Подбор семантического ядра: обзор инструментов
Содержание:
- Как работать с семантикой и составлять СЯ
- Что такое семантическое ядро простыми словами
- Яндекс.Вордстат
- Нужен ли продвинутый английский язык?
- Как подобрать ключевые слова для SEO
- Сервисы для сбора и кластеризации
- Как пользоваться группировкой?
- Что делать с семантикой после построения СЯ
- Сервисы для парсинга и кластеризации
- Как использовать готовое семантическое ядро
- Serpstat
- Услуги по сбору семантического ядра
- Как это сделать на практике
- Анализ конкуренции запросов для информационных сайтов
Как работать с семантикой и составлять СЯ
Как составить семантическое ядро
В статье есть подробные объяснения, поэтому подходит и новичкам. Как работать с запросами для семантического ядра: как собирать, очищать от ненужных ключей, кластеризовать и что делать после этого.
Составление таблицы соответствия «Раздел сайта — URL — Ключи»:
 Составление структуры
Составление структуры
В статье:
-
Зачем семантическое ядро нужно сайту
-
Что первично: СЯ или структура сайта
-
Как подбирать ключи
-
Какими сервисами пользоваться
-
Как чистить результаты и группировать запросы
-
Как применять ключи на страницах
Как провести кластеризацию запросов
После сбора и очистки семантики нужно провести кластеризацию — объединить ключи в группы по контексту. В статье разбираем, по каким параметрам делить ключи на группы, что означает порог кластеризации, какие бывают типы и как сделать это для своего сайта.
 Фрагмент кластеризации для примера
Фрагмент кластеризации для примера
В статье:
-
Что это такое кластеризация и кому нужна
-
Как группировать ключи самостоятельно
-
Пример онлайн кластеризации по шагам
Попробуйте провести кластеризацию в автоматическом сервисе LINE: загрузите семантику, выберите тип, установите порог, а дальше сервис справится сам.
 Кластеризация в LINE
Кластеризация в LINE
Как использовать СЯ на сайте или в рекламе
Работа с запросами, входящими в семантическое ядро (СЯ) состоит из сбора, очистки и кластеризации. Следующий шаг — использование их при создании сайта, его оптимизации или создании нативной рекламы.
Получив результаты группировки, нужно определить оптимальное место для каждого из них: на странице ресурса, в составе контента вашего сайта или сторонней площадки. В статье объясняем, какое место будет оптимальным.
В статье:
-
Цели и виды запросов
-
Маркировка запросов
-
Ключевые слова в нативной рекламе
-
Как поисковый робот воспринимает ключевые слова
3 популярных мифа о топовой семантике
На почве неактуальных статей по SEO появляются мифы о том, как собрать семантику сайта, выстраивать структуру для поисковиков, писать SEO-тексты.
Разберем три популярных мифа о подборе семантики для сайта, которые могут навредить оптимизации и увеличить ваши расходы.
В статье:
-
Миф 1: чем больше фраз в СЯ, тем лучше
-
Миф 2: чем больше страниц, тем лучше
-
Миф 3: чем больше SEO-текстов, тем лучше
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
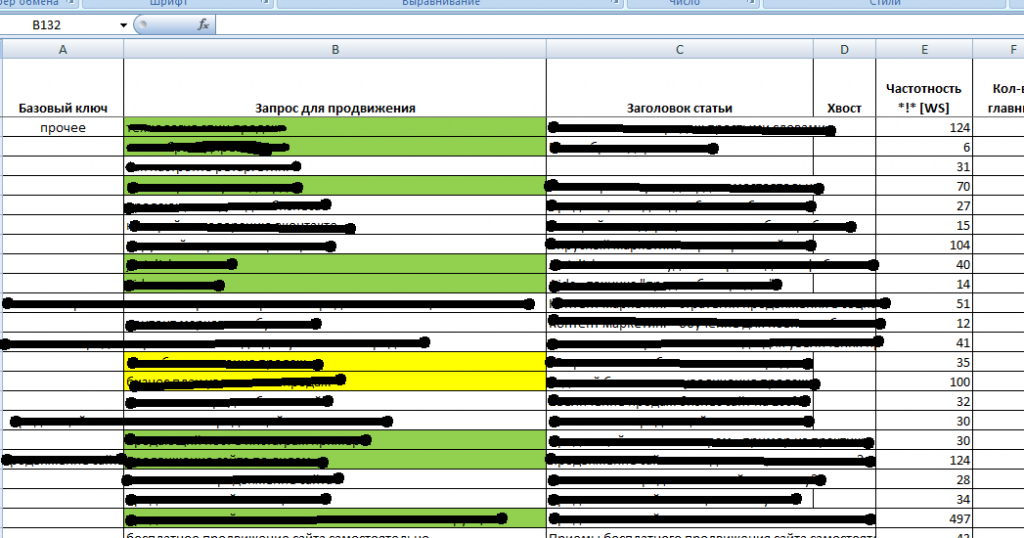
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Яндекс.Вордстат
Wordstat — бесплатный инструмент от Яндекса, который подойдет владельцам блогов и небольших сайтов. Функционал довольно ограничен, поэтому для серьезных сайтов он не пойдет.
