«яндекс» научил «алису» читать с выражением электронные книги
Содержание:
- Введение
- Подсистема «Показатели объектов»
- Использование
- Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
- Пример на Python
- Какое оборудование нужно для начала работы?
- Автокликер для 1С
- Для чего это нужно
- Особенности «Алисы» как чтеца книг
- Если вам позвонили из Yandex. Эти загадочные токены
- Как подключаться к сервисам Яндекса
- Бесплатный GPS-трекинг Промо
- Аналитика по телефонным звонкам для бизнеса
- Регистрация в «Облаке»
- Настраиваем доступ
- Работа с файлами телефонных звонков
- Funny voice
- StartManager 1.4 — Развитие альтернативного стартера Промо
- Usage
- Интеграция 1С с ГИИС ДМДК
Введение
Технология синтеза речи позволяет переводить текст в речь (звуковой файл). Задача актуальна для озвучивания динамически обновляемой информации или быстро меняющихся данных, таких как остаток товаров на складе, репертуар кинотеатров и так далее. Технология синтеза речи Яндекса построена на базе скрытых марковских моделей (HMM). За счет применения статистического подхода в акустическом моделировании удается достичь естественных плавных интонаций. Технология позволяет достаточно быстро создавать новые голоса и синтезировать различные эмоции.
Синтез речи Яндекса позволяет выбрать:
- мужской или женский голос для озвучивания;
- эмоции: добрый, злой, нейтральный голос.
Подсистема «Показатели объектов»
Если вашим пользователям нужно вывести в динамический список разные показатели, которые нельзя напрямую получить из таблиц ссылочных объектов, и вы не хотите изменять структуру справочников или документов — тогда эта подсистема для вас. С помощью нее вы сможете в пользовательском режиме создать свой показатель, который будет рассчитываться по формуле или с помощью запроса. Этот показатель вы сможете вывести в динамический список, как любую другую характеристику объекта. Также можно будет настроить отбор или условное оформление с использованием созданного показателя.
2 стартмани
Использование
Создание сервиса / Аутентификация
С аккаунтом на Яндексе (OAuth-токен)
use Panda\Yandex\SpeechKitSdk;
try {
/*
* OAuth-токен
* ID каталога
*/
$cloud = new SpeechKitSdk\Cloud('oAuthToken', 'folderId');
} catch (SpeechKitSdk\Exception\ClientException | TypeError $e) {
echo $e->getMessage();
}
С использованием сервисного аккаунта / федеративного пользователя (IAM-токен)
use Panda\Yandex\SpeechKitSdk;
try {
// IAM-токен
$cloud = new SpeechKitSdk\Cloud('iamToken');
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
С использованием сервисного аккаунта (API-ключ)
use Panda\Yandex\SpeechKitSdk;
try {
// API-ключ
$cloud = SpeechKitSdk\Cloud::createApi('apiKey');
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
Распознавание коротких аудио
Создание запроса
use Panda\Yandex\SpeechKitSdk;
try {
// Аудио-файл
$recognize = new SpeechKitSdk\Recognize('greeting_developer.ogg');
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
Установка параметров
use Panda\Yandex\SpeechKitSdk;
try {
// Аудио-файл
$recognize->setFile('greeting_developer.raw');
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
// Язык
$recognize->setLang(SpeechKitSdk\Lang::RU_RU)
// Языковая модель распознавания
->setTopic(SpeechKitSdk\Topic\Ru::GENERAL_RC)
// Фильтр ненормативной лексики
->setProfanityFilter(SpeechKitSdk\ProfanityFilter::FALSE)
// Формат аудио
->setFormat(SpeechKitSdk\Format::LPCM)
// Частота дискретизации аудио
->setSampleRate(SpeechKitSdk\SampleRate::KHZ_48);
Выполнение запроса
use Panda\Yandex\SpeechKitSdk;
try {
print_r($cloud->request($recognize));
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
Синтез речи
Создание запроса
use Panda\Yandex\SpeechKitSdk;
try {
// Текст, который нужно озвучить
$synthesize= new SpeechKitSdk\Synthesize('Привет, разработчик!');
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
Установка параметров
use Panda\Yandex\SpeechKitSdk;
try {
// Текст, который нужно озвучить
$synthesize->setText('Привет, разработчик!');
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
// Текст, который нужно озвучить, в формате SSML
$synthesize->setSsml('<speak>Привет<break time="1s"/>разработчик!</speak>')
// Язык
->setLang(SpeechKitSdk\Lang::RU_RU)
// Желаемый голос
->setVoice(SpeechKitSdk\Voice\Ru::OKSANA);
try {
// Желаемый голос
$synthesize->setVoice(SpeechKitSdk\Voice\Ru::random());
} catch (SpeechKitSdk\Exception\ClientException | ArgumentCountError $e) {
echo $e->getMessage();
}
// Эмоциональная окраска голоса
$synthesize->setEmotion(SpeechKitSdk\Emotion::GOOD)
// Скорость (темп)
->setSpeed(SpeechKitSdk\Speed::AVERAGE)
// Формат аудио
->setFormat(SpeechKitSdk\Format::LPCM)
// Частота дискретизации аудио
->setSampleRate(SpeechKitSdk\SampleRate::KHZ_48);
Выполнение запроса
use Panda\Yandex\SpeechKitSdk;
try {
file_put_contents('greeting_developer.ogg', $cloud->request($synthesize));
} catch (SpeechKitSdk\Exception\ClientException $e) {
echo $e->getMessage();
}
Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Simple WMS Client – это визуальный конструктор мобильного клиента для терминала сбора данных(ТСД) или обычного телефона на Android. Приложение работает в онлайн режиме через интернет или WI-FI, постоянно общаясь с базой посредством http-запросов (вариант для 1С-клиента общается с 1С напрямую как обычный клиент). Можно создавать любые конфигурации мобильного клиента с помощью конструктора и обработчиков на языке 1С (НЕ мобильная платформа). Вся логика приложения и интеграции содержится в обработчиках на стороне 1С. Это очень простой способ создать и развернуть клиентскую часть для WMS системы или для любой другой конфигурации 1С (УТ, УПП, ERP, самописной) с минимумом программирования. Например, можно добавить в учетную систему адресное хранение, учет оборудования и любые другие задачи. Приложение умеет работать не только со штрих-кодами, но и с распознаванием голоса от Google. Это бесплатная и открытая система, не требующая обучения, с возможностью быстро получить результат.
