Sql команды
Содержание:
- NoSQL как альтернатива традиционным БД
- Встраивание SQL
- Зачем мне изучать SQL, если я занимаюсь данными?
- Practical skills of SQL language
- Что такое СУБД
- MS SQL Server
- Классификация Structured Query Language
- SQL Справочник
- Команды языка управления транзакциями
- Настройка и работа в Management Studio
- Создаём базу данных
- Создание и настройка базы данных
- Скажите нет грубой силе
- Какие реляционные БД популярны в веб-разработке
NoSQL как альтернатива традиционным БД
Мир меняется. В ходе цифровой трансформации перед бизнесом встают новые задачи. Компании решают их с помощью новых баз данных. Во-первых, чтобы не перегружать имеющиеся, во-вторых, не для всех современных задач подходят классические реляционные СУБД.
И вот, в начале 2000-х появились нереляционные базы. Помимо решения новых задач, их разработчики сделали упор на исправление главных недостатков реляционных баз — проблем с гибкостью, низкой производительностью и масштабируемостью.
В NoSQL нет таких понятий, как строки, столбцы, таблицы и их соединения. Данные в нереляционных базах хранятся как объекты с произвольными атрибутами: это могут быть пары «ключ-значение», документы в формате JSON, графы и так далее.
Встраивание SQL
В этом разделе мы опишем в общих чертах как SQL может быть встроен в конечный язык (например в C). Есть две главных причины, по которым мы хотим пользоваться SQL из конечного языка:
-
Существуют запросы, которые нельзя сформулировать на чистом SQL(т.е. рекурсивные запросы). Чтобы выполнить такие запросы, нам необходим
конечный язык, обладающий большей мощностью выразительности, чем
SQL. -
Просто нам необходим доступ к базе данных из другого приложения, которое
написано на конечном языке (например, система бронирования билетов с
графическим интерфейсом пользователя написана на C и информация об оставшихся билетах
хранится в базе данных, которую можно получить с помощью встроенного SQL).
Программа, использующая встроенный SQL в конечном языке, состоит из выражений конечного языка и выражений встроенного SQL
(ESQL). Каждое выражение ESQL начинается с ключевых слов EXEC SQL. Выражения ESQL преобразуются в выражения на конечном языке
с помощью прекомпилятора (который обычно вставляет вызовы библиотечных процедур, которые
выполняют различные команды SQL).
Если мы посмотрим на все примеры из мы поймём, что результатом запроса очень часто являются множество
кортежей. Большинство конечных языков не предназначено для работы с множествами,
поэтому нам нужен механизм доступа к каждому отдельному кортежу из множества
кортежей, возвращаемого выражением SELECT. Этот механизм можно предоставить,
определив курсор. После этого, мы можем использовать команду FETCH для получения
кортежа и установления курсора на следующий кортеж.
Подробней про встраивание SQL смотри у
[],
[],
or
[].
| Предыдущий | Начало | Следующий |
| Операции в реляционной модели данных | В начало главы | Архитектура |
Спонсоры:
Хостинг:
Maxim ChirkovДобавить, Поддержать, Вебмастеру
Зачем мне изучать SQL, если я занимаюсь данными?
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).
Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. SQL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
- Он довольно прост в изучении, даже для новичков. Рост знаний и навыков происходит довольно быстро, и вы в кратчайшие сроки научитесь писать запросы.
- Изучение SQL подчиняется принципу «однажды изученное может применяться повсюду», поэтому это отличное вложение вашего времени и сил!
- Это отличное дополнение к языкам программирования. В некоторых случаях писать запрос даже предпочтительнее, чем писать код, потому что он более эффективен!
- …
И чего же ты все еще ждешь?
Practical skills of SQL language
This site will help everyone to gain or improve skills in building
SQL Data Manipulation Language statements. To train You will have to build yourself
the SQL statements for retrieval or modification of specific data required in the exercises.