Сервис позволяет посмотреть статистику по ключевым словам. Мы можем узнать, какие запросы люди вводили в Яндексе за последний месяц. Также Яндекс.Вордстат показывает:
- похожие ключи;
- количество запросов;
- что еще искали с введенной фразой;
- в каких странах этот ключ наиболее часто ищут;
- историю запросов.
Я лично использую этот сервис для поиска тем для статей и главного ключа. Вордстат позволяет узнать, стоит ли продвигаться по выбранной фразе или же люди такое не ищут.
Давайте разберем функционал на примере:
 Запрос вбивается в поле, отмеченное на картинке красной стрелкой. Ниже можно выбрать тип поиска: по словам (сколько людей вводило этот запрос за последний месяц), по регионам (показы в месяц в разных регионах) или историю запроса.
Запрос вбивается в поле, отмеченное на картинке красной стрелкой. Ниже можно выбрать тип поиска: по словам (сколько людей вводило этот запрос за последний месяц), по регионам (показы в месяц в разных регионах) или историю запроса.
Давайте введем запрос и поищем «по словам»:
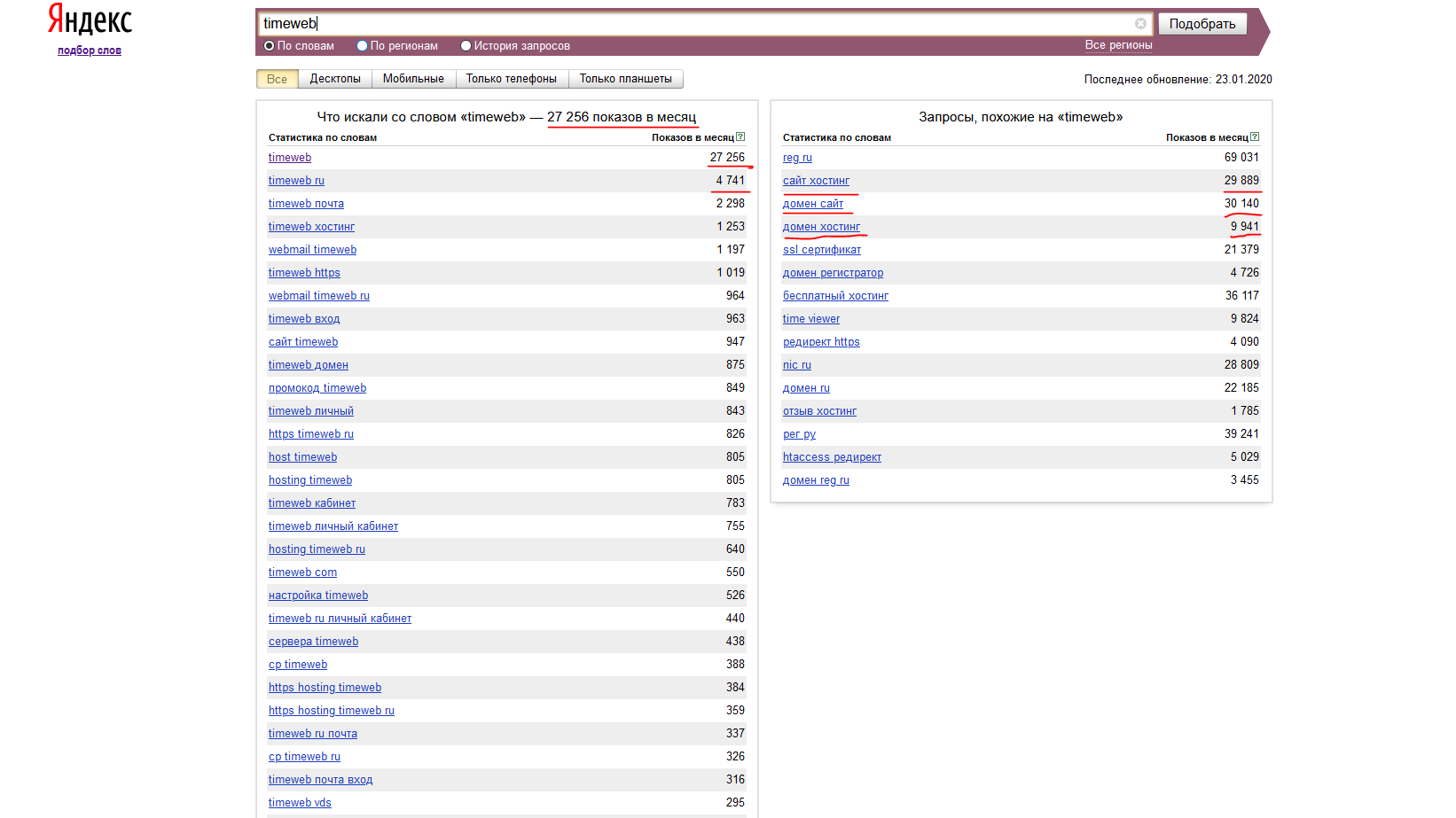 Вот такой список мы получаем. Слева — синонимичные запросы. Справа — похожие запросы. К каждому ключу прилагается количество показов в месяц. А сверху над списком есть кнопки для установки фильтра по устройствам.