5 стартмани
Пример на Python
Код на Python 3.8 для озвучивания текста. Для примера я взял текст А.С. Пушкина из Повестей Белкина, потому что он уже в public domain и на него не распространяются авторские права. Текст я сохранил в кодировке и немного почистил от сносок. Так же оставил только русские переводы французских фраз, так как SpeechKit не поддерживает французский язык.
Я заметил, что несмотря на то, что поддерживается синтез звука по отрывкам текста длинной до 5000 тыс знаков, лучше работает с небольшими кусками. Поэтому я поделил текст на отдельные предложения и озвучивал их.
У SpeechKit есть мужские и женские голоса и теоретически, женские реплики можно было бы озвучить отдельно другим голосом, но для этого пришлось бы дополнительно разметить текст, а я хотел сделать максимально простой пример.
Размер выбранного произведения — 22 тыс. знаков. Озвучивание его при помощи премиального голоса Филипп обошлось в 27₽.
Этот скрипт побьет текст на предложения, озвучит их в SpeechKit и потом склеит результат при помощи .
Как установить ffmpeg на ваш компьютер можно посмотреть тут.
Весь код примера на гитхаб.
Кстати если вам хочется получить вместо Ogg Opus файла обычный MP3, то сделать это можно при помощи того же .
Для этого нужно выполнить следующую команду
ffmpeg -i out/output.ogg -acodec libmp3lame out/output.mp3
После этого в терминале вы увидите примерно следющее
ffmpeg version 4.3.1 Copyright (c) 2000-2020 the FFmpeg developers built with Apple clang version 12.0.0 (clang-1200.0.32.28) configuration: --prefix=/usr/local/Cellar/ffmpeg/4.3.1_9 --enable-shared --enable-pthreads --enable-version3 --enable-avresample --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gnutls --enable-gpl --enable-libaom --enable-libbluray --enable-libdav1d --enable-libmp3lame --enable-libopus --enable-librav1e --enable-librubberband --enable-libsnappy --enable-libsrt --enable-libtesseract --enable-libtheora --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-lzma --enable-libfontconfig --enable-libfreetype --enable-frei0r --enable-libass --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-librtmp --enable-libspeex --enable-libsoxr --enable-videotoolbox --enable-libzmq --enable-libzimg --disable-libjack --disable-indev=jack libavutil 56. 51.100 / 56. 51.100 libavcodec 58. 91.100 / 58. 91.100 libavformat 58. 45.100 / 58. 45.100 libavdevice 58. 10.100 / 58. 10.100 libavfilter 7. 85.100 / 7. 85.100 libavresample 4. 0. 0 / 4. 0. 0 libswscale 5. 7.100 / 5. 7.100 libswresample 3. 7.100 / 3. 7.100 libpostproc 55. 7.100 / 55. 7.100Input #0, ogg, from 'out/output.ogg': Duration: 00:25:40.29, start: 0.006500, bitrate: 85 kb/s Stream #0:0: Audio: opus, 48000 Hz, mono, fltp Metadata: encoder : Lavf57.56.100Stream mapping: Stream #0:0 -> #0:0 (opus (native) -> mp3 (libmp3lame))Press to stop, for helpOutput #0, mp3, to 'output.mp3': Metadata: TSSE : Lavf58.45.100 Stream #0:0: Audio: mp3 (libmp3lame), 48000 Hz, mono, fltp Metadata: encoder : Lavc58.91.100 libmp3lamesize= 12039kB time=00:25:40.29 bitrate= 64.0kbits/s speed=87.9x video:0kB audio:12039kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.001922%
Как видно наш исходный поток был пережат в mp3 с параметрами .
Удачных экспериментов.
Какое оборудование нужно для начала работы?
В первую очередь ориентируйтесь на окружающую обстановку, а затем модернизируйте оборудование по мере необходимости.
Когда Турман только начинала работать дома, она использовала оборудование для стриминга на Twitch, но быстро выяснилось, что оно не подходит под её задачи. Решением стал шкаф в спальне, который она застелила одеялами, чтобы создать импровизированную комнату для записи
Хотя с тех пор Турман переехала в специализированную студию и неоднократно модернизировала своё оборудование, она по-прежнему советует начинающим актёрам озвучивания в первую очередь обратить внимание на окружающую обстановку
Смит начинала с использования встроенного микрофона компьютера. Через несколько месяцев она перешла на USB-микрофон и стала получать первые оплачиваемые заказы — например, от Freedom Planet, — но она добавила: «Если бы я сделала это сегодня, уверена, что не прошла бы ни один кастинг». Впрочем, когда вы начинаете с нуля, принятие какого-то решения может казаться очень простым.
«Вы, конечно, можете начать с USB-микрофона, добавив к нему поп-фильтр, и записывать всё под одеялом и с любым программным обеспечением. А затем реинвестировать деньги в профессиональное оборудование по мере продвижения, когда поймёте, нравится ли вам всё это».
Эйми Смит, профессиональная актриса озвучивания
Актёрам озвучивания, работающим в домашней студии, необходимо правильное ПО и базовые навыки звукорежиссуры и редактирования, чтобы улучшить свои записи. Если с домашней установкой во время удалённой сессии записи что-то пойдёт не так и человек не сможет сам исправить проблему, это может оттолкнуть студию или режиссёра от найма актёра в будущем.
«У меня сердце замирает, когда я слышу, как актёры с домашними студиями говорят: „Я не очень силён в технических нюансах, ничего о них не знаю“. Тогда я спрашиваю: „Почему тогда у вас вообще есть домашняя студия? Если вы действительно не знаете, как работать с оборудованием, вам лучше не собирать ничего у себя дома“».