When Your query is incorrect, You will be able to see rows returned by the correct
query along with that returned by Your query. Furthermore, you may execute arbitrary
DML statements on available databases by setting the «Without checking» option. There are
five levels of difficulty (from 1 to 5), You may see it in second column of
exercises list. We propose the exercises on retrieving data (SELECT statement) and
the exercises on modifying data (INSERT, UPDATE, DELETE, and MERGE statements). Your success in the solving the exercises are shown by a rating of participants.
As this takes place, there are three stages:
the first one (first 5 exercises) is performed without time control for an individual
exercise, the second one (begins with the exercise #6) controls time for completion of each
task. At the third stage which refers to optimizing and begins with exercise #139, it is required not only to solve an exercise correctly, but also time of execution of inquiry should be commensurable with time of execution of the author’s solution.
Exercises of the first stage are available without registration and may be solved
in any order You like. The solution of the rest of exercises requires registration.
REGISTRATION IS FREE as this for all other services of the site. In the third column of exercises list You
will be able to see («OK») notes with the numbers of done exercises, but that
is available only to the registered users. In fact, that is the main reason for registration.
If You would like to visit our web site again, You won’t have to recollect which
exercises You have done already and which You haven’t. If You don’t want to register,
You may enter as a guest, but in that case Your results won’t
be traced by the system. Registered users also may discuss the solutions to exercises in our forum.
NOTE: The query stated incorrectly may return the «correct» data on a current state of database.
For this reason You should not be surprised if the results of incorrect query are
coincide with the results of right one with Your query is estimated as incorrect by the Verifying system.
NOTE: Your browser should support Cookies and Javascript to provide correct usage of this site. If you use content filter, it should allow opening child windows to explore help pages.
Что такое СУБД
Мы выяснили, что база данных — это упорядоченный набор информации, однако тут возникает другой вопрос, а как вся эта информация выглядит физически на компьютере?
А представлена она, конечно же, в виде файлов, сформированных в специальном формате.
Отсюда возникает следующий вопрос, как создать такой файл и открыть его с целью просмотра всей информации, иными словами, как создать базу данных и управлять всей информацией в базе данных?
Для этого должен быть какой-то инструмент, т.е. специальная программа. И такой программой выступает СУБД – это система управления базами данных, сокращенно СУБД.
По своим возможностям и популярности можно выделить следующие СУБД:
- Microsoft SQL Server;
- Oracle Database;
- MySQL;
- PostgreSQL.
MS SQL Server
MS SQL Server is a Relational Database Management System developed by Microsoft Inc. Its primary query languages are −
- T-SQL
- ANSI SQL
History
-
1987 — Sybase releases SQL Server for UNIX.
-
1988 — Microsoft, Sybase, and Aston-Tate port SQL Server to OS/2.
-
1989 — Microsoft, Sybase, and Aston-Tate release SQL Server 1.0 for OS/2.
-
1990 — SQL Server 1.1 is released with support for Windows 3.0 clients.
-
Aston — Tate drops out of SQL Server development.
-
2000 — Microsoft releases SQL Server 2000.
-
2001 — Microsoft releases XML for SQL Server Web Release 1 (download).
-
2002 — Microsoft releases SQLXML 2.0 (renamed from XML for SQL Server).
-
2002 — Microsoft releases SQLXML 3.0.
-
2005 — Microsoft releases SQL Server 2005 on November 7th, 2005.
Features
- High Performance
- High Availability
- Database mirroring
- Database snapshots
- CLR integration
- Service Broker
- DDL triggers
- Ranking functions
- Row version-based isolation levels
- XML integration
- TRY…CATCH
- Database Mail
Классификация Structured Query Language
SQL запросы можно разделить на следующие виды:
DDL
Язык определения данных – DDL (аббревиатура Data Definition Language). Основная задача – формирование БД и представление ее структуры. Они диктуют правила (вид) размещения данных в БД.