Вот такой список мы получаем. Слева — синонимичные запросы. Справа — похожие запросы. К каждому ключу прилагается количество показов в месяц. А сверху над списком есть кнопки для установки фильтра по устройствам.
Если на какой-то из приведенных ключевых запросов кликнуть, то сервис покажет статистику уже по этому слову.
Итак, суммируем.
Плюсы Яндекс.Вордстат:
- весьма точная статистика,
- похожие запросы, расширяющие семантику,
- поиск по регионам.
Минус Яндекс.Вордстат: cтатистика только по запросам в Яндексе, для Гугла нужно искать отдельно. У Google, кстати, есть свой сервис, называется он Google Trends.
Нужен ли продвинутый английский язык?
Это самый часто задаваемый вопрос по семантике.
Он необязателен для следующих задач:
- парсинг запросов;
- чистка запросов;
- анализ выдачи и конкурентов.
Сегодня все это легко можно переводить через сам Google или его переводчик, при этом параллельно изучая язык. Например, наша команда начинала без продвинутого английского. Мы дополнительно учились, ходили на курсы и развивали навыки языка.
Продвинутый английский язык необходим для:
- составления ТЗ копирайтеру;
- качественной группировки;
- более быстрой работы в целом. Находить несоответствие по ключам, общие группы и т. д. будет гораздо проще.
То есть английский язык необходим, но вполне можно начинать работать и без него, попутно его изучая.
Как подобрать ключевые слова для SEO
Процесс сбора семантики состоит из нескольких этапов. Для начала нужно определить маркерные запросы, охватывающие направление деятельности. Затем происходит расширение СЯ и чистка «мусора».
Определяем маркерные (базовые) ключи
К их числу относятся ключевые слова, которые точно описывают содержимое страницы. Обычно они имеют наиболее высокую частотность. От них отстраивается «хвост» запросов (например, «отзывы», «купить», «цена» и так далее). Часто маркерный запрос содержится в заголовках h1. Именно с них и начинается сбор всей семантики.
Выпишите в отдельном документе общие поисковые фразы, относящиеся к вашей тематике. Фиксируйте все идеи, которые пришли в голову, так как в будущем не нужные запросы все равно отсеются. Примерный список:
Теперь из этих запросов (они ВЧ) нужно получить СЧ и НЧ поисковые фразы, чтобы расширить семантику.
Расширяем семантическое ядро
Справиться с этой задаче можно через специальный софт (например, Key Collector) или сервис «Вордстат». Если направление вашей деятельности привязано к конкретному региону, то нужно выбрать это в настройках.
Нужно скопировать все ключи из левой колонки и просмотреть правую, возможно, и там будут фразы, полезные для продвижения. Полный список может насчитывать сотни или даже тысячи поисковых слов.
Чистка ключей
Самый сложный этап — удаление «мусорных» запросов. Вам придется избавиться от неподходящих или незаконченных фраз. Например, ключ «диетический торт». По сервису «Вордстат» у него всего 2 точных запроса в месяц по региону Зарайск.
Продвигать такие ключи нецелесообразно, так как доходы не окупят затраты. Поэтому лучше отсеивать ключевые фразы, у которых точная частотность меньше 10. Этот ключ подошел бы для СЯ, если бы имел большую частотность, и вы занимаетесь производством таких кондитерских изделий.
Что не стоит включать в СЯ:
- ключи с брендами конкурентов;
- ключи с несуществующими у вас услугами или продуктами;
- дубли ключей (например, «торты на заказ на корпоратив» и «торты на корпоратив на заказ» — один и тот же ключ);
- ключи с чужими регионами;
- слова с ошибками.