Кирсти Гиллмор, режиссёр озвучки
Эш Турман в своей нынешней работе использует программу для редактирования звука Adobe Audition, но начинала она с бесплатной Audacity, которая имеет ограниченную функциональность.
«Вы можете начать с бесплатной Audacity, чтобы понять, как работает редактирование и запись звука, а затем выбрать то программное обеспечение, которое вам больше подходит».
Эш Турман, актриса и режиссёр озвучивания
У Турман также есть опыт в непосредственной разработке игр. Создание собственных игр пригодилось для пополнения актёрского портфолио.
Автокликер для 1С
Внешняя обработка, запускаемая в обычном (неуправляемом) режиме для автоматизации действий пользователя (кликер). ActiveX компонента, используемая в обработке, получает события от клавиатуры и мыши по всей области экрана в любом приложении и транслирует их в 1С, получает информацию о процессах, текущем активном приложении, выбранном языке в текущем приложении, умеет сохранять снимки произвольной области экрана, активных окон, буфера обмена, а также, в режиме воспроизведения умеет активировать описанные выше события. Все методы и свойства компоненты доступны при непосредственной интеграции в 1С. Примеры обращения к компоненте представлены в открытом коде обработки.
1 стартмани
Для чего это нужно
Смысл такой: если нужно перевести аудиозапись в текст, можно это сделать очень быстро с помощью нейросетей. Яндекс в этом всяко преуспел, и мы теперь можем этим воспользоваться в своё удовольствие.
Если вы редактор или автор, вам нужно часто общаться с экспертами, чтобы получить необходимую информацию для своей работы. Можно всё конспектировать на ходу, а можно записать на диктофон и потом перевести в текст за 10 минут.
Если коллега вам оставил длинное голосовое сообщение, текст которого нужно разместить на сайте, то можно набрать всё руками или отдать эту задачу компьютеру.
Если вы студент и не хотите конспектировать лекции по гуманитарным наукам, запишите их на телефон, и нейронка переведёт их в текст. У вас будут самые полные лекции, и вся группа будет бегать за вами перед экзаменом.
В некоторых вебинарах или видео на YouTube есть классная информация, но каждый раз приходится их смотреть и перематывать, чтобы найти нужное. Выход простой: берём видео, вырезаем оттуда звук, отправляем в сервис распознавания и получаем готовый текст, с которым работать гораздо проще.
Особенности «Алисы» как чтеца книг
Пользователю «Читалки», решившему обратиться за услугами чтеца к «Алисе», доступен выбор скорости чтения и варианта озвучки – помимо привычной, есть версия с мужским голосом.
«Алиса» умеет запоминать место в каждой книге, на котором остановился хозяин, поэтому в следующий раз продолжит читать именно с него.
За озвучивание текста отвечает фирменная технология синтеза речи «Яндекса». Как рассказали CNews в компании, голосового помощника обучали на образцах речи дикторов. Это позволило добиться более естественного звучания – благодаря анализу фрагментов речи профессионалов «Алиса» учится правильно ставить ударение в словах, выдерживать паузы и выбирать интонации.
Если вам позвонили из Yandex. Эти загадочные токены
Возможно, распознавать и синтезировать речь вам так понравится, что однажды вам позвонит милая девушка из Yandex и поинтересуется, все ли вам понятно в работе сервиса.
Продолжайте изучать документацию, и тогда вы узнаете, например, что iam_token живет не более 12 часов.
Чтобы быть вежливым, как наш дворецкий, и не перегружать сервера на Yandex, мы не будем генерировать iam_token чаще (при желании теперь стало можно генерить токен при каждом запросе). Заведите себе блокнотик и карандашик для записи даты генерации. Шутка.
Ведь у нас есть Python. Создадим функцию генерации. Снова используем requests:
Вызовем функцию и положим результат в переменную:
Карандишик и блокнотик не пострадали, а у вас появилась полезная переменная xpires_iam_token.
Специально для вас по мотивам этого материала я написала маленький кусочек проекта виртуального дворецкого Butler. Звуковые эффекты входят в комплект 🙂
Как подключаться к сервисам Яндекса

В Яндекс.Облаке очень много сервисов, я в своей работе использовал только два:
-
Yandex Object Storage – для хранения звуковых файлов;
-
Yandex SpeechKit – для преобразования звука в текст.
Вначале, в 2017 году, Yandex Object Storage был не нужен, мы использовали Yandex SpeechKit напрямую – отправляешь wav-файл, ждешь в режиме онлайн и получаешь в текстовом виде расшифровку.

Переходим к Яндекс.Облаку.
Чтобы работать с Облаком, нужно установить тоже командный интерфейс Curl, нужно зарегистрироваться и пройти авторизацию.
Сейчас я более подробно расскажу про каждый из пунктов.

Вначале ставим Curl – это кроссплатформенная служебная программа командной строки.
Ничего сложного тут нет – просто заходим по гиперссылке https://cloud.yandex.ru/docs/cli/quickstart, скачиваем и устанавливаем.
Это нам дает возможность прямо из 1С в командной строке вызывать системные функции для работы с Яндекс.Облаком.

Далее мы:
-
Регистрируемся, получаем имя пользователя и пароль
-
В 2017 году этого было достаточно, чтобы начать работать. Сейчас, чтобы начать распознавать аудио-звонки, нам нужно создать платежный аккаунт и закинуть туда определенную сумму денег – бесплатного распознавания уже нету.
-
Далее мы создаем сервисный аккаунт, это связано с безопасностью – с каталогами Яндекс.Облака нельзя работать под общим аккаунтом, там для каждого объекта создается свой сервисный аккаунт и ему назначаются нужные права конкретно на эти объекты. В принципе, это правильно, но это немного усложнило работу.

Когда мы зарегистрировались, получаем OAuth-токен.
Как было показано предыдущих слайдах, мы установили Curl, и с его помощью запускаем команду yc init, которая привязывает профиль CLI на данном компьютере к Облаку.
