Как инструмент «парсинг поисковых подсказок» поможет в работе seo-специалиста?
Содержание:
- Обработка результатов#
- Как получить список поисковых подсказок?
- Как выглядит поисковая строка
- Какие есть парсеры для Вордстата?
- Парсинг подсказок
- Принципы работы баннерной рекламы в подсказках Яндекса
- Какие задачи помогает решить парсер?
- Формирование поисковых подсказок
- Поиск через браузеры
- Настройки сбора и видео
- Как поисковик формирует подсказки
- Как работают парсеры поисковых запросов
- getTaskResultsFile#
- Алгоритм работы парсера
- Парсеры поисковых систем#
- A-Parser — парсер для профессионалов#
- Редактирование формата результата#
- Советы специалистам и предпринимателям, занимающимся продвижением самостоятельно
- Представление результатов#
- Бесплатные парсеры
- Настройка#
- Обзор парсера SE::Google::KeywordPlanner#
- Примеры запросов#
Обработка результатов#
A-Parser позволяет обрабатывать результаты непосредственно во время парсинга, в этом разделе мы привели наиболее популярные кейсы для парсера SE::Yandex::Suggest
Опция Парсить до уровня (Parse to level)
Опция указывает парсеру переходить по соседним страницам сайта в глубину до указанного уровня, например:
- Если указан 1-ый уровень то парсер перейдёт по всем ссылкам указанным на исходной странице
- Если указан 2-ой уровень то парсер перейдёт по всем ссылкам указанным на исходной странице + по всем ссылкам собранным со страниц на первом уровне
- и т.д.
Простыми словами — это минимальное число кликов между исходной страницей и конечной
Т.к. на соседних страницах скорее всего будут ссылки на исходную страницу или повторы ссылок, то для того чтобы парсер не зациклился, и не ходил по кругу, необходимо обязательно включать уникальность запросов (Unique queries)

Скачать пример
eJx1VFtv2jAU/iuRhdRVYohSeFjeKBrSJlZYaR8m4MGrD5FXx85sh1FF+e89xwlJ
WOmL5XP7zncudsE8dy9uZcGBdyzeFCwLdxaz9dc4/sW1gGMcr/MkAeejz9GKWweR
N5GCA6gIjjzNFLA+y8hgCWNzKRQ9BOx5rvBWMP+aAaYwB7BWCgqXAuW9sSn3SCC4
sQNXObn1Ko0bVPZPVz1XgW63+uqalR3AzEuj3QkvcFoQ0RbtZlh+TEDZTtrRaMLK
3a7P6vTzkJ34ZDeDuk2Ncc0P8GioBhnacYpB6Z6noQrBPZD1VMb1wB8JgQshiTZX
VQbqYZv1Scu/gY7zVuoE/VG0EtzcmhTVHgIIKV9PDDesF2SGMHmI/1nFsNjbHPrM
Ids5Ry6iMey5cmiRHiz3xi7rTsYFM3qqVOhi6xbg73KpBM58usegb3XgZZflO4yy
qbCbCufxzyKHBiVId8sfbZQwC5Ng4dpg2Uqm0qPsZibXNJshKl8AsqZt9+SWGgtN
mhq5zo67n4Gm4bdTm2at6qyMs8mcK5+N3stkWS/UyTPXj/jAlnpm6JlQXTpXCqfi
4KHdkKmrx0BCS/D/4FlIgbSal8S8Mcp9X1dUMytxAydEMMVOdrPWkM9cqaeHRdfC
2o1CYZsPx+MhnbeTcB937pU+nONRFAQIpwjn79Z8+6XSM0rpITG4i9iQctf8E82X
U1z8LeKixFH/cavKm/pCvqjDBjucIz7k8g0dHqJw
Скопировать
Фильтрация результатов (использование минус-слов)
Использовав минус-слова возможно стразу убирать реультаты которые вам не нужны.
Аналогично используя фильтр можно и оставлять только те результаты которые содержат нужные слова.