После того как вы очистите СЯ от ненужных фраз, переходите к их группировке. Объединяйте запросы, которые можно продвигать на одной странице.
Сервисы для сбора и кластеризации
Существует много онлайн-сервисов и десктопных программ для сбора и группировки семантики.
-
Key Collector
Основной инструмент при сборе ядра. Платная программа с бессрочной лицензией. Устанавливается на компьютер или ноутбук. Возможности Key Collector:
-
парсит (собирает) ключи из Wordstat, Google.Ads, Liveinternet.ru, «ВКонтакте» и других платформ.
-
собирает поисковые подсказки.
-
определяет актуальную частотность.
-
фильтрует ключи по стоп-словам и частотности.
-
находит релевантные страницы.
-
проводит группировку (кластеризацию) запросов.
-
-
Онлайн-инструменты Пиксель Тулс
Здесь есть сразу несколько инструментов для работы с семантикой.
В модуле «Проекты» сервис автоматически генерирует базовый набор ключей для сайта. Его можно дополнять, загружая слова из других источников.
Другие полезные инструменты для работы с ядром от Пиксель Тулс:
-
Комплексная оценка запросов. Сервис определяет интент, то есть желание/намерение пользователя.
-
Группировка запросов по ТОПу. Инструмент определяет позиции сайта, частотность, анализирует ТОП и распределяет запросы, определяя релевантные URL.
-
Детальный анализ запроса. Оценивает важные параметры фразы: геозависимость, слова из подсветки, частотность, число главных страниц в ТОП, средний возраст документов и другие.
-
Вместе с запросом ищут… Инструмент находит похожие ключи.
-
Получение семантики по домену. Сервис парсит фразы сайтов-конкурентов.
-
Получение данных из Яндекс.Вордстат. Инструмент собирает ключевые слова, их историю, анализирует частотность.
-
Список запросов из Яндекс.Вебмастера. Выгружает ТОП-500 запросов по данным сервиса Вебмастер.
-
Лемматизация и удаление дублей фраз. Удаляет условно одинаковые ключи с учётом лемматизации (то есть приводит слова к лемме — нормальной, словарной форме слова).
-
-
Key Assort
Еще одна платная десктопная программа. Автоматически кластеризует ядро (делит на группы), создает структуру проекта на основе семантики, находит лидеров ниши. Программа не парсит ключи, а работает с уже собранными запросами.
-
Keys.so
Платный онлайн сервис с широким функционалом:
-
Анализирует сайты конкурентов: трафик, позиции, поисковые запросы.
-
Сравнивает конкурентов по позициям, видимости, посещаемости.
-
Позволяет выгрузить активную семантику конкурента или сразу нескольких конкурентов (создает групповой отчет со списком ключей).
-
Парсит рекламные кампании в Яндекс.Директ, Adwords.
-
Модуль «Семантическое ядро» создает СЯ с помощью древовидных структур и автоматической кластеризации. Есть возможность выгружать в сервис дополнительные ключи, группировать их в ручном режиме.
-
-
Serpstat
По функционалу сервис напоминает Keys.so. Есть платная и бесплатная версии. Тоже парсит ключи конкурентов и делает автоматическую кластеризацию, но есть отличия.
-
Собирает все виды запросов: брендовые, информационные, коммерческие, навигационные.
-
При анализе выдачи показывает, есть ли в ТОПе соцсети и колдунщики.
-
В отчете отображается ориентировочный трафик по ключам.
-
-
Мутаген
Платный сервис, который позволяет выгружать ключи конкурентов, их частотность.
-
Оценивает уровень конкуренции по запросу.
-
Собирает СЯ на основе запросов конкурентов. Работает только с геонезависимыми запросами, поэтому подходит не всем коммерческим проектам.
-
Расширяет ядро. Находит ключевые слова, по которым показываются те же страницы, что и по заданным фразам.
-
Оценивает параметры ключа (частотность, позиции, хвосты, LSI фразы).
-
Автоматически кластеризует ключи.
-
Парсит Вордстат.
-
-
SpyWords
Еще один популярный платный сервис, который работает с ключами сайтов-конкурентов. Возможности SpyWords:
-
Анализирует и сравнивает конкурентов.
-
Подбирает эффективные запросы конкурентов для SEO-продвижения и рекламных кампаний.
-
Разбивает ядро на кластеры.
-
Как пользоваться группировкой?
Для определения релевантных страниц нужно ввести доменное имя сайта, список поисковых запросов, который требуется кластеризовать, и поисковую систему.