В этой команде мы задаем, куда привязать профиль:
-
к какому облаку;
-
к какому каталогу;
-
и в какой зоне доступности будут происходить наши вычисления – у Яндекса на данный момент есть три зоны доступности (Владимирская, Рязанская и Московская область), где происходит расшифровка звонков.
После того как мы получили OAuth-токен, мы в принципе можем начать работать.
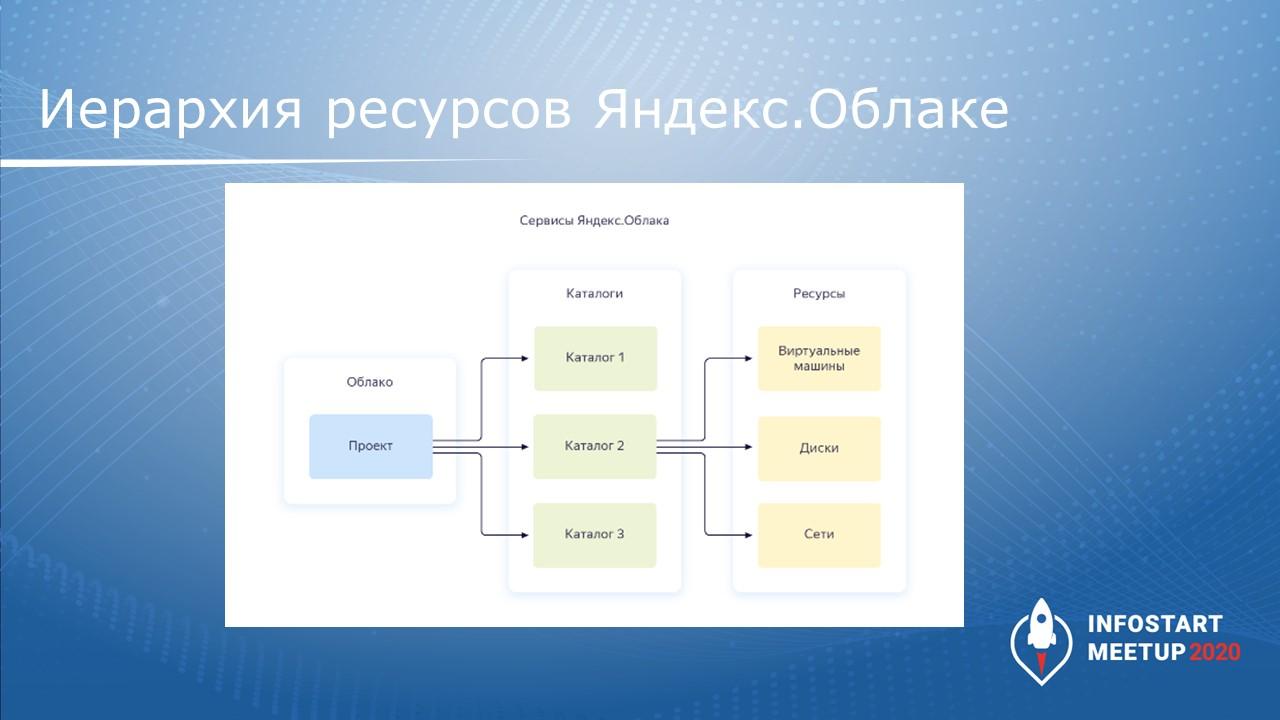
На данном слайде показано, для чего нужно создавать сервисный аккаунт – сервисному аккаунту мы назначаем права на использование ресурсов и каталогов.
У Яндекса есть ограничение – с одного компьютера можно запускать не более 20 потоков.
Поскольку я укладывался во все лимиты Яндекс.Облака, у меня было:
-
одно облако;
-
один каталог;
-
и два ресурса – расшифровка звонков и хранение в Yandex Object Storage.
Если если вам нужна более масштабная расшифровка звонков, то необходимо поднимать, допустим, две виртуальных машины и на них на Яндексе регистрировать два облака – это позволит масштабироваться.

Итак, мы зарегистрировались, получили OAuth-токен, теперь нужно получить IAM-токен.
IAM-токен имеет ограниченное время жизни – не более 12 часов. Соответственно, 2 раза в сутки он меняется. Поэтому если он нужен при работе, допустим, в 1С, его можно получить программно вызовом команды
yc iam create-token > » + IAMtoken
Бесплатный GPS-трекинг Промо
Современные технологии и возможности становятся все более доступными для широких масс и повсеместно используемыми, как для частного лица, так и для мелкого и среднего бизнеса.
Так и GPS-трекинг (отслеживание в реальном времени на карте местоположения водителей, курьеров, монтажных бригад, торговых представителей, детей, собак и т.п., а также просмотр статистики по их передвижениям и остановкам), становится сейчас все более востребованным сервисом, как для домашних условий, так и для предприятия.
И, если крупные фирмы (например, транспортные предприятия) подписав договора с коммерческими сервисами, оплачивая своевременно счета за устройства и абонплату, эту проблему для себя решили, то это скорее подходит для крупных корпоративных клиентов.
Что делать нам, простым смертным или небольшой фирме с несколькими водителями, например? Какие есть простые, надежные и недорогие решения?
Аналитика по телефонным звонкам для бизнеса

Что может принести бизнесу распознавание телефонных звонков?
-
Во-первых, это увеличение закрытых сделок. Если разработать скрипт разговора совместно с продажниками, с HR-менеджерами, с руководством, и контролировать, как менеджер по этому скрипту разговаривают, это поможет увеличить количество закрытых сделок.
-
Во-вторых, можно искать вхождение слов. Допустим, менеджер при разговоре с клиентом произносит несколько раз слово «Заказ», «Сделка», «Доставка» – потом по этим словам можно сделать отбор, найти в справочнике все звонки, где эти слова встречались, и, допустим, перезвонить клиенту еще раз, либо передать в доставку. Это позволит не потерять эту сделку.
-
В-третьих, в конце месяца можно посмотреть количество минут, проговоренных каждым из менеджеров, и скоррелировать это с зарплатой – это еще один KPI для менеджеров.
