Noindex
Содержание:
- 2.
- Что такое meta name robots?
- Как с помощью расширения обнаружить статьи с мета-тегом?
- Где находится файл robots.txt
- Common mistakes with robots and X-Robots-Tag usage
- Утекает ли вес ссылки через nofollow?
- Из чего состоит robots.txt
- What is a Noindex Meta Tag?
- Группа значений атрибута NAME
- Использование meta name robots
- Common Meta Robots Mistakes
- Как выглядит мета-тег и где его посмотреть
- What is a Disallow Directive?
- Влияние внутренних ссылок на индексацию сайта
2.
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и в исходном коде выглядит так:
<head> ... <meta name ”robots” content=”noindex” /> ... </head>
В примере выше метатег запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.
Но обычно используется комбинация с nofollow, чтобы запретить поисковому роботу переходить по ссылкам на данной странице (и по внешним, и по внутренним). В этом случае метатег выглядит так:
<head> ... <meta name ”robots” content=”noindex, nofollow” /> ... </head>
Возможные комбинации noindex + nofollow:
- <meta name=”robots” content=”noindex, follow” /> – используется в случае, если не нужно, чтобы страница была проиндексирована поисковиками, но роботам были доступны ссылки с этой страницы на другие внутренние или внешние ссылки с нее.
- <meta name=”robots” content=”noindex” /> выполняет то же самое. В данном случае вы запретите поисковой системе индексировать страницу, но индексация ссылок на ней возможна.
- <meta name=”robots” content=”noindex, nofollow” /> – запрещает индексировать контент на соответствующей странице + запрещает роботам переходить по ссылкам. Т.е. полный запрет индексирования страницы.
- <meta name=”robots” content=”index, follow” /> – разрешает роботам индексировать страницу и ходить по ссылкам. Использовать данный вариант смысла нет, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия.
- <meta name=”robots” content=”index, nofollow” /> – разрешает индексировать страницу, но запрещает переходить по ссылкам и индексировать их.
- <meta name=”robots” content=”nofollow” /> – делает то же самое, т.е. разрешает индексировать контент на странице, но запрещает индексацию ссылок.
Отдельное использование Noindex для Google и Yandex
- <meta name=”googlebot” content=”noindex” /> – закрывает страницу от индексации для робота Google
- <meta name=”yandex” content=”noindex” /> – закрывает страницу от индексации для робота Yandex
Что такое meta name robots?
Прошу не путать с robots.txt, так как это совершенно разные файлы. Meta robots необходим, а Robots.txt призван для того чтобы создавать правила индексирования страниц для поисковых роботов.
Чтоб было нагляднее давайте разберем на примере:
Это пример файла robots.txt
Читайте в нашем блоге: Яндекс Вебмастер — Полное руководство
Кстати, совсем недавно написал полноценную статью про правильную настройку robots.txt
Вот это пример мета-тега robots с атрибутами name и content
Как вы видете синтаксис довольно прост + параметры данного тега нечувствительны к регистру. Можно написать и в таком формате
В принципе синтаксис мы уже увидели. Данный тег должен располагаться в разделе <head> тут</head> и нигде больше! Но использовать данный тег можно несколько раз на странице.
Как с помощью расширения обнаружить статьи с мета-тегом?
Значок грустного робота на странице канала
При установленном расширении проверка главной страницы канала производится автоматически. Если канал отмечен как неиндексируемый, то в меню расширения пункт «Неиндексируемые» заменяется значением «Канал не индексируется».
Если в меню расширения в редакторе указано «Канал не индексируется», значит в коде страницы канала присутствует <meta property=»robots» content=»none» />
Ещё раз подчеркну, что наличие этого кода, а значит и соответствующего оповещения в меню — норма для новых каналов.
Значок «грустного робота» на странице публикации
При установленном расширении на странице публикации может отображаться значок грустного робота.
Если в публикации есть такой значок, значит в коде страницы есть <meta name=»robots» content=»noindex» />
Соответственно, для того чтобы его увидеть нужно зайти на страницу публикации. Но зато не нужно изучать исходный код страницы.
Поиск публикаций с мета-тегом
Если вы решите проверить не одну, а десяток публикаций, то придётся заходить в каждую и проверять наличие мета-тега в каждой из них. Вручную это неудобно, поэтому в расширении предусмотрена возможность автоматической проверки.
Для того чтобы начать поиск нужно выбрать пункт меню «Неиндексируемые».
Правда, этот пункт меню будет недоступен, если весь канал отмечен, как неиндексируемый — нет смысла запускать проверку, теги будут обнаружены на всех публикациях.
При первом запуске будет отображено большое страшное предупреждение о том, что процедура поиска производится на страх и риск пользователя.
Дело в том, что стандартной процедуры поиска публикаций с мета-тегом в Дзене не предусмотрено, и расширению приходится буквально открывать каждую проверяемую публикацию и заглядывать в код страницы.
Теоретически это может быть воспринято как DDOS-атака или как попытка накрутить просмотры. На практике с этим проблем не было, но предупредить я вас обязан.
Можно проверить все публикации на канале, а можно проверить лишь 20 последних.
Процедура поиска может занять продолжительное время, по завершении вы получите список публикаций, на которых обнаружен мета-тег.
На моём канале только на одной публикации есть этот мета-тег.
Где находится файл robots.txt
Файл всегда должен располагаться на хостинге, в корне сайта. Например, у нас это выглядит так:
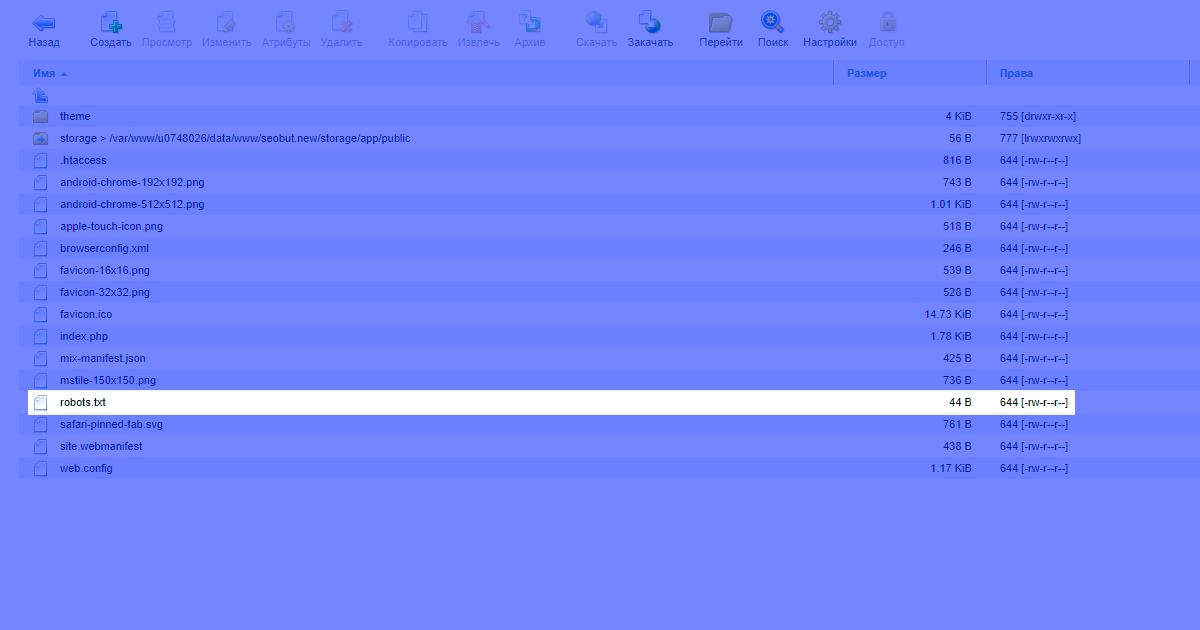
Чтобы проверить текущее содержимое файла на сайте, в адресной строке следует ввести:
mysite.ru/robots.txt
где mysite.ru — доменное имя проверяемого сайта
Расположение robots в CMS
Файл робота в некоторых системах управлениях сайтами можно редактировать из административной панели. Однако, существуют ситуации, когда файл для роботов подменяется на лету специальными плагинами. Поэтому изменение файла на строне хостинга может не работать. В таком случае следует проверить наличие SEO-плагинов и их настроек.
Расположение robots в wordpress
Например, в панели управления wordpress нет отдельного пункта меню для создания и редактирования файла. Поэтому его модификацию можно осуществлять 2 способами:
- редактирование с хостинга,
- редактирование с использованием плагинов.
Редактирование robots.txt через плагин yoast
Рассмотрим создание и редактирование файла robots.txt в wordpress с помощью плагина yoast. Для того, чтобы создать или редактировать файл в данном плагине необходимо:
- установить плагин,
- перейти в настройки плагина,
- выбрать пункт инструменты,
- редактор файлов.
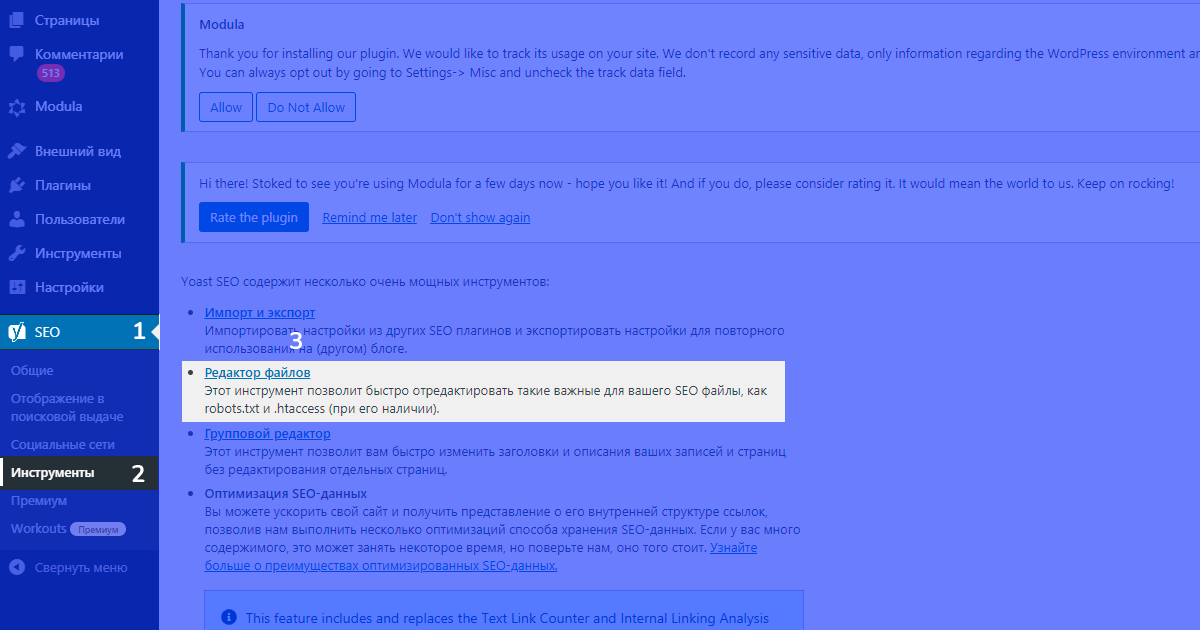
В случае, если файл робот создается через плагин впервые, yoast сообщит, что файл отсутсвует, несмотря на то, что файл может существовать. Тем не менее, если планируется редактирование файла robots из административной панели wordpress, следует нажать на кнопку создания:
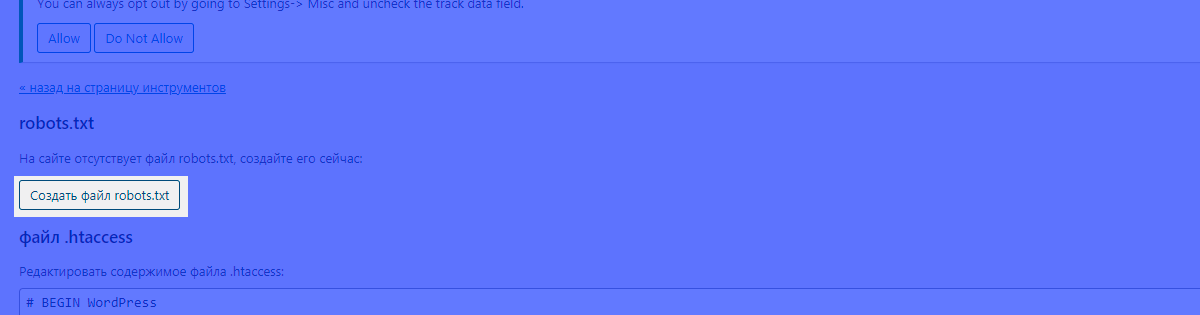
После нажатия кнопки можно увидеть базовое содержимое файла, которое можно редактировать:
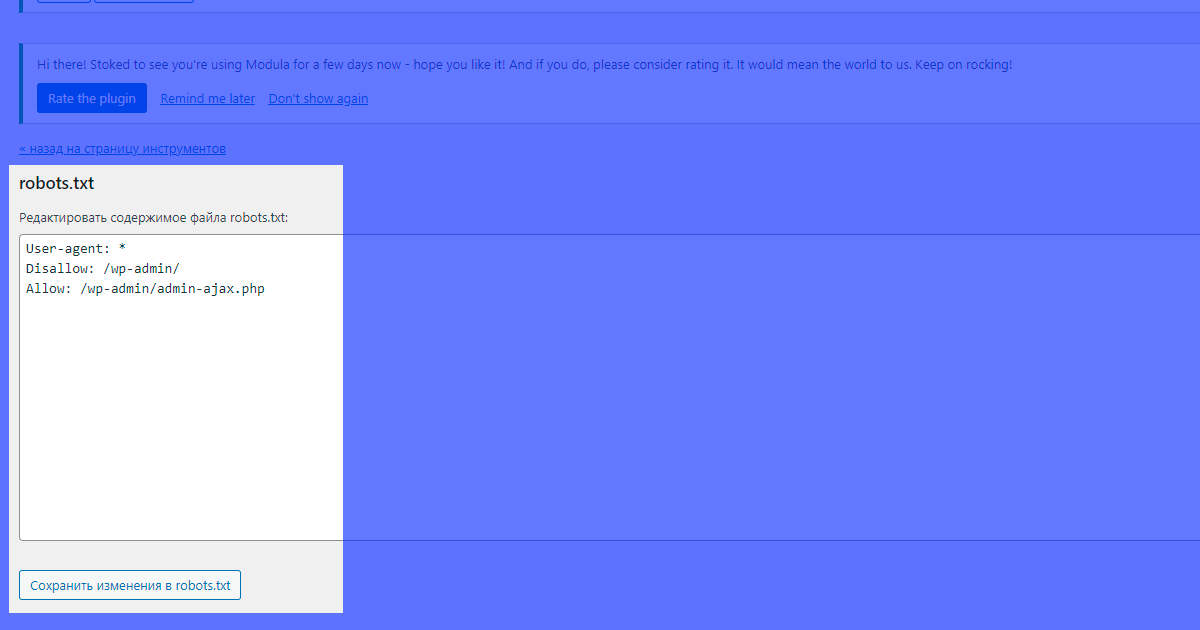
После редактирования следует сохранить изменения.
Расположение robots.txt в tilda
Tilda самостоятельно генерирует файл робота и при этом не дает возможности редактирования, о чем поддержка сообщает в своей вопросно-ответной системе. Сегодня единственным решение в области редактирования файла robots.txt — экспорт проекта на собственный хостинг. После экспорта появится возможность управления файлом робота.
Расположение robots.txt в 1С-Битрикс
В 1С-Битрикс доступ к файлу robots из админ-панели существует. Для того, чтобы управлять файлом робота следует пройти по пути:
Маркетинг > Поисковая оптимизация > Настройка robots.txt
Common mistakes with robots and X-Robots-Tag usage
Conflict with robots.txt
Official X-Robots-Tag and robots guidelines state that a search bot has to be able to crawl the content intended to be hidden from the index. If you disallow a certain page in the robots.txt file, the directives will be inaccessible for crawlers.
Blocking indexing with robots.txt is another common mistake. This file serves for limiting page crawling and not for preventing pages from being indexed. To manage how your pages are displayed in the search, use the robots meta tag and x-robots.
Removing noindex
If you use the noindex directive to hide the content from the index for a certain period, it’s important to open the access for crawlers on time. For instance, you have a page with a future promo deal: if you don’t remove noindex at the time it’s ready, it won’t be shown in the search results and won’t generate traffic.
Removing a URL from the sitemap before it gets deindexed
If a page has the noindex directive, it’s not reasonable to remove it from the sitemap file. Your sitemap allows crawlers to quickly find all pages including those that are intended to be removed from the index.
What you can do is create a separate sitemap.xml with a list of pages containing noindex and remove URLs from the file as they get deindexed. If you upload this file into Google Search Console, robots are likely to crawl it quicker.
Not checking index statuses after making changes
It may happen that valuable content will be blocked from indexing by mistake. To avoid that, check your pages’ indexing statuses after making any changes to them.
You can monitor changes in your site’s code using SE Ranking’s Page Changes Monitor:
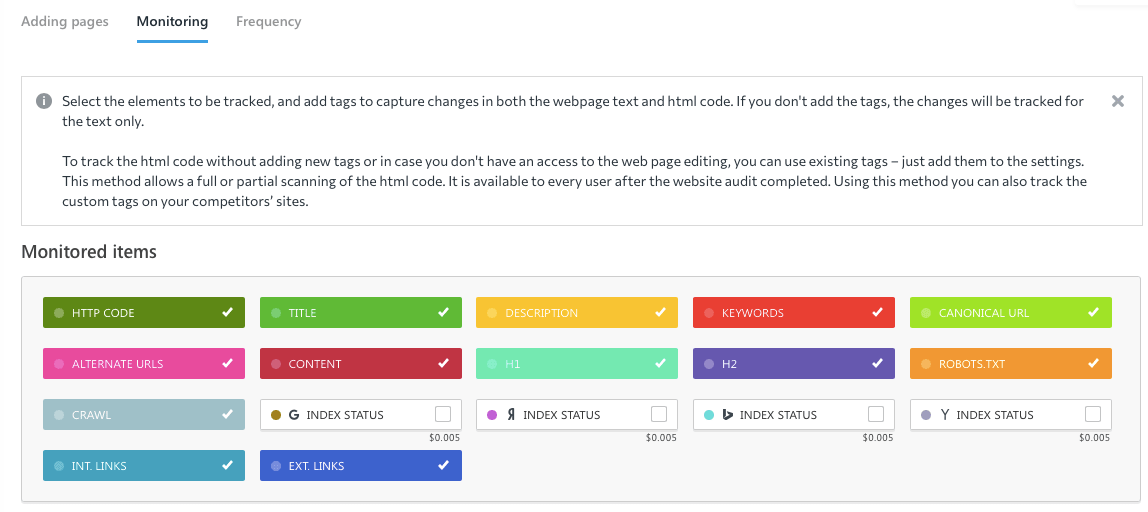
What should you do when a page disappears from the search?
When a page you need to be shown in the SERPs isn’t there, check if there are directives blocking indexing or a disallow directive in the robots.txt file. Also, verify if the URL is included in the sitemap file. Using Google Search Console, you can tell search engines you need to have your page indexed, as well as inform them about an updated sitemap.
Утекает ли вес ссылки через nofollow?
А вот с Яндексом вопрос не явный. Он четко пишет в своей документации, что данный атрибут запрещает индексацию таких ссылок.
А если мы перейдем в описание атрибута robots nofollow, то здесь уже видим запрет на переход, и не слово про индексацию.
Но, раньше можно было это проверить, если применить в поиске такую конструкцию url: ваш урл << inlink:(“анкор ссылки”), и Яндекс нам отображал только те страницы, где содержится наш искомый анкор ссылки. Сейчас же этот метод не работает, поисковая система Яндекс запретила использовать такую конструкцию в поиске. Поэтому можно с большей долью вероятностью сказать, что Яндекс может учитывать такие ссылки, потому что они появляются в Яндекс Вебмастер.
Видно, например, что Яндекс учитывает ссылки с Твиттера, даже если они отдаются через редирект и закрыты nofollow.
В целом можно сказать, что применение данного атрибута для поисковых роботов не всегда является запретом, если особенно сайт авторитетный.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
«Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.ru/sitemap.xml Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
What is a Noindex Meta Tag?
A ‘noindex’ tag tells search engines not to include the page in search results.
The most common method of noindexing a page is to add a tag in the head section of the HTML, or in the response headers. To allow search engines to see this information, the page must not already be blocked (disallowed) in a robots.txt file. If the page is blocked via your robots.txt file, Google will never see the noindex tag and the page might still appear in search results.
To tell search engines not to index your page, simply add the following to the </head> section:
<meta name=”robots” content=”noindex, follow”>
The second part of the content tag here indicates that all the links on this page should be followed, which we’ll discuss below.
Alternatively, the noindex tag can be used in an X-Robots-Tag in the HTTP header:
X-Robots-Tag: noindex
For more information see Google Developers’ post on
Группа значений атрибута NAME
«keywords» (ключевые слова)
Keywords поисковые системы используют для того, чтобы определить релевантность страницы тому или иному запросу. При формировании данного значения необходимо использовать только те слова, которые обязательно встречаются в самом документе. Использование тех слов, которых нет на странице, не рекомендуется. Ключевые слова нужно добавлять по одному, через запятую, в единственном числе. Рекомендованное количество слов в «keywords» — не более десяти. Кроме того, выявлено, что разбивка этого значения на несколько строк влияет на оценку ссылки поисковыми машинами. Некоторые поисковые системы не индексируют сайты, в которых в значении «keywords» повторяется одно и то же слово для увеличения позиции в списке результатов.
Если раньше «keywords» имел определённую роль в ранжировании сайта, то в последнее время поисковые системы относятся к нему нейтрально.
HTML-код с «keywords»:
«description» (описание страницы)
Description используется при создании краткого описания конкретной страницы Вашего сайта. Практически все поисковые системы учитывают его при индексации, а также при создании аннотации в выдаче по запросу. При отсутствии «description» поисковые системы выдают в аннотации первую строку документа или отрывок, содержащий ключевые слова. Отображается после ссылки при поиске страниц в поисковике, поэтому желательно не просто указывать краткое описание документа, но сделать его содержание привлекательным рекламным сообщением.
Таким образом, правильный description обязательно должен содержать ключевое слово, коротко и точно описывать то, о чём данная веб-страница. «Description» вместе с «title» образуют очень важную пару значений, от которых зависит то, перейдёт пользователь из поисковой выдачи на веб-страницу или нет! Поэтому «description» и «title» нужно прописывать для каждой веб-страницы!
HTML-код с «description»:
«Author» и «Copyright»
Эти значения, как правило, не используются одновременно. Функция author и copyright — идентификация автора или принадлежности контента на странице. «Author» содержит имя автора веб-страницы, но в случае, если веб-сайт принадлежит какой-либо организации, целесообразнее использовать значение «Copyright».
HTML-код с «author»:
«Robots»
Robots — формирует информацию о гипертекстовых документах, которая поступает к роботам поисковых систем.
У «robots» могут быть следующие значения:
- index — страница должна быть проиндексирована;
- noindex — страница не индексируется;
- follow — гиперссылки на странице учитываются;
- nofollow — гиперссылки на странице не учитываются
- all — включает значения index и follow, включен по умолчанию;
- none — включает значения noindex и nofollow.
HTML-код с «robots»:
Использование meta name robots
Когда нужен robots.txt, а когда meta name robots?
Плюсы meta name robots.txt
Данный файл мы можем указывать, когда необходимо закрыть целые разделы, несколько страниц от индексации поисковых роботов. Причем, чтобы запретить раздел, мы прописываем это только одной строкой и если мы хотим разрешить индексирование одной страницы, то добавляем дополнительно строку.
В принципе более подробно про robots.txt я рассказал здесь.
Мета-тег name robots в этом случае проигрывает, потому что невозможно указать данный тег на весь раздел (придется выставлять отдельно на каждой странице, что очень неудобно и затратно).
Ну в целом и все. Главное, что мы выигрываем время.
Теперь разберем, когда лучше всего использовать meta name robots.
1. Страница в разработке.
Допустим, вы не до конца доделали страницу и в дальнейшем планируете его закончить, тогда вы можете внести ее на сайт, но попросить поисковую систему не индексировать эту страницу. В дальнейшем, когда страница будет готова, вы удалите этот тег.
Тег будет выглядеть так:
Если вы не знаете, то архивы, ярлыки создают дублирование контента. Но закрывать эти страницы от индексации полностью необязательно. Достаточно, тег meta name robots с запретом индексации текста, но индексацию ссылок не трогать.
Ответы на вопросы
Что будет, если использовать одновременно meta name robots и robots.txt ?
Поисковой системе без разницы что вы используете для управления индексацией (файлом robots.txt или мета тегом robots)
Важно чтобы эти элементы не противоречили друг другу. Поэтому будьте внимательны.
Common Meta Robots Mistakes
It’s not uncommon for mistakes to be made when instructing search engines how to crawl and index a web page, with the most common being:
Meta Robots Directives on a Page Blocked By Robots.txt
If a page is disallowed in your robots.txt file, search engine bots will be unable to crawl the page and take note of any directives that are placed in meta robots tags or in an x-robots-tag.
Make sure that any pages that are instructing user-agents in this way can be crawled.
If a page has never been indexed, a robots.txt disallow rule should be sufficient to prevent this from showing in search results, but it is still recommended that a meta robots tag is added.
Adding Robots Directives to the Robots.txt File
While never officially supported by Google, it used to be possible to add a noindex directive to your site’s robots.txt file and for this to take effect.
This is no longer the case and was confirmed to no longer be effective by Google in .
Removing Pages With a Noindex Directive From Sitemaps
If you are trying to remove a page from the index using a noindex directive, leave the page in your site’s sitemap until this has happened.
Removing the page before it has been deindexed can cause delays in this happening.
Accidentally Blocking Search Engines From Crawling an Entire Site
Sadly, it’s not uncommon for robots directives that are used in a staging environment to accidentally be left in place when the site moves to a live server, and the results can be disastrous.
Before moving any site from a staging platform to a live environment, double-check that any robots directives that are in place are correct.
You can use the Semrush Site Audit Tool before migrating to a live platform to find any pages that are being blocked either with meta robots tags or the x-robots-tag.
By taking the time to understand the different directives and how to use them, you can prevent technical SEO mistakes. Having sufficient control over how your pages are crawled and indexed can help to keep unwanted pages out of the SERPs, prevent search engines from following unnecessary links, and give you control over how your site’s snippets are displayed, among other things. Get started setting up your robots meta tags and x-robots-tags to ensure that your site is running smoothly!
Run a Technical Site Audit
with the Semrush Site Audit Tool
Try for Free →
Try for Free →
Как выглядит мета-тег и где его посмотреть
Вообще мета-тег — это обычный тег html, который используется при создании веб-страниц для хранения информации, предназначенной для браузеров и поисковых систем. Теоретически в мета-теге может содержаться абсолютно любая информация, но в контексте публикаций в Дзене обычно имеются в виду мета-теги <meta name=»robots» content=»noindex» /> или <meta property=»robots» content=»none» />.
Чтобы посмотреть, есть ли мета-тег на обычной странице, нужно кликнуть правой кнопкой мыши в любом месте страницы, и в меню выбрать пункт «Просмотр кода страницы».
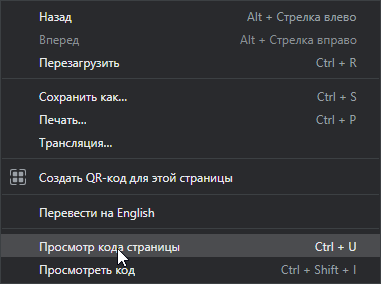
Откроется окно с исходным кодом страницы, где среди множества понятных и не очень строчек можно найти нужные нам мета-теги.
 Здесь немного другой мета-тег — видите «all»? Об этом поговорим чуть ниже.
Здесь немного другой мета-тег — видите «all»? Об этом поговорим чуть ниже.
Мета-тега на странице может и не быть или он может быть немного другим, и это может менять его значение.
What is a Disallow Directive?
Disallowing a page means you’re telling search engines not to crawl it, which must be done in the robots.txt file of your site. It’s useful if you have lots of pages or files that are of no use to readers or search traffic, as it means search engines won’t waste time crawling those pages.

To add a disallow, simply add the following into your robots.txt file:
Disallow: /your-page-url/
If the page has external links or canonical tags pointing to it, it could still be indexed and ranked, so it’s important to combine a disallow with a noindex tag, as described below.
A word of caution: by disallowing a page you’re effectively removing it from your site.
Disallowed pages cannot pass PageRank to anywhere else – so any links on those pages are effectively useless from an SEO perspective – and disallowing pages that are supposed to be included can have disastrous results for your traffic, so be extra careful when writing disallow directives.
Влияние внутренних ссылок на индексацию сайта
Внутренние ссылки являются основной и практически единственной причиной того, что нам приходится закрывать ненужные и попавшие в индекс страницы разными метатегами и директивами robots.txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
А что же делать? При любом варианте запрета индексации ссылок (rel=”nofollow”) и страниц (robots.txt, meta robots), вес сайта просто теряется, утекает на закрытые страницы.
Вариант №1. Большинство распространенных CMS имеют возможность использования специальных тегов (в DLE точно это есть, я сам этим очень активно пользуюсь) при создании шаблонов оформления, которые позволяют регулировать вывод определенной информации. Например, показывать какой-либо текст только гостям или группе пользователей с определенным id и т.д. Если таких тегов вдруг нет, то наверняка на помощь придут логические конструкции (такие конструкции есть в WordPress, а так же форумных движках IPB и vbulletin, опять же, я сам пользуюсь этими возможностями), представляющие из себя простейшие условные алгоритмы на php.
Так вот, логично было бы скрывать неважные и ненужные ссылки от гостей (обычно эту роль играют и роботы при посещении любого сайта), а так же скрывать ссылки на страницы, которые выдают сообщение о том, что вы не зарегистрированы, не имеете прав доступа и все такое. При необходимости можно специально для гостей выводить блок с информацией о том, что после регистрации у них появится больше прав и возможностей, а значит и соответствующие ссылки появятся 😉
Но бывают такие моменты, что ссылку нельзя скрыть или удалить, потому что она нужна, и нужна сразу всем – гостям, пользователям… А вот роботам не нужна. Что делать?
Вариант №2. В редких случаях (хотя последнее время все чаще и чаще) бывает необходимо, чтобы ссылки или даже целые блоки сайта были недоступны и невидны роботам, а вот людям отображались и работали в полной мере, вне зависимости от групп и привилегий. Вы уже, наверное, догадались, что я говорю про сокрытие контента при помощи JavaScript или AJAX. Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Так вот, если хочется какую-то часть контента роботам не показывать, то лучший выбор – JavaScript. А после того как провернете всю техническую часть, проверить это на работоспособность поможет замечательный плагин для FireFox под названием QuickJava. Просто с помощью плагина отключите для браузера обработку яваскрипта и перезагрузите страницу, весь динамически подгружаемый контент должен пропасть 😉 Но помните, что тут тоже надо знать меру!
И, кстати, еще парочка интересных моментов, которые необходимо знать:
Яндексу в индексации сайтов помогает Яндекс.Метрика, которая автоматически пингует в индекс все посещенные страницы, на которых установлен код Метрики. Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Возможно как то в индексации замешаны Яндекс.Бар и сборка браузера Хром от Яндекса, но в этом я не уверен.
Но вот для Гугла есть информация, что роль поискового робота выполняет сам браузер Google Chrome. Такие уж они хитрецы.
Так что, как видим, скрыть информацию от роботов почти невозможно, если не предпринимать специальные меры.