Далее — выбрать метод обработки, регион, степень группировки, в чек-боксах проставляются необходимые галочки и нажимается кнопка «Проверить».
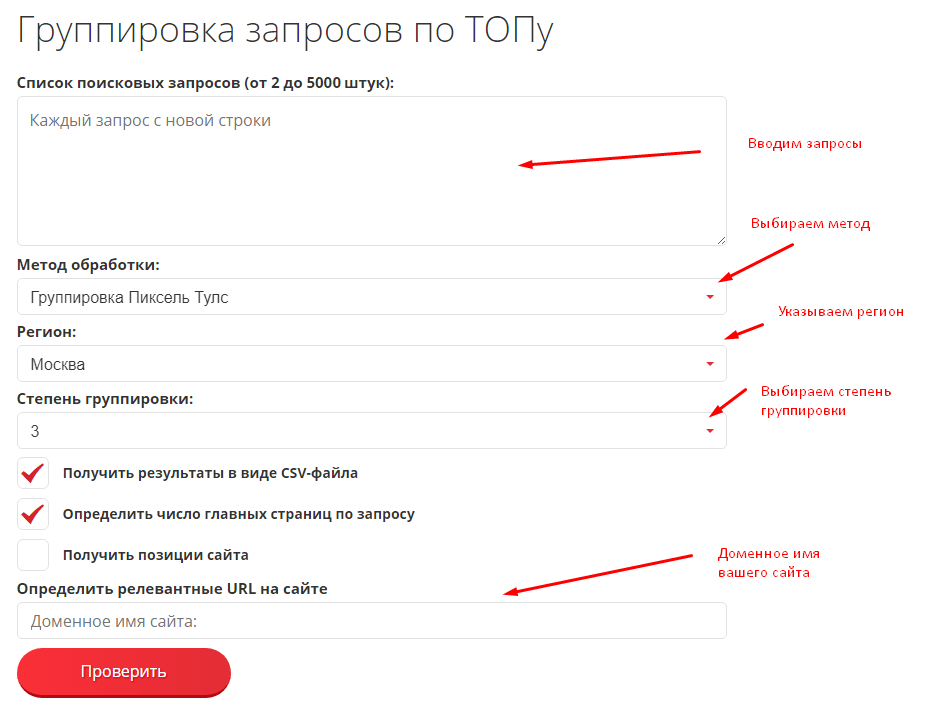
Список поисковых запросов (ключевых слов), которые можно кластеризовать по ТОПу бесплатно за один раз, достаточно велик — до 5000 фраз.
При работе доступно четыре метода кластеризации. Первые три — вполне традиционные и привычные для SEO-специалистов, четвертый — авторская разработка:
-
Сильная связь в группах (так называемый Hard-метод).
-
Средняя связь в группах (Middle).
-
Слабая связь в группах (Soft).
-
Метод «Пиксель Тулс» — уникальный алгоритм, который умеет классифицировать запросы и обеспечивает более точную группировку, так как результаты выдачи по каждой фразе подвергаются предварительной фильтрации — удалению крупных справочников («Википедия» и прочие из «чёрного списка»), витальных URL, результатов, полученных с помощью алгоритма СПЕКТР и прочих примесей, которые не являются органической выдачей поисковой системы Яндекс и искажают исходные данные.
При продвижении по трафику можно использовать Soft-метод, так как в этом случае не требуется 100% выводимость запросов в группах, а ставка идёт на их количество.
Если же задача вывести максимум фраз из семантического ядра проекта на первые строчки выдачи — рекомендуется использовать метод группировки «Пиксель Тулс».
В кластеризаторе доступно быстрое определение релевантных URL сайта и возможность получения количества главных страниц в выдаче по запросу, что позволяет в дальнейшем скорректировать распределение.
Степень или сила группировки ключей может варьироваться. Рекомендуемая степень равна трем, она введена по умолчанию.
Обычно её достаточно для получения оптимальных результатов. Если группы получаются довольно малочисленные, а список достаточно обширный — число можно снизить до двух.
Сила / степень — количество одинаковых URL, которые должны встретиться в выдаче по двум запросам, чтобы алгоритм мог ассоциировать их в группу.
Сервис бесплатно хранит предыдущие результаты в таблице, которую можно скачать в CSV, переименовать, либо удалить.
Что делать с семантикой после построения СЯ
- Сбор СЯ – вы собираете актуальные для вашей аудитории ключевые фразы.
- Процесс кластеризации – разбиваете их на кластеры по темам.
- Оптимизация — пишите под каждый кластер отдельную статью, добавляя основной ключ в метатеги тайтл и дескрипшен.