-
В-четвертых, это проверка ошибок. Руководство может посмотреть, кто первый предложил предоставить скидку – это сделал менеджер либо это попросил клиент. Также можно делать разбор конфликтов. Я считаю, что для бизнеса это нужно и позволяет увеличить прибыль.
Регистрация в «Облаке»
Для этого нам понадобится Яндекс-аккаунт: заведите новый, если его у вас нет, или войдите в него под своим логином.
Если аккаунт уже есть — переходим на страницу сервиса cloud.yandex.ru и нажимаем «Подключиться»:
На следующем шаге подтверждаем согласие с условиями, и мы у цели:
На главной странице «Облака» активируем пробный период, чтобы бесплатно использовать все возможности сервиса, в том числе и SpeechKit:
Единственное, что нам осталось из формальностей, — заполнить данные о себе и привязать банковскую карту. С неё спишут два рубля и сразу вернут их, чтобы убедиться, что карта активна. Она нужна для того, чтобы пользоваться сервисами после окончания пробного периода. Если вам это будет не нужно — просто удалите карту, когда закончите проект.
Когда подключите карту — нажмите «Активировать».
Когда всё будет готово, вы попадёте на главную страницу сервиса, где увидите что-то подобное:
Вместо статуса Active вы увидите статус «Пробный период» и баланс в 3000 ₽ без кредитного лимита.
Настраиваем доступ