К DDL относятся SQL Queries:
- ALTER – применяется для добавления, удаления, изменения столбцов в ранее созданной таблице (ALTER TABLE);
- COLLATE – используется, чтобы определить, по каким параметрам будет сортироваться БД, столбцы либо операции приведения условий сортировки, если используется выражение строки символов;
- CREATE – позволяет создать новую БД;
- DROP – позволяет удалять любые данные (в том числе и таблицы) из БД. Добавляется приставкой к нужному элементу (DROP TABLE – удалить таблицу);
- DISABLE TRIGGER – выполняет функции отключения триггеров;
- ENABLE TRIGGER – выполняет включение триггеров DML, DDL или logon;
- RENAME – используется для переименования таблицы, которая создана пользователем;
- UPDATE STATISTICS – выполняет функции обновления статистики оптимизации запросов как для таблиц, так и для индексированных представлений;
- TRUNCATE – удаляет все значения из таблицы, но ее саму оставляет.
DML
Язык манипулирования данными – DML (сокращенное от Data Manipulation Language). К нему относятся команды, при использовании которых осуществляются определенные манипуляции с данными.
Основная часть MS SQL запросов относится именно к DML. В их число входят:
- BULK INSERT – импортирует файл с данными в таблицу либо представляет БД в том формате, который указал пользователь;
- SELECT – выводит нужные данные из определенной таблицы;
- DELETE – выполняет удаление указанной строки (с помощью оператора WHERE) из определенной таблицы в БД,
- UPDATE – позволяет вносить правки или добавлять новую информацию в сделанные ранее записи. Включает: таблицу с полем, в котором необходимо внести изменения, запись нового значения, для обозначения места в выбранной таблице применяется WHERE;
- INSERT – в имеющуюся БД добавляет новые записи;
- UPDATETEXT – выполняет обновление (изменение) существующих полей типа text, ntext или image;
- MERGE – в целевой таблице выполняет операции вставок, обновлений либо удалений, основанные на результатах соединения с данными исходной;
- WRITETEXT – выполняет обновление существующих столбцов, имеющих тип text, ntext или image, в режиме онлайн, с минимальным использованием журнала. Данная инструкция перезаписывает в столбцах, для которых используется, любые данные. Но ее нельзя применять в представлениях для столбцов вышеуказанных типов;
- READTEXT – производит считывание значений text, ntext или image из соответствующих столбцов. Процесс запускается с указанных позиций и длится для обозначенного числа байтов.
Без них не обойтись, когда необходимо:
- внести изменения в ранее занесенные данные;
- получить данные из сформированной ранее БД;
- сохранить, обновить, удалить данные из БД.
DCL
Языком управления данными является DCL (расшифровывается – Data Control Language). В нем объединены запросы вместе с командами, которые касаются прав, разрешений и прочих настроек систем управления БД.
К их числу относятся:
- GRANT – применяется для распределения пользователям привилегий;
- REVOKE – выполняет функции отмены привилегий,
- DENY – применяется для запрещения разрешений участникам. Наделен приоритетом над иными разрешениями, однако не может использоваться к владельцам либо членам с правами sysadmin.
TCL
Языком управления транзакциями является TCL (аббревиатура от Transaction Control Language). TCL-конструкции используются для управления изменениями, происходящими благодаря применению DML-команд. Они дают возможность объединять в наборы транзакций запросы DML.
К ним относятся:
- BEGIN – позволяет выполнять инструкции T-SQL;
- COMMIT – выполняет фиксацию транзакции;
- ROLLBACK – выполняет откат транзакции.
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Команды языка управления транзакциями
Команды языка управления транзакциями ( TCL (Тгаnsасtiоn Соntrol Language) ) команды позволяют определить исход транзакции.