Если вы все будете делать правильно, то поисковики признают ваш ресурс полезным и он неминуемо взлетит в поисковой выдаче.
Семантика очень важна, но сегодня поисковые роботы обращают большое внимание на поведенческие факторы ресурсов, поэтому не менее важно, чтобы у сайта была понятная структура, удобная навигация, хорошее юзабилити. О том, как создать современный сайт, читайте здесь
Сервисы для парсинга и кластеризации
Опытные оптимизаторы используют для сбора семантики платные программы и сервисы. Новичкам рекомендуем воспользоваться бесплатными ресурсами, которые предоставляют базовые услуги.
С помощью готовых баз и парсеров экономится время: например, стоп-слова отражаются автоматически, отсеивание ключей определяется особенностями отрасли. Собирая семантику вручную, стоп-слова приходится отбирать самостоятельно для каждой тематики, учитывая интересы, тематику и цели компании.
Яндекс.Вордстат
Популярный бесплатный инструмент для сбора и расширения семантического ядра. Минусы для SEO-специалиста в том, что нужно постоянно вводить капчу, что, в общем, отнимает много времени и по одному запросу сервис показывает не более 41-й страницы, что для высококонкурентных тематик крайне мало.
Правая колонка содержит альтернативные фразы, а в колонке слева находятся ключи, с помощью которых можно углубиться в тематику и найти «хвосты».
Помимо «Вордстата» маркерные ключи подбираются при помощи «Яндекс.Вебмастер» и «Яндекс.Метрика». В «Метрике» есть раздел «Поисковые запросы», который содержит популярные запросы, по которым пользователи переходят на сайт.
Key Collector
Платный сервис, автоматизирующий сбор семантики при помощи Yandex.Wordstat, Google Ads и других. Сервис обеспечивает чистоту семантики (без стоп-слов и лишних фраз), сортирует и фильтрует ключи, опираясь на их частотность (можно собирать как все типы ключей, так и, к примеру, только высокочастотные).
К достоинствам программы можно отнести работу с разными источниками, что обеспечивает большую глубину сбора данных. Также сервис выполняет кластеризацию семантического ядра. К недостаткам софта SEO специалисты относят медленную работу при большой нагрузке, необходимость приобретения антикапч для ускорения процесса парсинга.
Лицензия на использование программы стоит для физических лиц 2200 рублей, а если вы юридическое лицо, то придется заплатить всего на 100 рублей больше.
MOAB. Tools Семантика
Сервис работает онлайн, не нужно скачивать никаких программ. Парсит данные для семантики из «Вордстата» и подсказок. Попадают даже длинные запросы с «хвостами». Поиск не требует ввода капчи, а выполненную работу можно интегрировать с Key Collector. Сервис сразу определяет частотность.
Инструмент позволяет определить 5 000 запросов бесплатно. Если вы начинающий оптимизатор, то вам подойдет тариф Mini, который стоит 1 299 рублей. Ядро рассчитано на 50 000 фраз. Если семантика собирается для большого проекта, то воспользуйтесь тарифом Pro, который рассчитан на 500 000 фраз. Цена — 6 099 рублей.
Yandex Wordstat Assistant
Речь пойдет не о привычном для нас «Вордстате», а о бесплатном дополнении, которое копирует и размещает полученные результаты в Excel. Это браузерное дополнение, которое не нуждается в установке на компьютер. Сервис в автоматическом режиме находит дубли и позволяет вставлять фразы вручную. Полезный инструмент, который должен быть на вооружении у всех оптимизаторов, работающих с инструментами «Яндекс».
Serpstat
Дорогой, но результативный сервис, позволяющий собрать и сгруппировать поисковые фразы. Сортирует ключи по показателям частотности и конкурентности. Таким образом, по шкале от 1 до 100, можно определить, насколько ресурсозатратным может оказаться продвижение ресурса. Ресурс отображает ключи по региональной выдаче. То есть, как и в Вордстате, показывает, в каком регионе пользователи какие запросы вбивают.
У программы есть бесплатная версия, но она малорезультативная. Самый дешёвый тариф стоит 55 долларов.
Как использовать готовое семантическое ядро
Когда вы сделали кластеризацию, ядро готово к использованию. Собранная семантика позволяет:
- Создавать структуру сайта. На основе СЯ создаются страницы и разделы ресурса. Поисковые системы лучше индексируют такой сайт, а пользователи быстрее находят на нем нужную информацию.
- Делать контент. Используйте ключи, когда пишете материалы для сайта. Запросы помогают создавать полезный контент, который отвечает на вопросы людей и приводит к вам целевой трафик.