Скачать пример
eJx1VFtv0zAU/iuVNWlMGlWvEuStq6gEKutYuwfU9sFrToKZYwfbKZ1C/jvHl1zK
yot1rt+5uySG6hf9oECD0STaliR3NInI+lMUfacihlMUrYs0BW1673sLxg2oHpxo
lnMgtySnSoOyvttLLmgRQ0ILjlRJzGsOCC2PoBSLrTuLkU+kyqjBwM6MHCkvrNmV
l+i+17+7vtIedLcT1zek6gDmhkmhazyX0xKOwFu04aD6fwJcdcKORtMuduIqRn3I
L9oGyoYLCZH9bbDbeCcFQhrM+fCjA7wrBpPJxL7jD+59dpKDow9/HDN0zNTRg46p
p5+d0XjUUUxah7Gtx7cCo5Fqv6+T1gvXQdvTfNgPI26Ua3qEjfSlQivGUcM9zdwk
YmrAautR3PTNySLQOGY2HuU+gt2DNuqTYL9c5dooJlK0R1Yx0AslMxQbcCBW+Fpn
uCVXjrctLZz/N+9DIqMKwJZjtguKucSNIqFco4Zh/6mRahW2ISqJFDPO3Sa0Zg7+
rmA8xr2dJej0OTheNlm9waiaCruhcKd+K8yhQXHc3epr6xXLpUyxcCGxbM4yZpDX
c1kIO5sBCl8A8qZt99YskwqaMAE5RMe7zUHYBW6nNstb0VkZZ5M5Fx6kSFi6CkdR
WxZig5/DSsylPXVblyg4x6loeGw3ZKbDGCzTJviv89yFwLSa34AYKbn+svap5orh
Bk5tghl2shs1QB4o50+Py66GtBtVn9egcz+TN7fk3smo56/FvXF7ieHIPno5sSEN
pBJ3ERtS7Zu/rvkuy4s/XlRWOOqf+sFb275YW5Rhg7U7zmH1F8zL3Bw=
Скопировать
Как получить список поисковых подсказок?
Самым простым и очевидным способом получения такого списка является использование блока дополнительного поиска от Google «Вместе с… часто ищут». Достаточно ввести интересующий вас запрос в поисковую строку и посмотреть, что же ищут пользователи вместе с ним. Вот такие дополнительные ключевые фразы показал нам Google для поискового запроса «детская одежда».

Однако такой способ неудобен по двум причинам:
К каждой ключевой фразе поисковик покажет не более десяти поисковых подсказок, что несоизмеримо мало;
Невозможно выгрузить результаты сразу по нескольким ключевым запросам — нужно каждую ключевую фразу вбивать отдельно, что слишком долго.
Существует множество бесплатных инструментов, которые парсят подсказки поисковых систем Яндекса и Google, расскажем о нескольких из них:
1
Ubersuggest — удобный сервис для подбора поисковых подсказок Google. Позволяет спарсить семантику из поиска по изображениям, видео, новостям, однако не предоставляет «секретной статистики» поисковой системы. Все, что требуется — это ввести ключевик в поиск, задать язык и вертикаль поиска:

Сервис помогает узнать, что «пользователи также ищут» вместе с вашими ключевыми словами. Дополнительные ключевые слова или фразы от введенного вами ключевика разделяются знаком «+». Они отсортированы по алфавиту, а сам отчет по ключевой фразе выглядит следующим образом:
2
Keyword Tool — бесплатный сервис для поиска ключевых фраз, основанный на поисковых подсказках Google для разных языков (83) и регионов Google (192 базы данных). Кроме того, семантику можно подобрать из YouTube, Bing и AppStore. Вводим в поиск сервиса необходимое ключевое слово, выбираем базу данных, язык и нажимаем кнопку поиска:
Получаем результат:

3
Словодёр. Для автоматического сбора поисковых подсказок Яндекс, а также других поисковых систем (Google, Mail, Rambler, Yahoo, Nigma) можно использовать данную программу. Она работает через прокси-сервер и работает сразу с несколькими поисковиками — то есть здесь анализируются данные со всех отмеченных поисковых систем. Скачайте программу, запустите ее, в появившемся окошке введите ключевую фразу и выберите поисковик. После нажатия кнопки «Парсить», получите следующие результаты:

Данные можно экспортировать в формате txt.
Как выглядит поисковая строка
В поисковых системах
Вот так выглядит поисковая строка Яндекса.

После ввода запроса следует нажать кнопку “Найти”, и наслаждаться результатом отбора. После ввода запросы можно уточнить результаты, выбрав кнопку расширенного поиска.
Расширенный поиск позволит отобрать наиболее релевантные результаты.

Поисковик предусматривает работу с различными фильтрами (поиск по времени, картинкам, новостям и т.д.). С помощью них вы можете уточнить запрос: ввести ограничение по региону, словоформе, определенному интернет-сайту, типу файла, языку, дате обновления веб-страницы и т.д. Активные фильтры изменяют цвет, поисковик при этом дает выдачу автоматически, согласно заданным условиям.
Под строкой поиска есть дополнительные быстрые фильтры. Вы можете искать только картинки, информацию на картах и т. д.
Зарубежный поиск Google мало чем отличается от своего российского конкурента.
Для поиска необходимо ввести также ключевой запрос.

В Google можно также работать с системой быстрой фильтрации поиска (горизонтальное меню под строкой).

Расширенный поиск Google также поможет уточнить поисковый запрос и выдаст наиболее точную информацию. Для навигации применяется система пояснений.

Какие есть парсеры для Вордстата?
Обработка запросов в ВордСтат возможна только в ручном режиме. Это увеличивает время формирования семантического ядра (СЯ) даже для небольшого проекта. Для автоматизации разрабатывают программы и онлайн-сервисы – парсеры. Они собирают данные статистики Яндекс, используя технологию API и другие программные комплексы. В итоге пользователь может обрабатывать большой объем информации.
Цель работы парсеров – актуальная статистика ключевых фраз с возможностью углубленного анализа по параметрам. Это реализуется следующими способами:
- Программы. Сбор актуальной статистики WordStat, анализ по критериям пользователя. Условия использования – условно-бесплатное или платное.
- Онлайн-сервисы. По сравнению с программами обладают меньшим функционалом. Преимущества – экономия времени, не нужно устанавливать ПО.
- Специализированные программы. Разрабатываются для решения узконаправленных задач.
Выбор зависит от объема запросов и точности результатов. Онлайн-сервисы скачивают данные из Яндекса, чтобы уменьшить время формирования отчета. Поэтому информация не объективная. На это влияет частота обновления баз конкретного парсера.
Парсинг подсказок
Одним из самых популярных парсеров для SEO-специалистов является Key Collector.
Для сбора поисковых подсказок в этой программе достаточно нажать на следующую пиктограмму:

В открывшемся окне можно выбрать поисковую систему, у которой необходимо спарсить поисковые подсказки. Также есть возможность включить функцию подбора окончания слова:

В настройках парсинга подсказок доступны следующие настройки:

-
- Глубина парсинга — количество итераций сбора поисковых подсказок. Т.е. если этот показатель установлен на 0, то будет произведен единичный сбор подсказок по заданным настройкам. Если 1 — то система будет собирать подсказки по каждой фразе, собранной в первый раз, что сильно увеличивает время парсинга. Поэтому рекомендуется ставить значение не более 0.
- Галочка в пункте «Собирать только топ подсказок» равнозначна простому ручному вводу фразы без пробелов. Т.е. подсказок будет мало, на парсинг будет произведен крайне быстро.
- Набор символов для перебора окончаний позволяет определить необходимые символы для этой цели: кириллица, латиница и цифры. Например, при вводе слова «подсказ», система будет автоматически подставлять выбранные символы. В итоговый список подсказок попадут и фразы, содержащие «подсказок», и подсказки». Очевидно, что данная опция необходима при изначальном задании неполных фраз.
- Набор символов для перебора фраз позволяет установить необходимые символы для перебора в конце фразы через пробел. Например, когда проставлены все три галочки, при вводе слов «подсказка», программа будет перебирать «подсказка а», «подсказка б», «подсказка в»…, «подсказка a», «подсказка b», «подсказка c»…, «подсказка 0», «подсказка 1», «подсказка 2»…
- Подставка выбранных букв перед заданной фразой позволяет сделать подставки не только в конце, но и перед исходной фразой через пробел. Т.е. в вышеприведенном примере «а подсказка», «б подсказка», «в подсказка» и т.д.
- Настройка задержек между запросами позволяет регулировать время ожидания между запросами, отправляемыми программой. Не следует настраивать слишком маленькое время, так как за быстроту парсинга можно расплатиться блокировкой IP-адреса.
- Количество потоков определяет, во сколько потоков будет происходить парсинг подсказок. Не рекомендуется ставить это значение больше 1. Подробнее о настройке количества потоков и прокси-серверов написано здесь.
Тогда как раньше регион ПС Яндекс можно было выбрать из окна настроек парсинга поисковых подсказок.
Подсказка:
Для определения наиболее эффективных подсказок — собирайте их точную частотность — «», а не общую: 
Принципы работы баннерной рекламы в подсказках Яндекса
Баннер в подсказках состоит из логотипа и небольшого количества текста. Столь лаконичное оформление в стиле результатов поиска позволяет воспринимать его не как рекламу. И это существенно повышает эффективность. А теперь плохая или хорошая новость, кому как. Настроить баннер в подсказках невозможно, он запускается автоматически. Как объясняют специалисты Яндекса, для показа выбирается реклама с самыми высокими CTR, ставками за клик коэффициентом качества и так далее.
Проще говоря, в саджесте размещаются объявления с первого места премиум-блока. Но не всё, что попадает в премиум-блок, стопроцентно окажется в подсказках. Премиальные показы, увы, ничего не гарантируют. Помимо премиум-размещения, ваша реклама должна обладать максимально высоким CTR и отличаться достаточно высокой ставкой. Иными словами, рецепт такой — постоянно повышать ставки на ключевые для вас запросы и увеличивать показатель кликабельности. Тогда шансы очень высоки.
 Пример баннера в подсказках
Пример баннера в подсказках
При этом стоит иметь в виду следующие вещи:
- Вся статистика по этому размещению будет доступна в разделе «Спецразмещение». Помните, мы говорили о том, что баннеры будут попадать туда из премиум-блока?
- Если ваша реклама стала баннерной подсказкой, то она уйдет с первой позиции размещения. Эту позицию займет ваш конкурент.
- Ваше объявление никогда не станет подсказкой, если следующее наиболее вероятное слово в запросе вы заминусовали. Например, «как дешево купить квартиру».
- Если ваше объявление попало в саджест, убрать его оттуда нельзя, размещение полностью автоматическое.
Надеемся, с баннерами всё понятно, и вам есть над чем поработать. Если нужны ещё гайды по тому, как занять премиальное место, можете посмотреть про особенности автоматического управления ставками в нашем материале. А вот по обычным подсказкам есть ещё два момента, которые можно обсудить. Первый из них — как всё-таки убрать подсказку из Яндекса.
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:
- Мониторинг цен. Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.
- Поиск товарных позиций. Полезная опция на тот случай, если сайт поставщика не дает возможности быстро и автоматически перенести базу данных с товарами. Можно самостоятельно «запарсить» информацию по нужным критериям и перенести ее на свой сайт. Не придется копировать данные о каждой товарной единице вручную.
- Извлечение метаданных. Специалисты по SEO-продвижению используют парсеры, чтобы скопировать у конкурентов содержимое тегов title, description и т.п. Парсинг ключевых слов – один из наиболее распространенных методов аудита чужого сайта. Он помогает быстро внести нужные изменения в SEO для ускоренного и максимально эффективного продвижения ресурса.
- Аудит ссылок. Парсеры иногда задействуют для поиска проблем на странице. Вебмастера настраивают их под поиск конкретных ошибок и запускают, чтобы в автоматическом режиме выявить все нерабочие страницы и ссылки.

Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Формирование поисковых подсказок
Поисковые подсказки формируются на основе сложных алгоритмов поисковых систем. Некоторые факторы, которые влияют на составление списка подсказок для запроса:
-
Частота поисковых фраз
. Как правило, поисковые системы предлагают самые популярные и высокочастотные «хвосты» к исходному запросу. -
Региональность
. В первую очередь, это относится к коммерческим запросам. Например, если пользователь ищет бетон в Санкт-Петербурге, ему не нужны подсказки с вхождениями других городов (но бывают и исключения). -
Персонализация
. Основывается на статистических данных пользовательских запросов, истории поиска и другой персонализированной информации, известной поисковой системе. -
Актуальность
. Особенно касается запросов, связанных с последними новостями. Поэтому подсказки регулярно обновляются.
Поиск через браузеры
Современные браузеры позволяют вводить запрос прямо в адресной строке.
В каждом браузере по умолчанию после ввода запроса открывается определенная ПС, изменить которую можно в его настройках.
Google Сhrome

Запрос можно ввести в одно из двух полей. Верхнее поле (это и есть адресная строка) в нашем примере автоматически подключит поисковую строку Google. Нижнее служит для удобства и расширяет функционал браузера. В нашем примере оно подключает поиск Mail. Работает полноценное окно подсказок, о которых мы расскажем ниже.
Mozilla Firefox
При вводе ключа реализован поиск посредством ПС Яндекс. Причем, всплывают только подсказки по вашему предыдущему поиску. Обращения к подсказкам ПС не происходит.
Opera

По умолчанию помогает в поиске зарубежный Google, помогая подсказками. Для удобства в самом интерфейсе веб-браузера установлены ссылки на несколько поисковых систем. Кроме того, искать что-то можно через саму адресную строку вверху.
Настройки сбора и видео
Ниже показаны простые настройки для парсинга, функция хранения истории сбора и видео по теме сбора подсказок в альтернативной поисковой системе Яндекс.
Теперь собирать подсказки в Google.ru (.com, .by, .ua и .kz) можно в один клик! Удачи в работе с инструментом.
Задайте вопрос или оставьте комментарий Вернуться назад
Будучи авторизованным в сервисе Google вы, наверняка, замечали, что при вводе любого запроса, появляется список подсказок. Достаточно одной или нескольких букв и Google уже «предугадывает» какой запрос вас интересует, исходя из вашей активности, региональности и наиболее релевантных запросов других пользователей. В этой статье вы узнаете, как удалить запросы в поисковой строке Гугл Хром, если вы не хотите, чтобы конфиденциальная информация попала не в те руки.
Как поисковик формирует подсказки
У каждой системы – Яндекса, Google и даже YouTube, принадлежащего Google, – свои собственные уникальные алгоритмы. Тем не менее можно выделить несколько общих факторов, влияющих на появление определенных поисковых подсказок:
Региональность
Поисковики учитывают географию пользователей при формировании поисковых подсказок. Особенно это касается запросов, начинающихся со слов «купить», «заказать», «доставка», «где» и т. д.
 Примеры подсказок по коммерческому запросу
Примеры подсказок по коммерческому запросу
Популярность и актуальность
Подсказки выдаются с учетом того, что сейчас в тренде, освещается в соцмедиа.
 Google не скрывает, что тренды определяют поисковые подсказки
Google не скрывает, что тренды определяют поисковые подсказки
Это легко проверить на практике. Просто возьмите пару недавних новостей из СМИ и начните вводить в поисковую строку имена героев, названия брендов или города, где произошли те или иные события. Подсказки реагируют быстро, в отличие от Яндекс.Вордстата и готовых баз ключевых слов.
Поисковое поведение
Поисковики учитывают интересы пользователей, часто посещаемые сайты, предыдущие запросы. Персонализация улучшает качество поиска.
 Если вы уже вбивали в Яндексе запросы, которые начинались точно также – таковые появятся в самом верху списка
Если вы уже вбивали в Яндексе запросы, которые начинались точно также – таковые появятся в самом верху списка
Как работают парсеры поисковых запросов
После того как вы собрали базу ключей и расширили ее с помощью Вордстат, можно воспользоваться платным сервисом, чтобы очистить значимые фразы и составить семантическое ядро. Рассмотрим, как это сделать, на примере Кей Коллектора
- Открываем «Файл» -> «Новый проект» и устанавливаем регион.
- Нажимаем «Пакетный сбор слов из левой колонки Yandex.Wordstat», копируем уже имеющийся список и нажимаем «Начать сбор».
Запросы с базовой частотностью (БЧ) ниже 5 являются мало запрашиваемыми и принесут мало трафика, поэтому их лучше удалить.
Чтобы автоматизировать этот процесс, перед началом сбора слов устанавливаем в настройках нижнюю границу БЧ, которая будет включена в конечный результат. 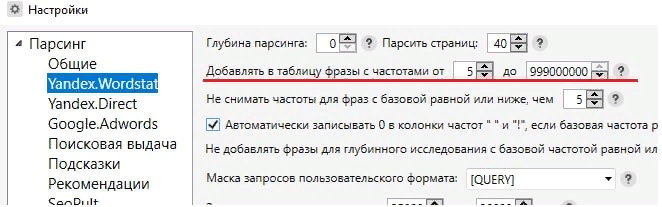
С помощью удобных программ и нехитрых действий вы сможете собрать базу ключей, даже если вы новичок.
Используете функцию парсинга ключевых запросов? Делитесь опытом в комментариях!
getTaskResultsFile#
Получение ссылки для скачивания результата по id задания. По полученной ссылке можно скачать файл только один раз, без авторизации (используется одноразовый токен).
info
Работает только со статичным именем файла и $datefile.format(). Для превращения динамичного имени файла результата в статичное можно использовать флаг шаблонизатора
Пример запроса
{
«password»»pass»,
«action»»getTaskResultsFile»,
«data»{
«taskUid»»181»
}
}
Скопировать
Пример ответа
{
«success»1,
«data»»http://127.0.0.1:9091/downloadResults?fileName=Mar-05_13-12-23.txt&token=wbvwlkes»
}
Скопировать
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
- Сначала пользователь указывает вводные данные для парсинга на сайте.
- Затем указывает список страниц или ресурсов, на которых нужно осуществить поиск.
- После этого программа в автоматическом режиме проводит глубокий анализ найденного контента и систематизирует его.
- В итоге пользователь получает отчет в заранее выбранном формате.
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах. Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
A-Parser — парсер для профессионалов#
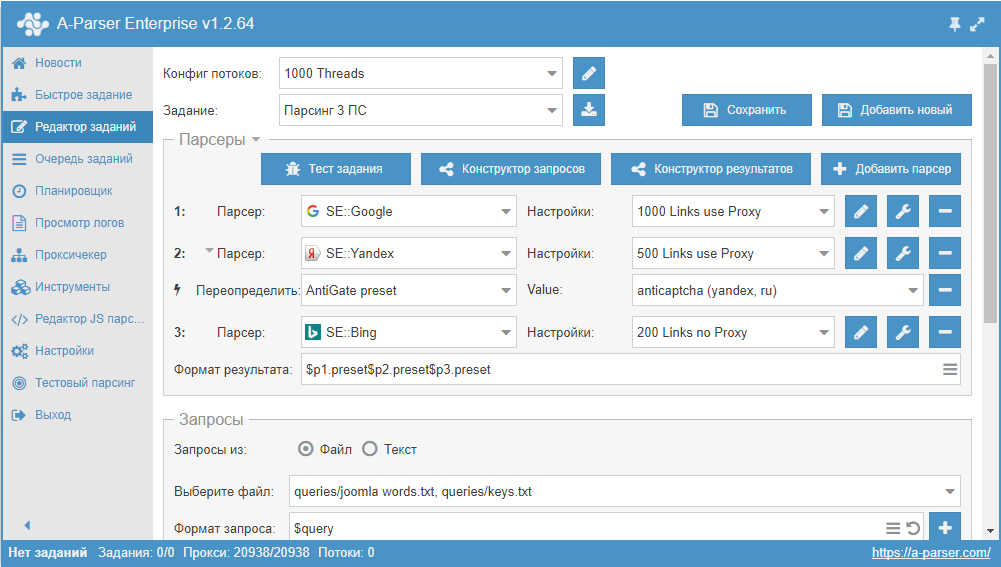
A-Parser — многопоточный парсер поисковых систем, сервисов оценки сайтов, ключевых слов, контента(текст, ссылки, произвольные данные) и других различных сервисов(youtube, картинки, переводчик…), A-Parser содержит более 90 встроенных парсеров.

Ключевыми особенностями A-Parser является поддержка платформ Windows/Linux, веб интерфейс с возможностью удаленного доступа, возможность создания своих собственных парсеров без написания кода, а также возможность создавать парсеры со сложной логикой на языке JavaScript / TypeScript с поддержкой NodeJS модулей.
Производительность, работа с прокси, обход защиты CloudFlare, быстрый HTTP движок, поддержка управления Chrome через puppeteer, управлением парсером по API и многое другое делают A-Parser уникальным решением, в данной документации мы постараемся раскрыть все преимущества A-Parser и способы его использования.
Редактирование формата результата#
Формат результата — позволяет форматировать результаты к нужному виду используя шаблоны, применяется для каждой комбинации запрос-результаты.
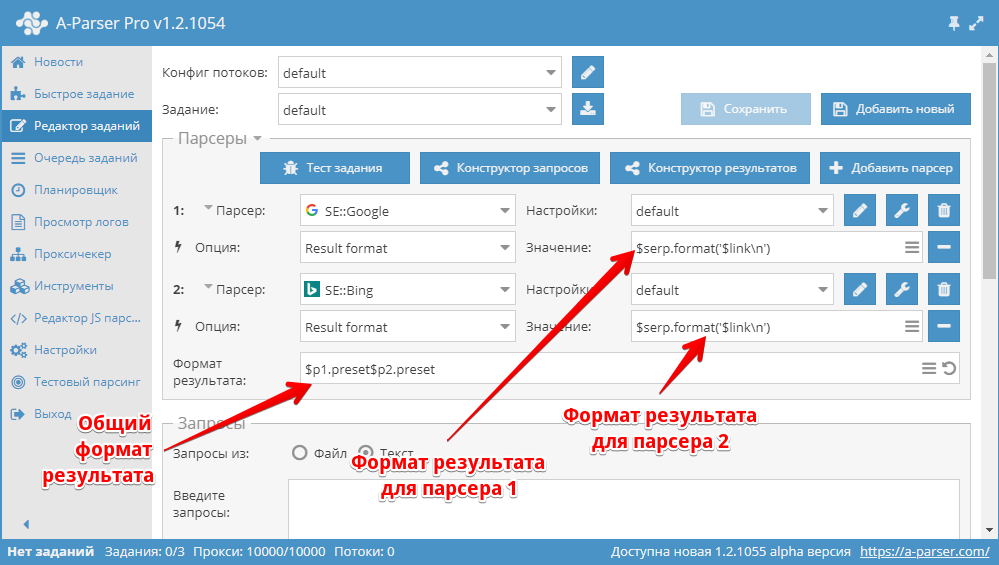
- Общий формат результата задается в поле
- Формат результата для каждого парсера отдельно можно задать в настройках парсера в
A-Parser поддерживает работу с несколькими парсерами в одном задании, в общем формате результатов необходимо указывать от какого парсера выводить результат:
- — результаты от первого парсера(SE::Google на скриншоте), — результаты от второго парсера(SE::Bing на скриншоте)
- Порядковый номер парсера отображается слева от поля выбора парсера
- и подразумевает что необходимо взять значение формата результата из настроек соответствующих парсеров
- В данном примере можно заменить на что будет иметь одинаковый эффект, при этом формат результата из настроек уже использоваться не будет
Формат результата можно указывать в удобном многострочном редакторе кликнув по соответствующей иконке в поле редактирования:
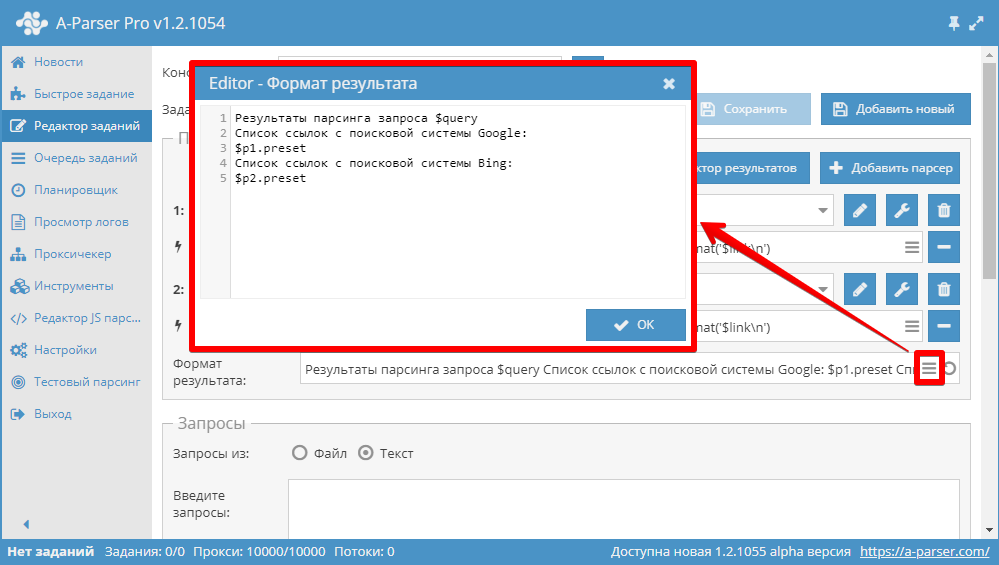
В общем формате результатов доступны следующие :
- — запрос после форматирования
- — все переменные относящиеся к запросу, описаны в статье
- — переменные для доступа к результатам парсинга для каждого парсера отдельно( для каждого парсера)
- — запросы после форматирования с учетом формата запроса указанного в настройках каждого парсера
Советы специалистам и предпринимателям, занимающимся продвижением самостоятельно
1 Лучше не собирать подсказки одновременно в трех системах, ведь у каждой из них свои алгоритмы. То, что подойдет для продвижения в Яндексе, может не подойти для оптимизации видео YouTube.
2 Выбирайте регионы с учетом местоположения целевой аудитории и географии продвижения. Для Яндекса и Google доступны все регионы РФ и соседних стран, для YouTube – только страны.
3 Если нужно просто быстро оценить семантику по заданному набору фраз, дополнительные опции и расширения не нужны.
4 Подсказки отражают реальные запросы пользователей, но не всегда: в отчете могут встречаться автоматически сформированные подсказки (их еще называют автокомплиты). Да и не все реальные подсказки на самом деле популярные, поэтому лучше перепроверять их частотность с помощью парсера Вордстата.
 Пример бессмысленного автоматически сформированного запроса, так никто не ищет
Пример бессмысленного автоматически сформированного запроса, так никто не ищет
Главное при этом помнить, что Вордстат показывает статистику за последние 30 дней. Если запрос сезонный, лучше еще заглянуть в «Историю запросов».
5 Запросы, на которые поисковик дает ответы в самих подсказках, вряд ли целесообразно использовать для продвижения. Маловероятно, что по таким запросам пользователь пойдет смотреть результаты.
 Примеры ответов на запрос прямо в подсказках
Примеры ответов на запрос прямо в подсказках
Представление результатов#
A-Parser создавался для парсинга информации любых видов, для этого было введено 2 типа результатов:
- Простые результаты(Flat)
- Массивы результатов(Array)
Рассмотрим каждый тип на примере парсера SE::Google, скриншот выдачи:

