянно будет поддерживаться в отсортированном состоянии. Это позволяет очень быстро осуществлять поиск по такому столбцу, так, как заранее известно, где необходимо искать значение.
Добавление или удаление записи требует дополнительного времени на сортировку столбца, кроме того, создание копии увеличивает объем памяти, необходимый для размещения таблицы на жестком диске.
Существует несколько видов индексов:
- Первичный ключ – главный индекс таблицы. В таблице может быть только один первичный ключ, и все значения такого индекса должны отличаться друг от друга, являться уникальными в пределах одного столбца.
- Обычный индекс – таких индексов может быть несколько.
- Уникальный индекс – уникальных индексов также может быть несколько, на значения индекса не должны повторяться.
- Полнотекстовый индекс – специальный вид индекса для столбцов типа TEXT, позволяющий производить полнотекстовый поиск.
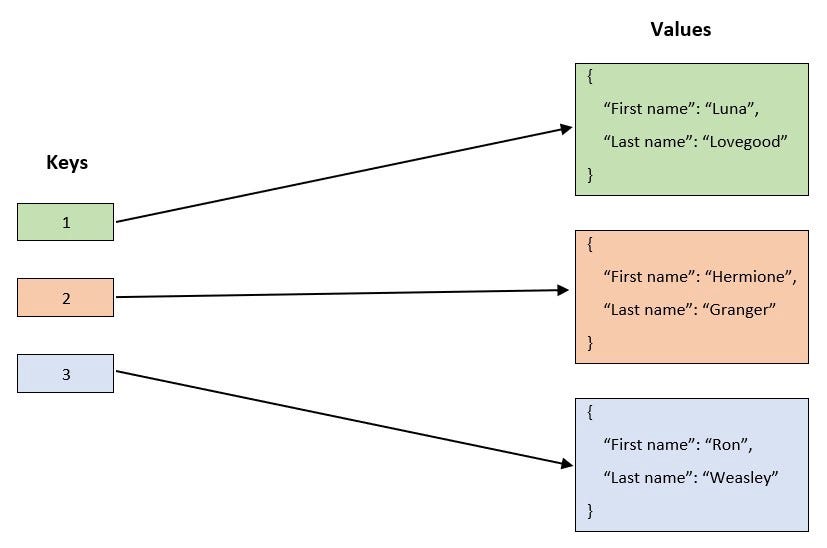
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached