Семантическое ядро сайта
Содержание:
- Распространенные ошибки при составлении ядра
- Что такое семантическое ядро простыми словами
- Как подобрать ключевые слова для SEO
- Сервисы для парсинга и кластеризации
- SpyWords
- Запросы по частотности
- Зачистка списка
- Платные способы парсинга запросов конкурентов
- Группировка семантического ядра для информационного сайта
- Сервисы и инструменты для работы с семантикой
- Как работать с семантикой и составлять СЯ
- Как использовать готовое семантическое ядро
- Подключаем инструменты подбора семантики
Распространенные ошибки при составлении ядра
Чаще всего при работе с СЯ вебмастера допускают следующие 8 ошибок:
- Использование искусственных ключей в СЯ. Многие ключевые фразы, которые присутствуют в сервисе статистики Wordstat, созданы искусственно во время накручивания поисковых подсказок. Пример:
- Дубли ключей в ядре. Нужно избавиться от ключей, которые повторяют друг друга. Поисковая система понимает, что это одинаковые фразы, поэтому не стоит включать их в СЯ.
- Использование информационных и коммерческих ключей на одной странице. Одновременное продвижение таких групп запросов (например, «как выбрать холодильник» и «купить холодильник») невозможно.
- Создание страниц без ориентации на СЯ. Если вы планируете выстроить правильную иерархию страниц на сайте, ориентируйтесь на семантическое ядро и анализируйте успешных конкурентов.
- Недостаточное количество запросов для одной страницы. Не бойтесь продвигаться по нескольким ключевым словам на одной странице. Можно успешно использовать до 100 слов на документ.
- Неправильная группировка запросов. Во время кластеризации одинаковые по смыслу запросы, используют на разных страницах.
- Собраны только очевидные запросы без словоформ, синонимов и профессионализмов.
- Не задан регион при сборе СЯ. В результате в продвижении участвуют даже те запросы, которые должны были отсеяться.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
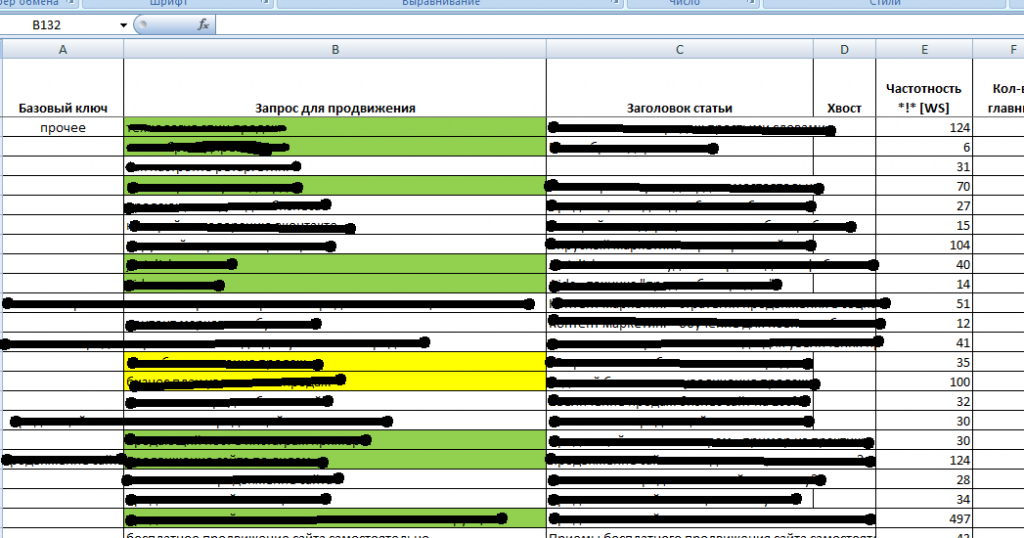
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Как подобрать ключевые слова для SEO
Процесс сбора семантики состоит из нескольких этапов. Для начала нужно определить маркерные запросы, охватывающие направление деятельности. Затем происходит расширение СЯ и чистка «мусора».
Определяем маркерные (базовые) ключи
К их числу относятся ключевые слова, которые точно описывают содержимое страницы. Обычно они имеют наиболее высокую частотность. От них отстраивается «хвост» запросов (например, «отзывы», «купить», «цена» и так далее). Часто маркерный запрос содержится в заголовках h1. Именно с них и начинается сбор всей семантики.
Выпишите в отдельном документе общие поисковые фразы, относящиеся к вашей тематике. Фиксируйте все идеи, которые пришли в голову, так как в будущем не нужные запросы все равно отсеются. Примерный список:
Теперь из этих запросов (они ВЧ) нужно получить СЧ и НЧ поисковые фразы, чтобы расширить семантику.
Расширяем семантическое ядро
Справиться с этой задаче можно через специальный софт (например, Key Collector) или сервис «Вордстат». Если направление вашей деятельности привязано к конкретному региону, то нужно выбрать это в настройках.
Нужно скопировать все ключи из левой колонки и просмотреть правую, возможно, и там будут фразы, полезные для продвижения. Полный список может насчитывать сотни или даже тысячи поисковых слов.
Чистка ключей
Самый сложный этап — удаление «мусорных» запросов. Вам придется избавиться от неподходящих или незаконченных фраз. Например, ключ «диетический торт». По сервису «Вордстат» у него всего 2 точных запроса в месяц по региону Зарайск.
Продвигать такие ключи нецелесообразно, так как доходы не окупят затраты. Поэтому лучше отсеивать ключевые фразы, у которых точная частотность меньше 10. Этот ключ подошел бы для СЯ, если бы имел большую частотность, и вы занимаетесь производством таких кондитерских изделий.
Что не стоит включать в СЯ:
- ключи с брендами конкурентов;
- ключи с несуществующими у вас услугами или продуктами;
- дубли ключей (например, «торты на заказ на корпоратив» и «торты на корпоратив на заказ» — один и тот же ключ);
- ключи с чужими регионами;
- слова с ошибками.
После того как вы очистите СЯ от ненужных фраз, переходите к их группировке. Объединяйте запросы, которые можно продвигать на одной странице.
Сервисы для парсинга и кластеризации
Опытные оптимизаторы используют для сбора семантики платные программы и сервисы. Новичкам рекомендуем воспользоваться бесплатными ресурсами, которые предоставляют базовые услуги.
С помощью готовых баз и парсеров экономится время: например, стоп-слова отражаются автоматически, отсеивание ключей определяется особенностями отрасли. Собирая семантику вручную, стоп-слова приходится отбирать самостоятельно для каждой тематики, учитывая интересы, тематику и цели компании.
Яндекс.Вордстат
Популярный бесплатный инструмент для сбора и расширения семантического ядра. Минусы для SEO-специалиста в том, что нужно постоянно вводить капчу, что, в общем, отнимает много времени и по одному запросу сервис показывает не более 41-й страницы, что для высококонкурентных тематик крайне мало.
Правая колонка содержит альтернативные фразы, а в колонке слева находятся ключи, с помощью которых можно углубиться в тематику и найти «хвосты».
Помимо «Вордстата» маркерные ключи подбираются при помощи «Яндекс.Вебмастер» и «Яндекс.Метрика». В «Метрике» есть раздел «Поисковые запросы», который содержит популярные запросы, по которым пользователи переходят на сайт.
Key Collector
Платный сервис, автоматизирующий сбор семантики при помощи Yandex.Wordstat, Google Ads и других. Сервис обеспечивает чистоту семантики (без стоп-слов и лишних фраз), сортирует и фильтрует ключи, опираясь на их частотность (можно собирать как все типы ключей, так и, к примеру, только высокочастотные).
К достоинствам программы можно отнести работу с разными источниками, что обеспечивает большую глубину сбора данных. Также сервис выполняет кластеризацию семантического ядра. К недостаткам софта SEO специалисты относят медленную работу при большой нагрузке, необходимость приобретения антикапч для ускорения процесса парсинга.
Лицензия на использование программы стоит для физических лиц 2200 рублей, а если вы юридическое лицо, то придется заплатить всего на 100 рублей больше.
MOAB. Tools Семантика
Сервис работает онлайн, не нужно скачивать никаких программ. Парсит данные для семантики из «Вордстата» и подсказок. Попадают даже длинные запросы с «хвостами». Поиск не требует ввода капчи, а выполненную работу можно интегрировать с Key Collector. Сервис сразу определяет частотность.
Инструмент позволяет определить 5 000 запросов бесплатно. Если вы начинающий оптимизатор, то вам подойдет тариф Mini, который стоит 1 299 рублей. Ядро рассчитано на 50 000 фраз. Если семантика собирается для большого проекта, то воспользуйтесь тарифом Pro, который рассчитан на 500 000 фраз. Цена — 6 099 рублей.
Yandex Wordstat Assistant
Речь пойдет не о привычном для нас «Вордстате», а о бесплатном дополнении, которое копирует и размещает полученные результаты в Excel. Это браузерное дополнение, которое не нуждается в установке на компьютер. Сервис в автоматическом режиме находит дубли и позволяет вставлять фразы вручную. Полезный инструмент, который должен быть на вооружении у всех оптимизаторов, работающих с инструментами «Яндекс».
Serpstat
Дорогой, но результативный сервис, позволяющий собрать и сгруппировать поисковые фразы. Сортирует ключи по показателям частотности и конкурентности. Таким образом, по шкале от 1 до 100, можно определить, насколько ресурсозатратным может оказаться продвижение ресурса. Ресурс отображает ключи по региональной выдаче. То есть, как и в Вордстате, показывает, в каком регионе пользователи какие запросы вбивают.
У программы есть бесплатная версия, но она малорезультативная. Самый дешёвый тариф стоит 55 долларов.
SpyWords
SpyWords — это онлайн-сервис, который поможет подобрать семантическое ядро на основе ключевых запросов конкурентов в рекламе и SEO-продвижении.
Инструмент поможет найти ключевые фразы, которые используют конкуренты в Яндекс или Google, и добавить их в свои рекламные кампании. Порой попадаются такие запросы, придумать которые самому тяжело.
В SpyWords можно не только скачать ключевые фразы конкурентов, но и увидеть тексты их объявлений, позиции в выдаче, дневной бюджет.
Сервис также помогает найти перспективные для продвижения продукты — те, на которые большой спрос, но без серьезной конкуренции. Об этом можно судить по стоимости клика по ключевым словам. Например, если стоимость клика довольно высокая, делаем вывод, что фразу используют много рекламодателей. Значит, есть спрос на товар и можно получить прибыль.
Если внимательнее разбирать отчеты SpyWords, можно найти ключи и нишу, где большой спрос, но мало конкурентов или дешевые клики. Следовательно, можно продвигаться там. Подход будет полезен и для контекста, и для SEO.
Сервис платный: от 3 300 рублей в месяц без учета скидок.
Запросы по частотности
-
Высокочастотные (ВЧ)
Наиболее популярные тематические слова. Они имеют большую конкуренцию, поэтому долго выводятся в ТОП. Могут состоять из одного или двух слов. Показатель частотности от 1500. -
Среднечастотные (СЧ)
Имеют средний показатель частотности между ВЧ и НЧ — до 1500 показов в месяц. Чаще всего состоят из нескольких слов. -
Низкочастотные (НЧ)
Узкое направление с точным отражением потребности пользователей. Содержат невысокую конкуренцию, что позволяет их быстро вывести в ТОП. Частотность — меньше 150 показов в месяц.
Используя для продвижения сайта только СЧ и ВЧ запросы, не забывайте, что на их вывод в ТОП-10 уйдет больше времени и усилий. Поэтому лучше использовать все группы запросов.
Зачистка списка
Теперь нам необходимо сделать зачистку ключевых слов в списке масок. Для этого необходимо отсортировать наш список в порядке убывания параметра «частотность» (количество обращений в поисковую систему пользователей сети Интернет по ключевому запросу, т.е. это мера его популярности).
Сортирование запросов по частоте
Для чего это нужно? Каждый ключевой запрос будущего семантического ядра сайта – это потенциальный трафик из сети Интернет. И чем больше посещений будет на целевую страницу с этим словом, тем больше показов и соответственно больше вероятность совершения транзакции (совершение какого-либо действия на странице сайта – например, в нашем случае “покупка компьютера”).
Поэтому, зная предполагаемое количество посещений, можно планировать количество потенциальных посетителей (в нашем случае для компьютерного магазина, потенциальных покупателей).
Для сортировки по частотности можно использовать различные ресурсы, начиная от специализированных программ (например, платная программа “KeyCollector” или бесплатная” СловоЁб”) и заканчивая различными сервисами систем автоматического продвижения (SeoPult, WebEffector, Rookee)и сервисами поисковых систем (Wordstat Яндекс и Google AdWords – Keyword Tool). Для сортировки ключевых слов часто используют последние два сервиса, как первоисточник статистики посещений. Для нашего примера воспользуемся сервисом Яндекса. Отличный сервис для создания семантического ядра.
Сервис Wordstat.yandex.ru
Если Вы еще не знаете, как использовать в своей работе Вордстат, предлагаю следующий материал:
Для получения частот ключевых слов списка масок необходимо совершить следующие действия:
а) переходим в статистику ключевых слов и пишем первую фразу из списка масок. Если продвижение сайта будет происходить в определенном регионе, необходимо “уточнить регион”. После ввода ключевого запроса появятся две колонки с запросами. В левой колонке показан список словосочетаний, включающий нашу фразу и число показов в месяц. В правой колонке можно увидеть похожие ассоциативные запросы со своими частотами, которыми можно пополнить список масок будущего ядра (рисунок 8). Записываем каждое ключевое слово или словосочетание;
Рисунок 8. Проверка частотности ключевиков ядра
Рисунок 9. Корректировка списка с учетом заданной частотности
в) теперь посмотрим частоту точного вхождения ключевой фразы. Это делается следующим образом: ключевой запрос, у которого мы хотим узнать количество показов, заключаем в кавычки и ставим перед ними восклицательный знак (рисунок 10);
Рисунок 10. Проверка частотности точных вхождений ключевых фраз
г) после просмотра всех ключевых фраз из нашей измененной таблицы исключаем слова, у которых точная частота меньше 10 (рисунок 11). Такие словосочетания называются словами-пустышками. Из-за мизерного количества показов они не принесут трафик на целевые страницы. В итоге получается таблица-прогноз посещаемости сайта в течение месяца.
Рисунок 11. Конечная корректировка списка ключевых запросов
Платные способы парсинга запросов конкурентов
Из платных способов, через Keycollector, мы можем спарсить запросы конкурентов через spywords.ru, semrush.com, serpstat.com, а так же через эти сервисы собрать расширения фраз. Еще можно сюда приплести Mutagen.ru, он тоже может расширить ядро, но делает он это не очень.
Сбор аналогичен бесплатному методу, указываете конкурентов и собираете их.Но я сейчас практически не пользуюсь этими сервисами, потому что на рынке есть лучшее решение под рунет — это сервис http://keys.so
Его нет в keycollector, но это не помеха. Без проблем все слова можно выгрузить в Excel, а потом прогнать через KeyCollector.
Чем же лучше Keyso? У него больше база по сравнению с конкурентами. Она у него чистая, нет фраз которые дублируются и пишутся в разном порядке. Например, вы не найдете там таких повторяющихся ключей “диабет 1 типа”, “1 типа диабет”.
Так же Keyso умеет палить сайты с одним счетчиком Adsense, Analytics, Leadia и др. Вы можете увидеть какие еще есть сайты, у владельца анализируемого сайта. Да, и вообще по поиску сайтов конкурентов, считаю это лучшее решение.
Как работать с Keyso?
Берем один любой сайт своего конкурента, лучше конечно побольше, но не особо критично. Потому что мы будем работать в две итерации.Вводим его в поле. Жмакаем — анализировать. Получаем информацию по сайту, нам здесь интересны конкуренты, жмем открыть всех.
Получаем информацию по сайту, нам здесь интересны конкуренты, жмем открыть всех. У нас открываются все конкуренты.
У нас открываются все конкуренты. Это все сайты, у которых хоть как-то пересекаются ключевые слова с нашим анализируемым сайтом. Здесь будет youtube.com, otvet.mail.ru и т.д., то есть крупные порталы, которые пишут обо всем подряд. Нам они не нужны, нам нужны сайты чисто только по нашей тематике. Поэтому мы их фильтруем по следующим критериям.
Это все сайты, у которых хоть как-то пересекаются ключевые слова с нашим анализируемым сайтом. Здесь будет youtube.com, otvet.mail.ru и т.д., то есть крупные порталы, которые пишут обо всем подряд. Нам они не нужны, нам нужны сайты чисто только по нашей тематике. Поэтому мы их фильтруем по следующим критериям.
Похожесть – процент общих ключей от общего числа данного домена.
Тематичность – количество ключей нашего анализируемого сайта в ключах домена конкурента.
Поэтому пересечение этих параметров уберет общие сайты.
Ставим тематичность 10, похожесть 4 и смотрим, что у нас получится.
Получилось 37 конкурентов. Но все равно еще их проверим вручную, выгрузим в Excel и если надо уберем не нужные. Теперь переходим на вкладку групповой отчет и вводим всех наших конкурентов, которых мы нашли выше. Жмем – анализировать.
Теперь переходим на вкладку групповой отчет и вводим всех наших конкурентов, которых мы нашли выше. Жмем – анализировать. Получаем список ключевых слов этих всех сайтов. Но мы еще полностью не раскрыли тематику. Поэтому мы переходим в конкуренты группы.
Получаем список ключевых слов этих всех сайтов. Но мы еще полностью не раскрыли тематику. Поэтому мы переходим в конкуренты группы. И теперь мы получаем всех конкурентов, тех всех сайтов которые мы ввели. Их в несколько раз больше и здесь так же много общетематических. Фильтруем их по похожести, допустим 30.
И теперь мы получаем всех конкурентов, тех всех сайтов которые мы ввели. Их в несколько раз больше и здесь так же много общетематических. Фильтруем их по похожести, допустим 30.
Получаем 841 конкурента. Здесь мы можем посмотреть, сколько страниц у этого сайта, трафика и сделать выводы, какой же конкурент самый эффективный.
Здесь мы можем посмотреть, сколько страниц у этого сайта, трафика и сделать выводы, какой же конкурент самый эффективный.
Экспортируем всех их в Excel. Перебираем руками и оставляем только конкурентов нашей ниши, можно отметить самых эффективных товарищей, чтобы потом оценить их и глянуть какие у них есть фишки на сайт, запросы дающие много трафика.
Теперь мы опять заходим в групповой отчет и добавляем уже всех найденных конкурентов и получаем список ключевых слов.
Здесь мы можем список сразу фильтрануть по “!wordstat” Больше 10. Вот они наши запросы, теперь мы можем их добавить в KeyCollector и указать, чтобы не добавлялись фразы, которые есть уже в любой другой группе KeyCollector.
Вот они наши запросы, теперь мы можем их добавить в KeyCollector и указать, чтобы не добавлялись фразы, которые есть уже в любой другой группе KeyCollector. Теперь мы чистим наши ключи, и расширяем, группируем наше семантическое ядро.
Теперь мы чистим наши ключи, и расширяем, группируем наше семантическое ядро.
Группировка семантического ядра для информационного сайта
При группировке семантического ядра я руководствуюсь здравой логикой, сравнивая её с выдачей.
Для информационных сайтов я не вижу смысла прибегать к кластеризации и четко следовать её требованиям. Поисковая система постоянно обучается и совершенствуется. Сегодня она показывает, что запросы “черный хлеб” и “ржаной хлеб” это разные продукты, а завтра покажет правильно, что это одно и тоже.
Итак, в KeyCollector у нас есть чистенький список запросов и мы собрали по нему данные из поисковой выдачи. Чтобы облегчить работу, группируем ядро средствами KeyCollector.
Заходим в анализ групп, ставим по поисковой выдаче Яндекс, сила 2. Обновляем группировку и экспортируем результаты в Excel.Таким способом у нас получилась группировка исходя из данных поисковой системы Яндекс. Но, как я писал уже выше, что надо следовать преимущественно логике и свои предположения проверять в поисковой системе, поэтому в некоторых группах могут быть запросы, которые вообще никак к ней не относятся. Их надо все пересмотреть и доработать.
Чтобы легче было дорабатывать, лучше всего оставить несколько столбцов только с нужными данными. Обычно я оставляю: базовую частотность, точную, KEI по полноте охвата, конкуренцию.
Покажу группировку на примере, чтобы было наглядно. Например, мы создаем сайт посвященный рецептам блинов. Мы увидели, что есть множество запросов связанные с молоком. Решаем, что будем делать отдельную рубрику “Рецепты блинов на молоке”. На примере этой рубрики и рассмотрим группировку.
Смотрим первую группу:Видим, что в группу “простого рецепта” попал общий запрос “тесто для блинов на молоке рецепт” – этим запросом человек не обязательно хочет найти простой рецепт. По логике, лучше всего этот запрос перенести в общую группу, которая будет вести на категорию со всеми рецептами блинов на молоке.
Но так же следует и глянуть выдачу в яндексе, что там вообще находится. Смотрим и видим, что действительно в выдаче по этому запросу есть пара страниц, которые ведут не на один рецепт, а на множество. Так же видим, что в выдаче большинство страниц ведут на один рецепт, при этом на рецепты тонких блинов. Но это же тупо, человек не обязательно хочет тонкие блины. Если бы он хотел тонкие блины, то он ввёл это в запрос. А у нас общий запрос, мы должны показать ему общую страницу, а он уже на ней должен определиться какие блины он хочет на молоке – с простым рецептом или тонкие блины или в дырочку или еще какие-то. В общем я мыслю так.
Переносим лишний запрос в другую группу, а точнее создаем выше новую “Рубрика рецепты блинов на молоке” отмечаем её другим цветом, потому что это рубрика, а в неё уже будут входить рецепты в нашем случае “простой рецепт блинов на молоке”. Тем самым у нас создается структура внутри семантики.
Все данные по группе суммируем. Бюджет можно выводить средним числом, так как это взаимодополняемые запросы, вы все их продвигаете на одной странице, а не по отдельности.
KEI1 (полнота охвата) выводим по уже известной нам формуле:
/*100
Получается вот такая красота:Данные по «рубрике рецепты блинов на молоке» еще не суммируем, потому что скорее всего туда добавятся еще запросы. Но и не исключено, что в “простой рецепт блинов на молоке” тоже еще добавятся запросы.
К тому же тут еще и затесался запрос с “тонкие блины”. Его тоже отдельно, он будет страницей к рубрике “рецепт блинов на молоке и воде”
И таким вот способом перерабатываем все ядро, в итоге получается вот так:Красным шрифтом помечены дополнительные фразы, которые имеют приставки фото, видео. Для нас это не совсем актуальные фразы. Эти фразы конкурируют с сервисами поисковых систем и трафику по ним очень мало. Но эти фразы подходят по нашему смыслу, поэтому мы их добавляем в группу.
Каждая группа помечена своим цветом. Цвет является структурой сайта, то есть уровнем вложенности страницы.
Например, если бы у нас был запрос “простой рецепт блинов на скисшем молоке”. То он бы уже шёл, как подгруппа к группе “блины на скисшем молоке” и естественно был бы выделен другим цветом. Выглядело бы это вот так:Думаю, идея с цветом понятна. Вот так создается семантика и удобная, понятная структура сайта, где все логично и имеет свой уровень вложенности.
Новые или измененные рубрики добавляем в нашу структуру в xmind.
В общем, чтобы нормально разгруппировать ядро необходимо мыслить логически, вставать на место посетителя, отвечать на вопрос – что он хочет увидеть, введя этот запрос? А также смотреть выдачу по этому запросу и принимать решение, как поступить наилучшим образом.
Сервисы и инструменты для работы с семантикой
Профессиональные SEO-оптимизаторы и маркетологи пользуются рядом программ и сервисов для формирования семантического ядра. Инструменты помогают ускорить и облегчить рутинную работу, а также получить ценные сведения о конкурентах.
Rash-Analytics
Сервис является традиционным инструментом оптимизатора. Функционал включает проверку и мониторинг позиций сайта по запросам, автоматическое составление семантического ядра.
Преимущества сервиса Руш-аналитикс:
- интуитивно понятный интерфейс;
- детальный сбор поисковых подсказок;
- возможность выбирать алгоритм – указание маркеров вручную или полная автоматизация.
Сервис позволяет создать семантическое ядро сайта онлайн.
Key Collector
Десктопная программа используется всеми профессиональными контент-маркетологами и SEO-специалистами. Инструмент подбирает ключевые слова, отсекает ненужные запросы, ищет дублирующие фразы, фильтрует запросы по частоте.
В список задач, решаемых программой, входит сбор статистики сторонних сервисов, таких как Гугл ЭдВордс или Яндекс Метрика.
Преимущества программы:
- алгоритм постоянно обновляется, что позволяет более точно составлять семантическое ядро;
- набор инструментов заменяет функционал сразу нескольких программ и сервисов, необходимых маркетологу и SEO-оптимизатору.
Букварикс
Сервис представляет крупнейшую базу ключевых слов в рунете. Здесь легко сортировать запросы и формировать семантическое ядро для сайта.
Преимущества Букварикс:
- база включает более 2 млрд. ключей;
- можно выгружать семантику конкурентов по домену;
- есть бесплатная десктопная версия;
- понятный интерфейс.
Стоимость использования онлайн-сервиса 695 руб./мес.
Serpstat
Онлайн-сервис платный и стоит $69 в месяц. В нем легко подобрать низко- и среднечастотные ключи. Система анализирует поисковые системы Яндекс и Гугл. Анализ помогает определить частотность ключа, уровень конкуренции, стоимость клика по рекламе, список прямых конкурентов.
Преимущества:
- возможность отслеживать динамику запроса;
- удобная система «подсказок»;
- детальный анализ ТОПа поисковой выдачи.
Онлайн-сервис имеет раздел «Контент-маркетинг». Здесь можно увидеть длинноховстые ключи.
Мутаген
Сервис ориентирован на поиск ключей по частотности и уровню конкуренции. Для анализа ключей он анализирует ТОП-30 сайтов из выдачи Яндекса.
С помощью инструмента легко найти ключи с низкой конкуренцией и максимальной частотностью. Оптимизируя сайт под такие фразы, можно быстро продвинуться на первые строчки поисковой выдачи. Полезный для СЕО инструмент анализа стоит от 30 рублей за 100 проверок.
Как работать с семантикой и составлять СЯ
Как составить семантическое ядро
В статье есть подробные объяснения, поэтому подходит и новичкам. Как работать с запросами для семантического ядра: как собирать, очищать от ненужных ключей, кластеризовать и что делать после этого.
Составление таблицы соответствия «Раздел сайта — URL — Ключи»:
 Составление структуры
Составление структуры
В статье:
-
Зачем семантическое ядро нужно сайту
-
Что первично: СЯ или структура сайта
-
Как подбирать ключи
-
Какими сервисами пользоваться
-
Как чистить результаты и группировать запросы
-
Как применять ключи на страницах
Как провести кластеризацию запросов
После сбора и очистки семантики нужно провести кластеризацию — объединить ключи в группы по контексту. В статье разбираем, по каким параметрам делить ключи на группы, что означает порог кластеризации, какие бывают типы и как сделать это для своего сайта.
 Фрагмент кластеризации для примера
Фрагмент кластеризации для примера
В статье:
-
Что это такое кластеризация и кому нужна
-
Как группировать ключи самостоятельно
-
Пример онлайн кластеризации по шагам
Попробуйте провести кластеризацию в автоматическом сервисе LINE: загрузите семантику, выберите тип, установите порог, а дальше сервис справится сам.
 Кластеризация в LINE
Кластеризация в LINE
Как использовать СЯ на сайте или в рекламе
Работа с запросами, входящими в семантическое ядро (СЯ) состоит из сбора, очистки и кластеризации. Следующий шаг — использование их при создании сайта, его оптимизации или создании нативной рекламы.
Получив результаты группировки, нужно определить оптимальное место для каждого из них: на странице ресурса, в составе контента вашего сайта или сторонней площадки. В статье объясняем, какое место будет оптимальным.
В статье:
-
Цели и виды запросов
-
Маркировка запросов
-
Ключевые слова в нативной рекламе
-
Как поисковый робот воспринимает ключевые слова
3 популярных мифа о топовой семантике
На почве неактуальных статей по SEO появляются мифы о том, как собрать семантику сайта, выстраивать структуру для поисковиков, писать SEO-тексты.
Разберем три популярных мифа о подборе семантики для сайта, которые могут навредить оптимизации и увеличить ваши расходы.
В статье:
-
Миф 1: чем больше фраз в СЯ, тем лучше
-
Миф 2: чем больше страниц, тем лучше
-
Миф 3: чем больше SEO-текстов, тем лучше
Как использовать готовое семантическое ядро
Когда вы сделали кластеризацию, ядро готово к использованию. Собранная семантика позволяет:
- Создавать структуру сайта. На основе СЯ создаются страницы и разделы ресурса. Поисковые системы лучше индексируют такой сайт, а пользователи быстрее находят на нем нужную информацию.
- Делать контент. Используйте ключи, когда пишете материалы для сайта. Запросы помогают создавать полезный контент, который отвечает на вопросы людей и приводит к вам целевой трафик.
- Оптимизировать теги. Ключи используют для создания важнейших мета-тегов: основного заголовка (title) и описания страницы сайта (description). Поисковики сканируют эти элементы страниц и учитывают их при индексации. Правильно прописанные title и description улучшают позиции ресурса.
- Запускать контекстную рекламу. В платной выдаче Яндекса и Google ключи применяются для контекстной и баннерной рекламы. Чтобы собрать рекламные объявления, можно взять кластеры, которые вы подготовили для SEO, или же сделать отдельную сортировку ключей.
- Продвигать визуальное содержание. Если вы вставляете ключевые слова в названия и alt-теги изображений, то это повышает вероятность их появления в разделе «Картинки» у поисковиков.
Подключаем инструменты подбора семантики
Когда идеи закончатся, время прибегнуть к помощи инструментов, ведь довериться интуиции недостаточно — инструменты по подбору помогут сосредоточиться на фактических запросах пользователей.
На этом этапе нужно не просто расширить список ключевых фраз, но и отсеять ненужные ключевые слова. Сделать это можно с помощью инструмента подбора ключевых слов Wordstat Яндекса. Чем полезен именно этот инструмент? Он показывает только реальные запросы пользователей, и это поможет собрать актуальные ключевые слова для нужной тематики.
Работать с сервисом просто: задаем регион, в окошко вводим первичный запрос и видим, сколько раз за последние 30 дней пользователи Яндекса вводили поисковой запрос, содержащий искомые слова.
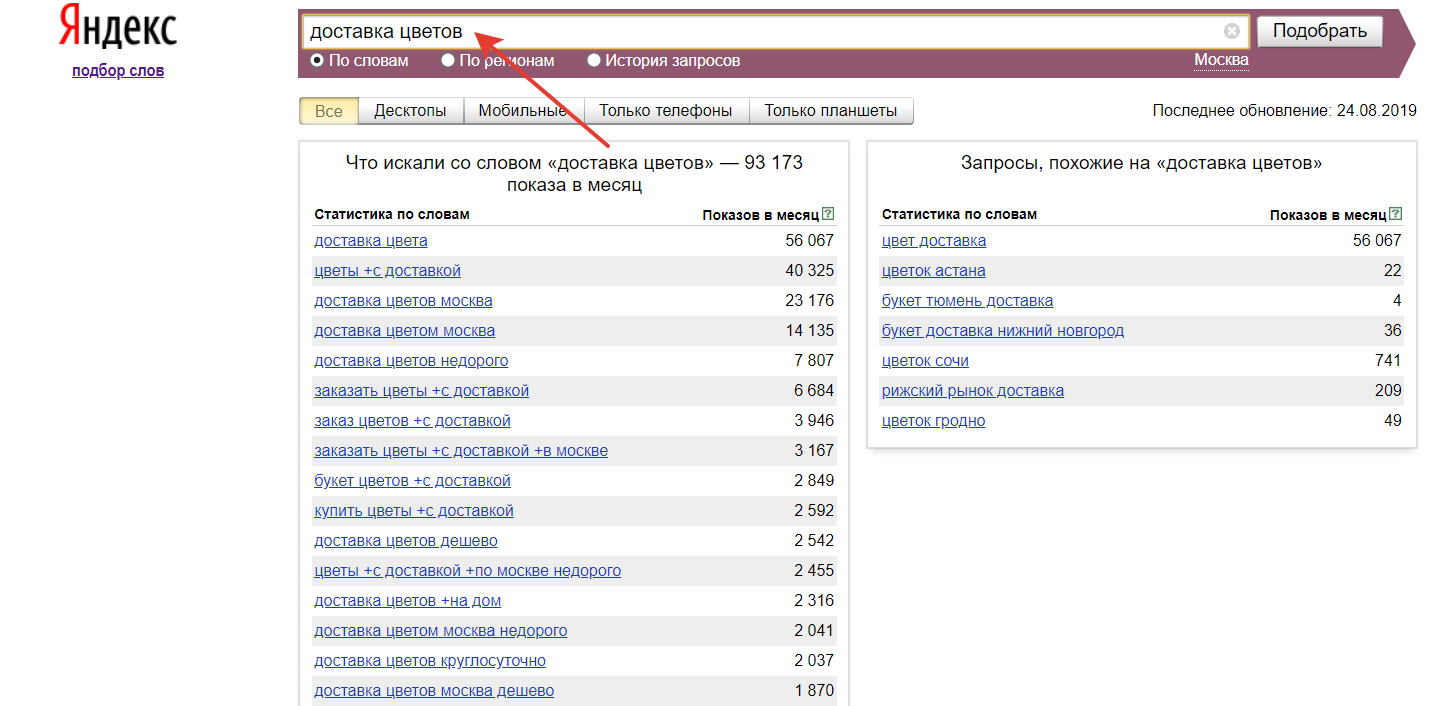 Пример работы с Яндекс Wordstat
Пример работы с Яндекс Wordstat
Таким образом, используя базовые ключевые слова из вашей сферы, можно получить подробный список запросов с нужным словом, а также другие фразы, которые еще искали люди с этим словом.
В левой колонке Яндекс показывает основные запросы, в правой — вспомогательные (ассоциативные). Нам нужны и те, и другие.
Из всех найденных вариантов отбираем только те запросы, которые соответствуют нашему предложению — они и будут ключевыми словами семантического ядра. А также определяем слова или фразы, которые стоит добавить в список минус-слов — по ним реклама показываться не будет. Это позволит избежать расхода бюджета на нецелевые переходы и сохранить высокую кликабельность объявлений.