Есть два способа работать с сервисом SpeechKit: через IAM-токен, который нужно запрашивать заново каждые 12 часов, или через API-ключ, который постоянный и менять его не нужно. Мы будем работать через ключ, потому что так удобнее.
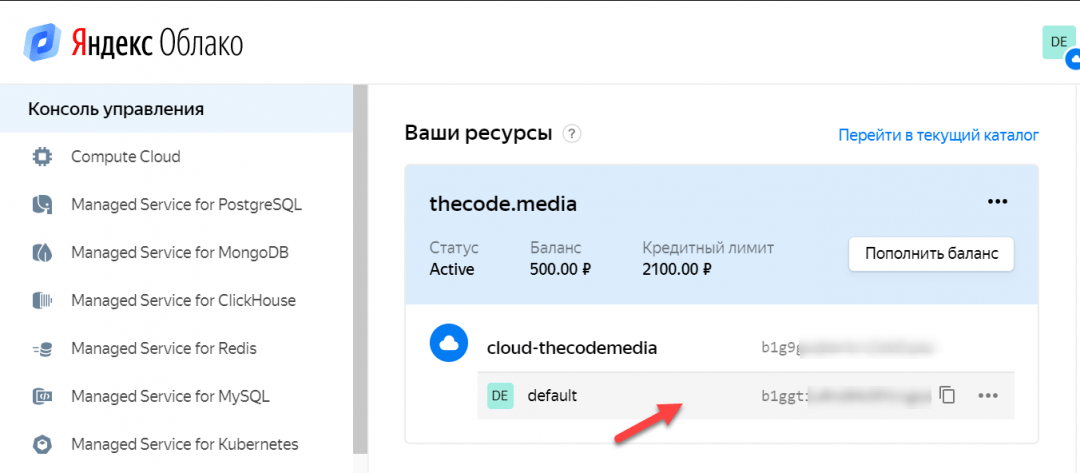
Чтобы его получить, нам нужен сервисный аккаунт в «Облаке». Создадим его так.
1. Заходим в консоль управления и нажимаем на единственную папку в нашем облаке:
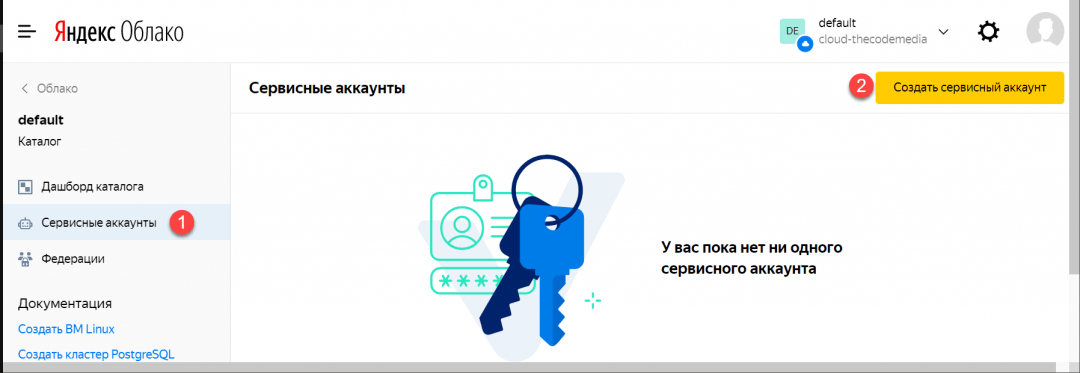
2. Выбираем «Сервисные аккаунты» → «Создать»:
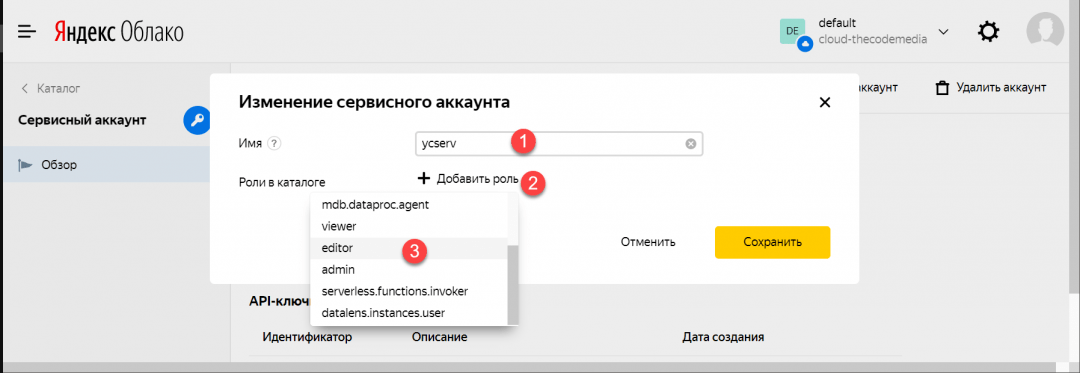
3. Вводим имя (какое понравится), затем нажимаем «Добавить роль» и выбираем «editor»:
4. Заходим в сервисный аккаунт, который только что создали:
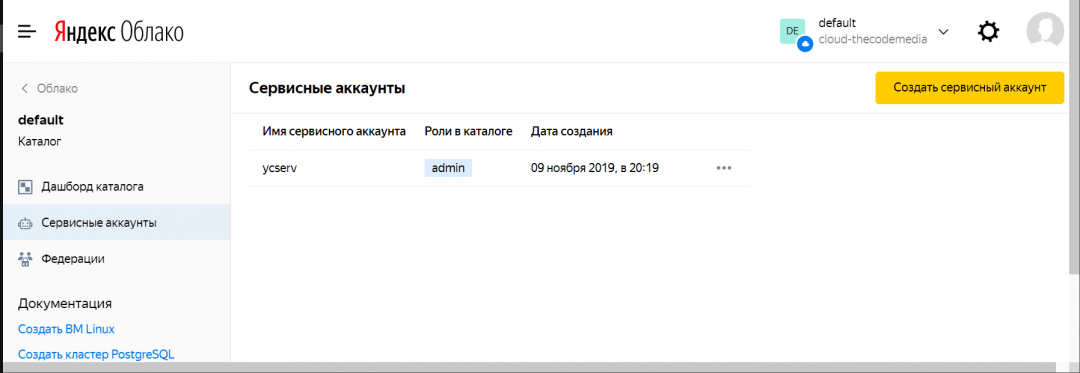
5. Нажимаем на кнопку «Создать новый ключ» и выбираем пункт «Создать API-ключ»:
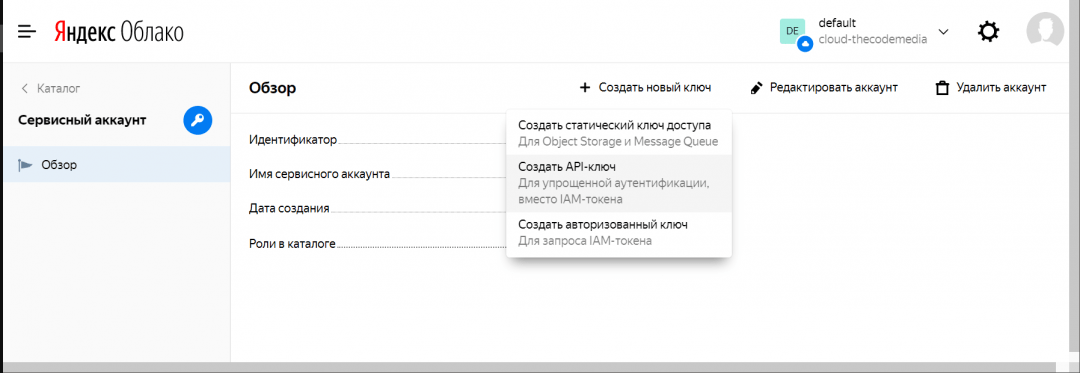
Сервис спросит про описание — можно ничего не заполнять.
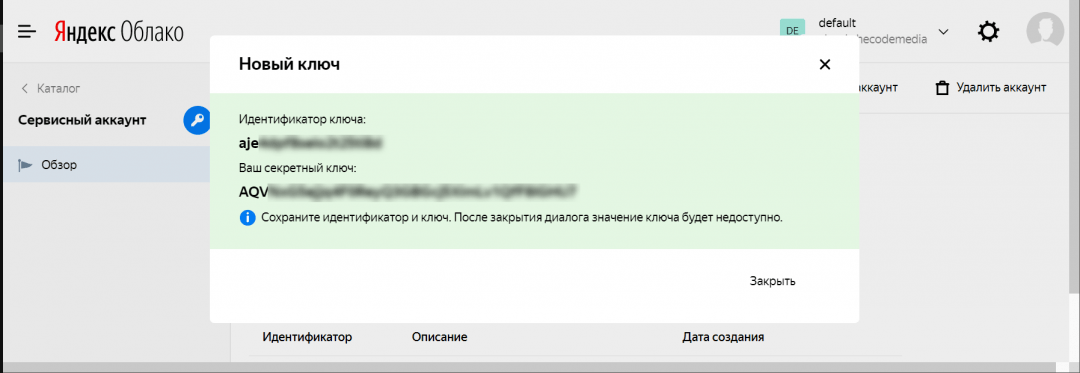
6. Сохраняем отдельно секретный ключ — он выдаётся только один раз и восстановить его нельзя. Выделяем, копируем и сохраняем в безопасное место:
Работа с файлами телефонных звонков
Какая ситуация с телефонией у нас была на предприятии:
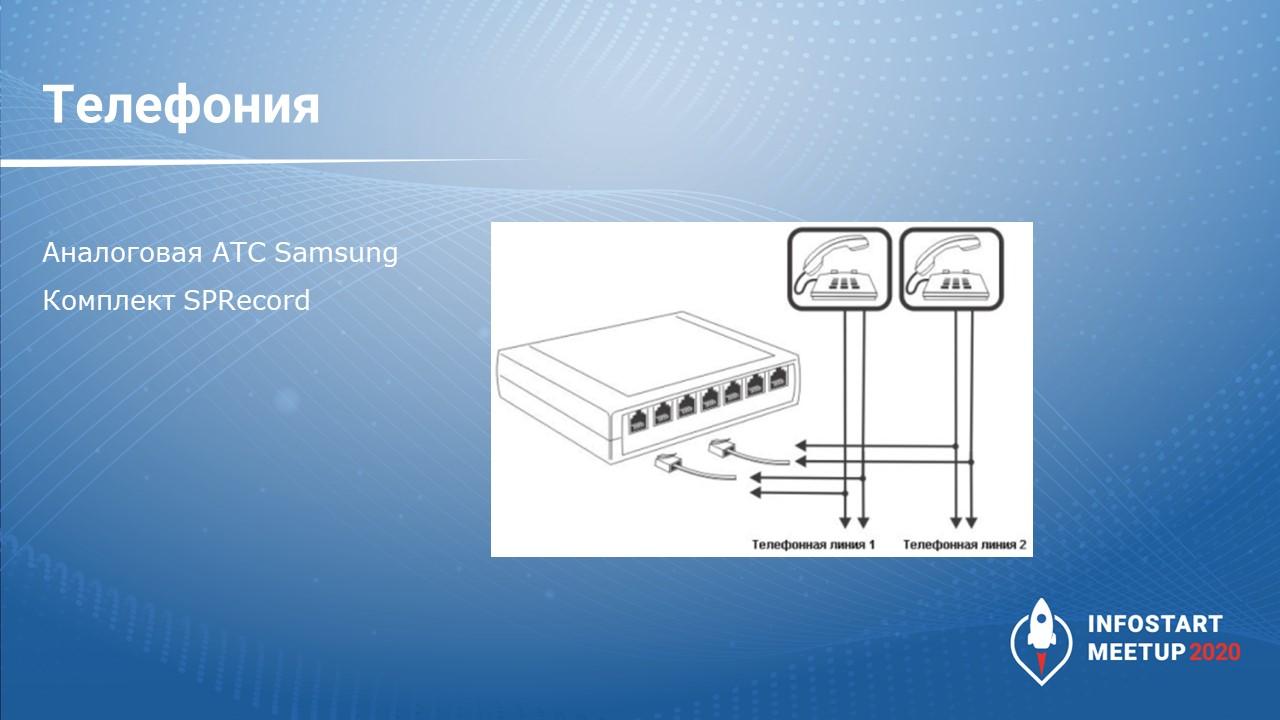
-
У нас аналоговая АТС – аналоговые линии.
-