- Оптимизировать теги. Ключи используют для создания важнейших мета-тегов: основного заголовка (title) и описания страницы сайта (description). Поисковики сканируют эти элементы страниц и учитывают их при индексации. Правильно прописанные title и description улучшают позиции ресурса.
- Запускать контекстную рекламу. В платной выдаче Яндекса и Google ключи применяются для контекстной и баннерной рекламы. Чтобы собрать рекламные объявления, можно взять кластеры, которые вы подготовили для SEO, или же сделать отдельную сортировку ключей.
- Продвигать визуальное содержание. Если вы вставляете ключевые слова в названия и alt-теги изображений, то это повышает вероятность их появления в разделе «Картинки» у поисковиков.
Serpstat
Комплексная SEO-платформа для сбора поисковых фраз по ключевым фразам и доменам сайтов. Количество баз регионов постоянно увеличивается, а инструментарий не сводится только к расширению семантики.
С помощью Serpstat можно определить конкурентов сайта, узнать ключевые слова, по которым их можно найти в поиске, и выгрузить этот список для использования в собственной семантике.
Достоинства сервиса:
- разнообразный инструментарий;
- удобные отчеты, включающие частотность фразы по конкретному региону;
- возможность выгружать ключевые слова для отдельной страницы сайта.
Недостатки:
- база сервиса постоянно обновляется и дополняется, но между ее апдейтами нельзя гарантировать точность частот запросов;
- данные по некоторым низкочастотным запросам могут отсутствовать;
- сервис пока работает с ограниченным количеством стран и языков.
Услуги по сбору семантического ядра
В данной отрасли можно найти не мало организаций, которые готовы предложить вам услуги по кластеризации. Например, если вы не готовы тратить время на то, чтобы самостоятельно изучить тонкости кластеризации и выполнить ее собственными руками, то можно найти множество специалистов, готовых выполнить эту работу.
Yadrex
Yadrex — одна из первых на рынке, кто начал использовать искусственный интеллект для создания сематического ядра. Руководитель компании сам профессиональный вебмастер и специалист по SEO технологиям, поэтому он гарантирует качество работы своих сотрудников.
На сайте, вы можете самостоятельно рассчитать стоимость создания сематического ядра для вашей задачи.
Кроме того, вы можете позвонить по указанным телефонам, чтобы получить ответы на все интересующие вас вопросы относительно работы.
Заказывая услуги, вы получите файл, где будут указаны группы содержания ядра и его структура. Дополнительно вы получаете структуру в mindmup.
Стоимость работы варьируется в зависимости от объема, чем больше объем работы, тем дешевле стоимость одного ключа. Максимальная стоимость для информационного проекта будет 2,9 рублей за один ключ. Для продающего 4,9 рублей за ключ. При большом заказе предоставляются скидки и бонусы.
Как это сделать на практике
- выгрузка запросов из Яндекс.Вебмастера и Google Search Console
- выгрузка запросов из Яндекс.Метрики и Google Analytics
- выгрузка запросов из готовых баз (Букварикс, Пастухов)
- выгрузка запросов из сервисов анализа конкурентов (Megaindex, Serpstat, Spywords)
3. Все найденные запросы лемматизируем и производим сортировку по встречаемости лемм в запросах. Есть множество бесплатных инструментов для этого, удобнее всего сделать в Key Collector, инструменте «Анализ групп». Более продвинутый вариант – с сортировкой по суммарной частотности запросов с использованием каждой леммы, но это требует сбора частотности по всем запросам.