Простые результаты
Простые результаты — когда одному запросу соответствует один результат, примеры:
- Количество результатов по запросу ($totalcount)
- Является ли запрос опечаткой($misspell, на скриншоте не представлен)
Другие примеры:
- Значение Alexa Rank($rank) в парсере Rank::Alexa
- Значение переведённого текста($translated) в парсере DeepL::Translator
- Количество ссылающихся доменов($domains), значение траста($trustflow), беклинков($backlinks) и т.д. в парсере Rank::MajesticSEO
Одиночные результаты сохраняются в обычных переменных(префикс + название на латинице)
Массивы результатов
Массивы результатов — когда одному запросу соответствует список результатов, каждый элемент списка в свою очередь может содержать несколько вложенных элементов. Разберем на примере выдачи Google — она представлена в парсере массивом $serp, для наглядности воспользуемся таблицей, запишем первые 5 результатов выдачи:
| Ссылка($link) | Анкор($anchor) | Сниппет($snippet) |
|---|---|---|
| http://www.speedtest.net/ | Speedtest.net by Ookla — The Global Broadband Speed Test | Test your Internet connection bandwidth to locations around the world with this interactive broadband speed test from Ookla. |
| http://en.wikipedia.org/wiki/Test_cricket | Test cricket — Wikipedia, the free encyclopedia | Test cricket is the longest form of the sport of cricket. Test matches are played between national representative teams with «Test status», as determined by the … |
| http://www.speakeasy.net/speedtest/ | Speakeasy Speed Test | Saturday 03-May 2014, 11:04:29 AM Your IP: The Speakeasy Speed Test requires Flash v7 or higher. Please update your browser. See Pricing Or Call Today |
| http://www.humanmetrics.com/cgi-win/jtypes2.asp | Personality test based on C. Jung and I. Briggs Myers type theory | Humanmetrics Jung Typology Test instrument uses methodology, questionnaire, scoring and software that are proprietary to Humanmetrics, and shall not be … |
| http://test-ipv6.com/ | Test your IPv6. | This will test your browser and connection for IPv6 readiness, as well as show you your current IPV4 and IPv6 address. … Test your IPv6 connectivity. JavaScript … |
Каждая позиция выдачи записывается в массив с 3мя вложенными элементами — ссылка($link), анкор($anchor), сниппет($snippet)
Другой пример — список связанных ключевых слов, который сохраняется в массиве $related:
| Кейворд($key) |
|---|
| test wwe |
| depression test |
| test my speed |
| wonderlic test |
| test personality |
| act test |
| jiggle test |
| bipolar test |
Как видно в данном массиве всего один вложенный элемент — кейворд($key)
Нумерация элементов массивов начинается с 0, пример доступа к отдельным элементам массива:
- $serp.0.link — первая ссылка из выдачи
- $serp.3.anchor — четвертый анкор из выдачи
- $related.0.key — первый связанный кейворд
Более подробно про форматирование простых результатов и массивов будет описано ниже
Бесплатные парсеры
В Сети можно найти бесплатные версии парсеров, которые по заверениям разработчиков ничем не уступают вышеописанным программам и сервисам. Однако в большинстве случаев это «сырой» продукт с рядом недостатков – отсутствие обновлений, неудобный интерфейс, ограниченные функции. Низкая точность выборки, часто возникают ошибки. Причина – Яндекс.Вордстат постоянно изменяется, за этим нужно следить и вносить корректировки в ПО.
Если бесплатное использование является обязательным условием, можно скачать актуальные версии «Словоёб» или «Магадан». Альтернатива – воспользоваться возможностями «Букварикса» после регистрации.
Выбор парсеров зависит от поставленной задачи – объема ключевых фраз, точности выборки и дальнейшей обработки результатов. Для больших проектов рекомендуются платные версии, для ознакомления с возможностями и для составления СЯ для 1-3 сайтов – бесплатные.
Настройка#
Существует два варианта настройки парсера:
- указать эл. почту\пароль от аккаунта Keyword Planner
- авторизоваться в браузере и скопировать нужные значения
Первый вариант. Почта и пароль
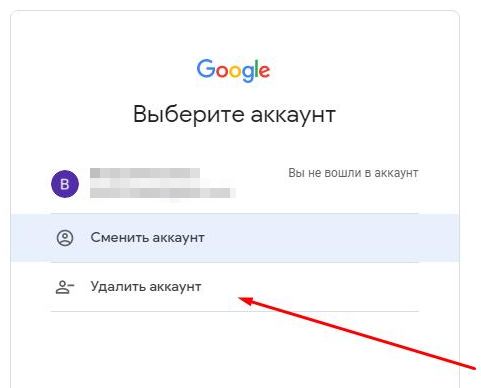
Спойлер: (Решение) Login failed TypeError: Cannot read property ‘1’ of null
В случае возникновения данной ошибки вам нужно удалить свой аккаунт Google из браузера и залогиниться заново.
Второй вариант. Авторизация в браузере
- Значение куки __Secure-3PSID
- Значение куки SAG
- Значение заголовка x-framework-xsrf-token
- Значение параметра ocid или uscid из урла
Спойлер: Как найти необходимые параметры