Дополнительно мы докупили комплекты SPRecord – можно перейти на сайт SPRecord, посмотреть, что это за устройство. Оно вешается параллельно аналоговой линии, записывает разговор и преобразует его в цифру – все звуковые файлы у него хранятся в формате *.wav без сжатия.
Соответственно, то, о чем я рассказываю, подходит для старых телефонных сетей. В новых цифровых сетях это уже решается гораздо проще – например, у MANGO есть отдельный сервис расшифровки телефонных звонков и отправка их на на почту.
Итак, у нас на фирме была аналоговая АТС, и все звонки записывались в формате *.wav.
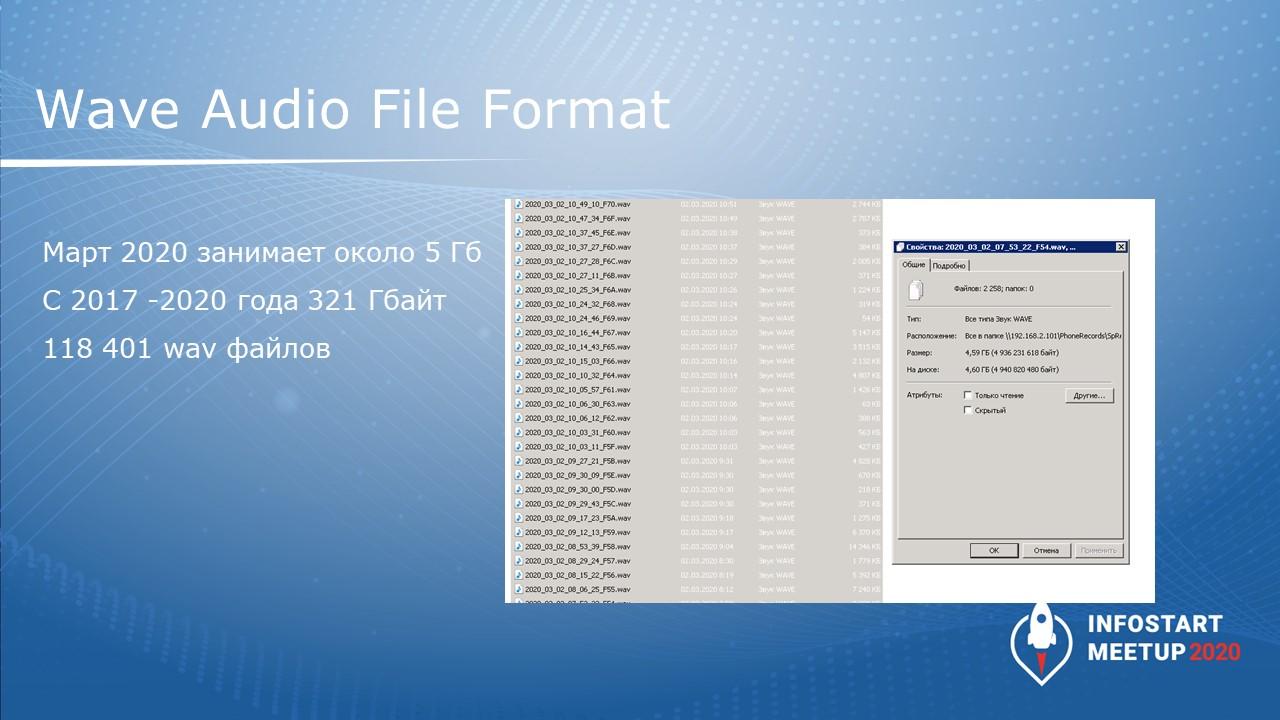
Начинали мы это делать еще в 2017 году, и за это время по текущую дату записано 118 тысяч звонков.
Объем файлов за месяц занимает примерно 5 гигабайт (по данным марта 2020 года).

Что нужно сделать, чтобы как-то обработать эти файлы? Я использовал бесплатную кросс-платформенную утилиту Sox Sound eXchange. Она вызывается из командной строки и с ее помощью можно прямо из 1С выполнить следующие действия:
-
получить длительность аудио – по команде
sox —i -d input.wav > output.txt -
поменять дискретизацию – по команде
sox —i -r » input.wav > output.txt -
обрезать файл – по команде
sox input.wav output.wav trim 20
Обрезку я использовал для исходящих звонков, где у нас обычно 20 секунд занимает дозвон – эти 20 секунд можно спокойно обрезать, чтобы сэкономить на расшифровке звонка.