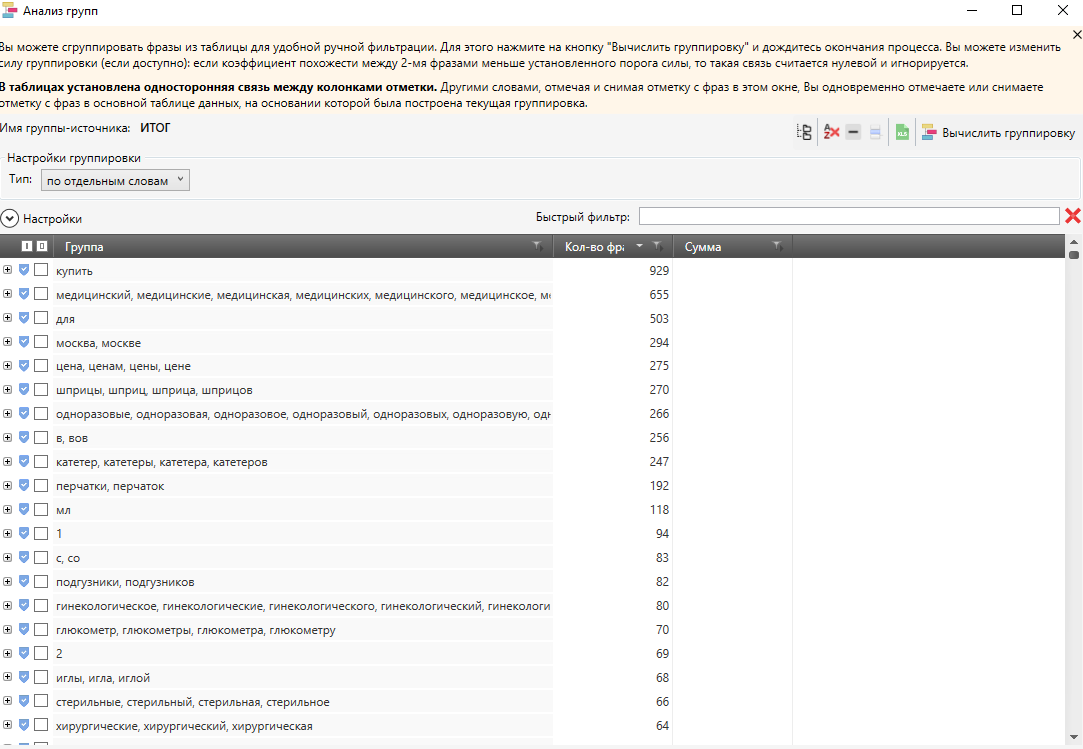
Леммы для сайта медицинских товаров
4. Определяем вручную для каждой леммы, чем она является:
- название товара/услуги
- уточнение товара/услуги
- транзакционные и тематические слова/действия/топонимы
5. Используем их в шаблонах для дальнейшей оптимизации сайта:
- уточнения товаров/услуг – это потенциальные новые страницы: разделы и тегирование;
- транзакционные и тематические слова/действия/топонимы – это слова для использования в шаблоне оптимизации (title, h1, текст, блоки и т.д.).
Лемм может быть очень много, именно поэтому они изначально отсортированы по встречаемости. Чем больше лемм будет проработано по такому списку, тем глубже погружение в тематику.
Анализ конкуренции запросов для информационных сайтов
Собрав запросы и почистив их теперь нам надо проверить их конкуренцию, чтобы понимать в дальнейшем — какими запросами надо заниматься в первую очередь.
Конкуренция по количеству документов, title, главных страниц
Это все легко снимается через KEI в KeyCollector. Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
В интернете можно встретить различные формулы расчета этих показателей, даже вроде в свежем установленном KeyCollector по стандарту встроена какая-то формула расчета KEI. Но я им не следую, потому что надо понимать что каждый из этих факторов имеет разный вес. Например, самый главный, это наличие главных страниц в выдаче, потом уже заголовки и количество документов
Навряд ли эту важность факторов, как то можно учесть в формуле и если все-таки можно то без математика не обойтись, но тогда уже эта формула не сможет вписаться в возможности KeyCollector
Конкуренция по биржам ссылок
Здесь уже интереснее. У каждой биржи свои алгоритмы расчета конкуренции и можно предположить, что они учитывают не только наличие главных страниц в выдаче, но и возраст страниц, ссылочную массу и другие параметры. В основном эти биржи конечно же рассчитаны на коммерческие запросы, но все равно более менее какие то выводы можно сделать и по информационным запросам.
Собираем данные по биржам и выводим средние показатели и уже ориентируемся по ним. Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Для более наглядного вида можно применить формулу KEI, которая покажет стоимость одного посетителя исходя из параметров бирж:
KEI = AverageBudget / ( AverageTraffic +0.01)
Средний бюджет по биржам делить на средний прогноз трафика по биржам, получаем стоимость одного посетителя исходя из данных бирж.
Конкуренция по мутаген
Сервис мутаген создан специально для анализа конкуренции информационных запросов. Работает с 2011 года, принцип алгоритма не разглашается, но вполне себе годно рассчитывает. Конкуренция рассчитывается по 25 баллам. Чем больше балл, тем больше конкуренция: 1-7 низкая конкуренция, 8-15 средняя, 16 и выше, высокая. Сервис платный, но в день можно чекать 10 запросов бесплатно. Тут сразу показываются просмотры по вордстату, ключи хвосты, клики в яндекс директ. В KeyCollector есть возможность массового сбора по мутаген.
В KeyCollector есть возможность массового сбора по мутаген.
Выводы: Если у вас бюджет ограничен то вы можете использовать первые два способа проверки конкуренции в совокупности, если готовы тратиться на анализ, то можно использовать только Мутаген или Оверлид.