Основная цель использования минус-слова заключается в том, чтобы отключить показы рекламных объявлений по запросам, не связанным с вашим товаром или услугой. К примеру, у сервиса по доставке цветов нет бесплатного оказания услуги, поэтому фразы, включающие слово «бесплатно», будут для нас нецелевыми запросами. Занесем слово «бесплатно» в список минус-слов.
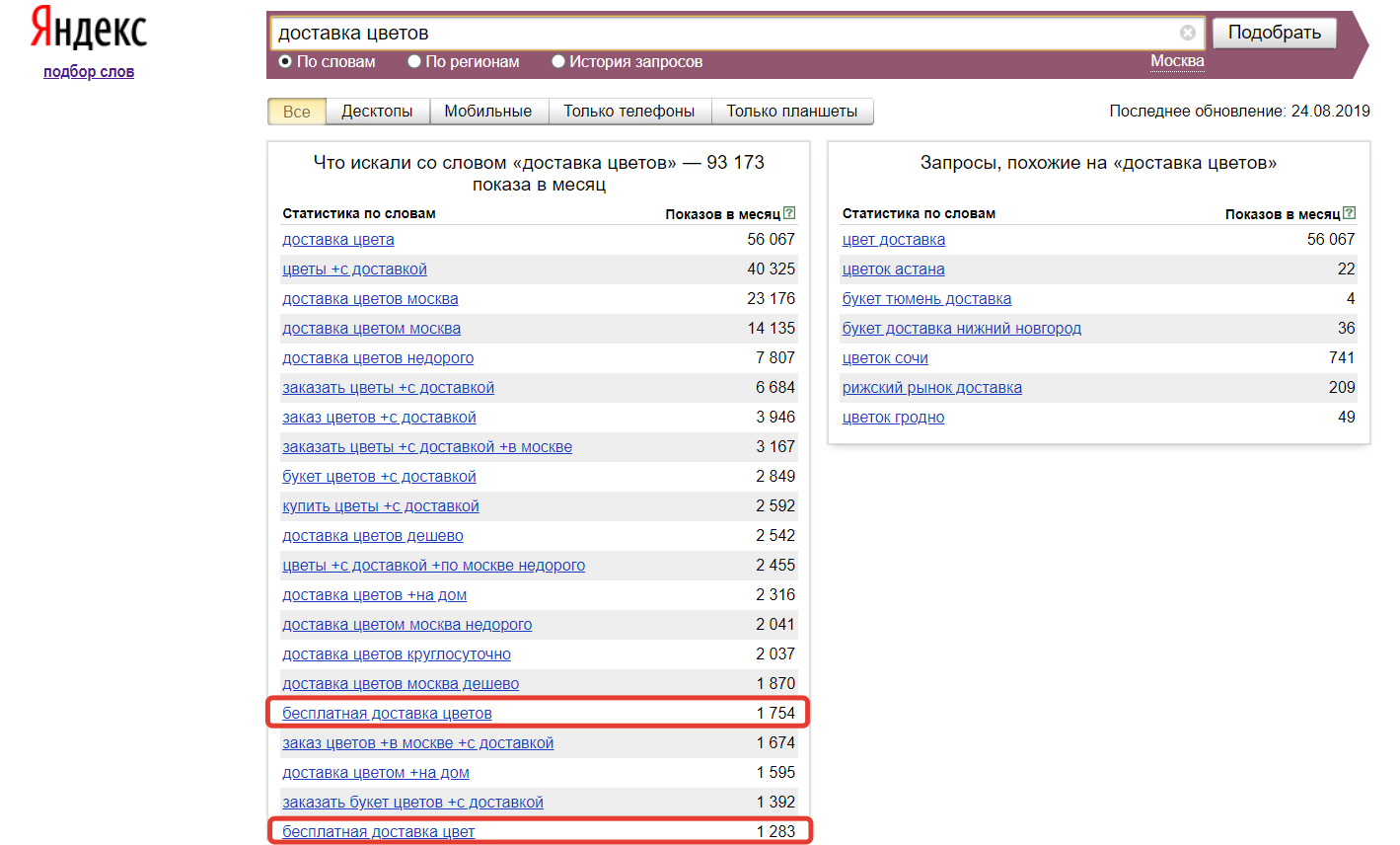 Пример нецелевых запросов в Wordstat Яндекс
Пример нецелевых запросов в Wordstat Яндекс
Попробуем сделать это в Wordstat и увидим изменение количества показов:
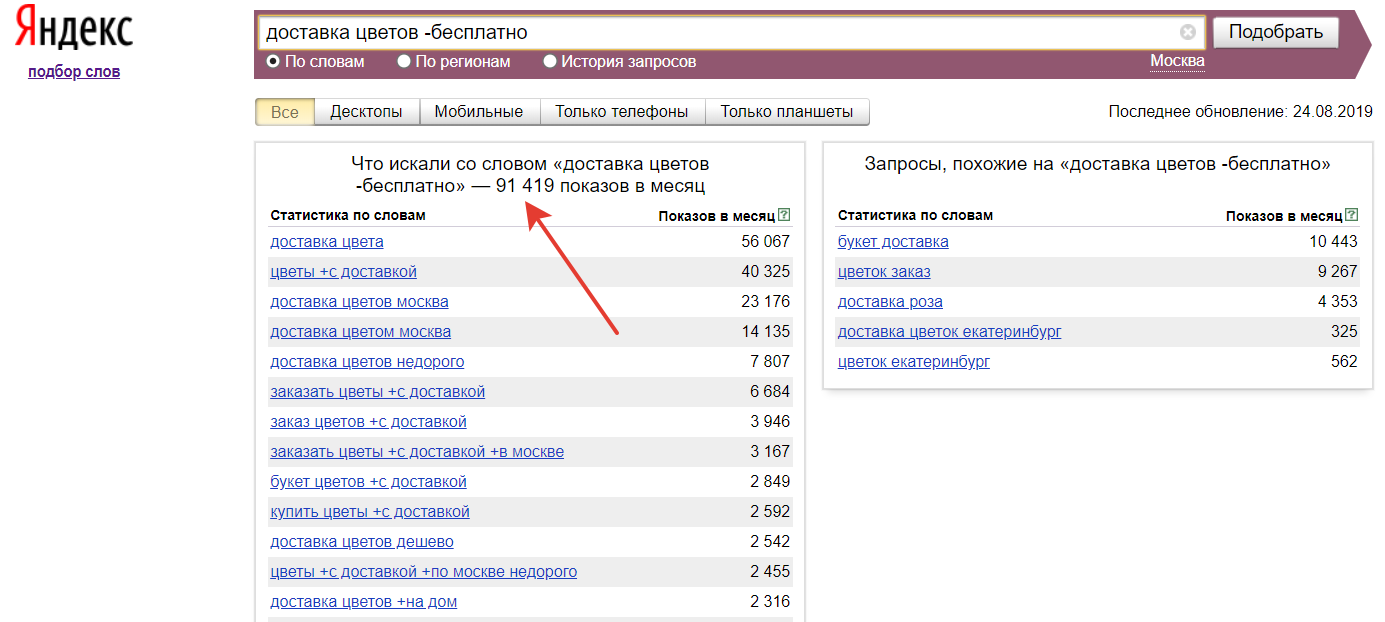 Изменение числа показов в Wordstat при минусовании запросов
Изменение числа показов в Wordstat при минусовании запросов
Разница в числе показов — это та часть нецелевой аудитории, которую удалось отсечь. В будущем это поможет избежать нерациональной траты рекламного бюджета.