У Яндекса расшифровка кратна 15 секундам, соответственно даже если вы отправляете одну секунду, вы платите за 15. Обрезав 20 секунд мы экономим на одном такте распознавания.
С аналоговой телефонии мы снимаем файлы в несжатом виде, в формате *.wav, а в Yandex их нужно отправлять в специальном формате OggOpus.
Соответственно, используем бесплатную консольную конвертацию с помощью утилиты opensenc, которую можно скачать с сайта https://opus-codec.org/
Команда выглядит так:
На входе даем wav-формат, и получаем сжатые аудиоданные.
Funny voice
Замыкает наш список программа Funny voice. Это наиболее простая программа, но она отлично подойдет для среднестатистического пользователя.
Изменение голоса происходит путем передвижения ползунка, который регулирует тональность. Это регулирование – основная функция это утилиты.
Необходимо заметить, что программа является полностью бесплатной. Скачать ее можно на официальном сайте производителя.

Funny voice интерфейс
Работает программа достаточно просто: она записывает весь звук на микрофон и выводит уже измененный звук утилитой. Здесь есть возможность записать аудио лишь только в формате (wav).
Конечно, это далеко не профессиональное приложение, но побаловаться и посмеяться с друзьями с помощью него вполне возможно. Ведь этой маленькой утилитой можно исказить свой голос до неузнаваемости.
Выводы
Таким образом, программ на российском рынке, специализирующихся на изменения голоса онлайн, существует слишком маленькое количество.
Они есть, но в основном они все лишены русского языка. Поэтому для работы с ними необходимо знать английский язык хотя бы на самом начальном уровне.
Нужно отметить, что в этом топе представлены простые приложения и программы для профессионалов. Так, в простых приложениях можно лишь только изменять тональность голоса, передвигая ползунки.
В профессиональных же программах существует масса функций, с помощью которых есть возможность добавлять различные эффекты, а также изменить мужской голос на женский.
Многие утилиты представлены только в платной версии, поэтому чтобы ими воспользоваться, необходимо заплатить денежку производителю.
По нашему мнению, лучшей программой из всех является Voxal Voice Changer. В приложение есть русский язык, что редкость.
А также существует бесплатная и платная версия, что позволяет использовать ее профессионалам и любителям.
StartManager 1.4 — Развитие альтернативного стартера Промо
Очередная редакция альтернативного стартера, являющегося продолжением StartManager 1.3. Спасибо всем, кто присылал свои замечания и пожелания, и тем, кто перечислял финансы на поддержку проекта. С учетом накопленного опыта, стартер был достаточно сильно переработан в плане архитектуры. В основном сделан упор на масштабируемость, для способности программы быстро адаптироваться к расширению предъявляемых требований (т.к. довольно часто просят добавить ту или иную хотелку). Было пересмотрено внешнее оформление, переработан существующий и добавлен новый функционал. В общем можно сказать, что стартер эволюционировал, по сравнению с предыдущей редакцией. Однако пока не всё реализовано, что планировалось, поэтому еще есть куда развиваться в плане функциональности.
1 стартмани
Usage
YSKSpeechKit
Singleton class for configuring and controlling the library. You don’t need to explicitly create or destroy instances of the class. To access an object, use the method, which creates an instance of the class when accessed the first time. This instance is destroyed when the application closes.
Before using any of the SpeechKit functionality, you must configure using the API key (for more information, see ). To do this, call the method in the application:
YSKSpeechKit.sharedInstance().apiKey = "developer_api_key"
YSKAudioSessionHandler
Use this class to configure the application’s audio session for recording and playing audio. The audio session is a singleton object that configures the audio context of the application so that it can interact with other applications that use audio. The application always uses a single instance of the audio session, so the audio session is configured and activated outside the realm of the library components. The class makes it easier to configure the audio session. If your application uses an audio session only when working with the library, we recommend using this class to configure the audio session. If your application uses the audio session outside of the library (for audio and video playback, recording audio, and so on), you can also use this class, or configure the audio session independently.
do {
try YSKAudioSessionHandler.sharedInstance().activateAudioSession(with:settings)
}
catch {
print("AVAudioSession deactivation did fail with error: \(error.localizedDescription)")
}
YSKOnlineRecognizer
let settings = YSKOnlineRecognizerSettings(language: YSKLanguage.english(), model: YSKOnlineModel.queries()) // 1 let recognizer = YSKOnlineRecognizer(settings: settings) recognizer.delegate = self recognizer.prepare() recognizer.startRecording()
func recognizer(_ recognizer: YSKRecognizing, didReceivePartialResults results: YSKRecognition, withEndOfUtterance endOfUtterance: Bool) {
print("Partial result: \(results.description)")
if endOfUtterance {
print("Recognition result: \(results.bestResultText)")
}
}
YSKOnlineVocalizer
let settings = YSKOnlineVocalizerSettings(language: YSKLanguage.english())
let vocalizer = YSKOnlineVocalizer(settings: settings)
vocalizer.delegate = self
vocalizer.prepare()
vocalizer.synthesize("What's up kid?", mode: .append)
Интеграция 1С с ГИИС ДМДК
ГИИС ДМДК — единая информационная платформа для взаимодействия участников рынка драгоценных металлов и драгоценных камней. с 01.09.21 стартовал обязательный обмен данными с Федеральной пробирной палатой (ФПП) исключительно через ГИИС. А постепенно — с 01.01.2022 и с 01.03.2022 — все данные о продаже драгоценных металлов и камней должны быть интегрированы с ГИИС.
У многих пользователей возникает вопрос как автоматизировать обмен между программой 1С и ГИИС ДМДК.
В настоящей статье ВЦ Раздолье поделится своим опытом о реализации такого обмена.
Автор статьи — Мордовин Антон — архитектор систем на базе 1С Внедренческого центра «Раздолье».