Обзор парсера SE::Google::KeywordPlanner#
SE::Google::KeywordPlanner
Благодаря многопоточной работе A-Parser’a, скорость обработки запросов может достигать 800 запросов в минуту, что в среднем позволяет получать до 300 поисковых запросов в минуту.
Функционал A-Parser позволяет сохранять настройки парсинга парсера SE::Google::KeywordPlanner для дальнейшего использования (пресеты), задавать расписание парсинга и многое другое.
Сохранение результатов возможно в том виде и структуре которая вам необходима, благодаря встроенному мощному шаблонизатору Template Toolkit который позволяет применять дополнительную логику к результатам и выводить данные в различных форматах, включая JSON, SQL и CSV.
Примеры запросов#
write essay
Football
tv show
Waterfall
Speak in english
Cats and dogs
forex
forex trade
cheap essay
Скопировать
Подстановки запросов
Вы можете использовать для автоматической подстановки подзапросов из файлов, например мы хотим к кажому запросу добавить какой-то список других слов, укажем несколько основных запросов:
essay
article
thesis
Скопировать
В формате запросов укажем макрос подстановки дополнительных слов из файла Keywords.txt, данный метод позволяет увеличить вариативность запросов многократно:
{subs:Keywords} $query
Скопировать
Данный макрос создаст столько же дополнительных запросов сколько их находится в файле на каждый исходный поисковый запрос, что в сумме даст в результате работы макроса.
Например, если в файл Keywords.txt будет содержать:
buy
cheap
Скопировать
В итоге макрос подстановок превратит 3 основных запроса в 6:
buy essay
cheap essay
buy article
cheap article
buy thesis
cheap thesis
Скопировать