Команды управления транзакциями управляют изменениями в базе данных, которые осуществляются командами манипулирования данными.Транзакция (или логическая единица работы) – неделимая с точки зрения воздействия на базу данных последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.COMMIT — заканчивает («подтверждает») текущую транзакцию и делает постоянными (сохраняет в базе данных) изменения, осуществленные этой транзакцией. Также стирает точки сохранения этой транзакции и освобождает ее блокировки. Можно также использовать эту команду для того, чтобы вручную подтвердить сомнительную распределенную транзакцию.ROLLBACK — выполняет откат транзакции, т.е. отменяет все изменения, сделанные в текущей транзакции. Можно также использовать эту команду для того, чтобы вручную отменить работу, проделанную сомнительной распределенной транзакцией.
Понятие транзакции имеет непосредственную связь с понятием целостности базы данных. Очень часто база данных может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Например, невозможно принять сотрудника в отдел, название и код которого отсутствует в базе данных.
В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии базы данных и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и база данных остается в таком состоянии, в котором находилась к моменту начала транзакции, т.е. в целостном состоянии.
В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей, т.е., если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т.е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Настройка и работа в Management Studio
- Найдите Management Studio в меню «ПУСК» и запустите.
- В открывшемся окне соединения с сервером выберите:
В поле тип сервиса – Ядро СУБД
В поле имя сервера – имя сервера, которое вы указали при установке
Проверка подлинности – Проверка подлинности Windows - Нажмите кнопку «соединить».
Management Studio подключится к SQL Server и откроется основное окно программы:
Настоятельно рекомендуем изучить элемент программы под названием обозреватель объектов. Он позволяет работать с всеми структурными элементами баз данных на сервере через интерфейс похожий на проводник Windows.
Создать новый запрос можно если кликнуть на кнопке «Создать запрос». Запрос будет создан для текущей таблицы, которая указана в выпадающем списке сверху, в данный момент master.
Если кликнуть по кнопке «создать запрос» несколько раз, то откроется несколько вкладок, как на скрине. Для каждого из них можно поменять текущую таблицу с помощью выпадающего списка.
Под полем редактора запросов располагается поле результатов. Там будут показываться результаты выполнения запроса:

Вот и все. Остальному можно научиться самостоятельно в процессе работы.
Создаём базу данных
Чтобы заполнять базу данных чем угодно, её сначала нужно создать:
Мы специально выделяем большими буквами SQL-команды, но сейчас базы понимают команды и из маленьких букв (а раньше не могли). Поэтому пишите как вам удобно.
Эта команда создаст базу с выбранным именем, чтобы дальше можно было с ней работать. Переименовать базу данных нельзя — только удалить и создать заново, имейте это в виду.
Чтобы посмотреть, сколько баз данных у вас есть, наберите команду
Когда определитесь, с какой базой будете работать, наберите эту команду — она покажет системе, что всё дальше будет относиться к ней:
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
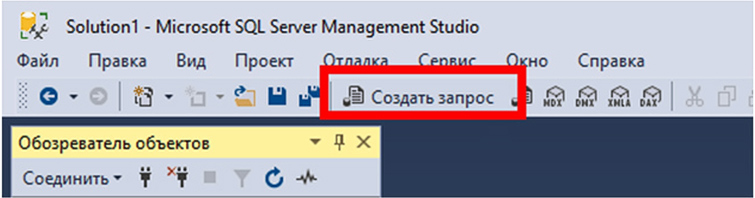
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library.
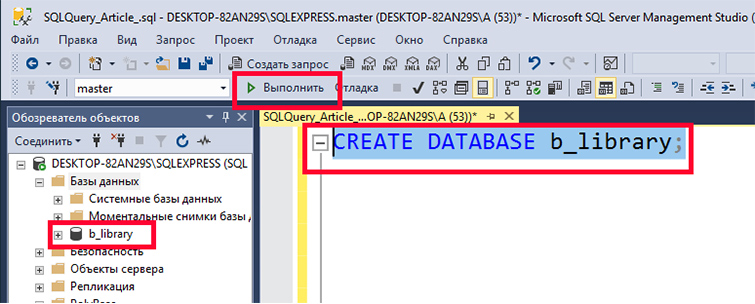
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors ( AuthorId INT IDENTITY (1, 1) NOT NULL, AuthorFirstName NVARCHAR (20) NOT NULL, AuthorLastName NVARCHAR (20) NOT NULL, AuthorAge INT NOT NULL );
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES (‘Александр’, ‘Пушкин’, ’37’), (‘Сергей’, ‘Есенин’, ’30’), (‘Джек’, ‘Лондон’, ’40’), (‘Шота’, ‘Руставели’, ’44’), (‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
SELECT * FROM tAuthors;
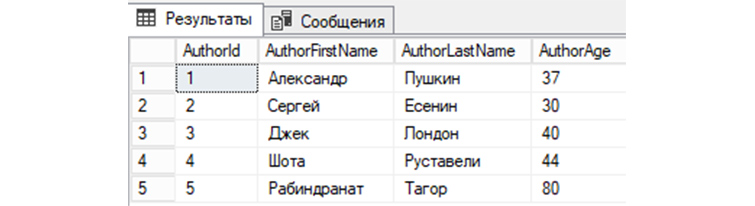
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Скажите нет грубой силе
Этот последний совет на самом деле означает, что вы не должны слишком сильно ограничивать запрос, потому что это может повлиять на его производительность. Это особенно верно для объединений и для предложения .
Когда вы объединяете две таблицы, может быть важно рассмотреть порядок объединения таблиц. Если вы заметили, что одна таблица значительно больше другой, вы можете переписать свой запрос так, чтобы самая большая таблица была помещена последней в объединении
Избыточные условия для объединений
Когда вы добавляете слишком много условий для объединений, вы, по сути, предписываете SQL выбрать определенный путь. Может быть, однако, что этот путь не всегда более эффективен.
Предложение было первоначально добавлено в SQL, потому что ключевое слово не могло использоваться с агрегатными функциями. обычно используется с предложением , чтобы ограничить группы возвращаемых строк только теми, которые соответствуют определенным условиям. Однако, если вы используете это предложение в своем запросе, индекс не используется, который, как вы уже знаете, что может привести к запросу, который будет не реально выполнить.
Если вы ищете альтернативу, подумайте об использовании предложения . Рассмотрим следующие запросы:
SELECT state, COUNT(*) FROM Drivers WHERE state IN ('GA', 'TX') GROUP BY state ORDER BY state
SELECT state, COUNT(*) FROM Drivers GROUP BY state HAVING state IN ('GA', 'TX') ORDER BY state
В первом запросе используется предложение , чтобы ограничить количество строк, которые нужно суммировать, тогда как второй запрос суммирует все строки в таблице, а затем использует для отбрасывания вычисленных сумм. В таких случаях альтернатива с предложением , очевидно, лучше, поскольку вы не тратите никаких ресурсов.
Вы видите, что здесь речь идет не о ограничении результатов запроса, а об ограничении промежуточного количества записей в запросе.
Обратите внимание, что разница между этими двумя предложениями заключается в том, что оператор вводит условие для отдельных строк, тогда как оператор вводит условие агрегирования или повторных выборов, в которых один результат, такой как , , , … был создан из нескольких строк. Как видите, оценка качества, запись и переписывание запросов –непростая задача, если учесть, что они должны быть максимально эффективными
Избегание анти-шаблонов и использование альтернативных вариантов в написании запросов также являются частью вашей заботы при написании очередей, которые можно запускать в базах данных в профессиональной среде
Как видите, оценка качества, запись и переписывание запросов –непростая задача, если учесть, что они должны быть максимально эффективными. Избегание анти-шаблонов и использование альтернативных вариантов в написании запросов также являются частью вашей заботы при написании очередей, которые можно запускать в базах данных в профессиональной среде.
Этот список был всего лишь небольшим обзором некоторых анти-шаблонов и советов, которые, надеюсь, помогут новичкам. Если вы хотите получить представление о том, что более старшие разработчики считают наиболее частыми антишаблонами, ознакомьтесь с этим обсуждением.
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.