Excel
Содержание:
- Как выделить дублирующиеся строки.
- Обработка найденных дубликатов
- Поиск повторяющихся значений включая первые вхождения.
- Метод 5: формула для удаления повторяющихся строк
- Удаление дубликатов в Microsoft Excel
- Иные способы удаления дубликатов в Excel
- Excel — как удалить дубликаты но оставить уникальные значения?
- Как убрать дубликаты строк с помощью формул.
- Поиск и выделение дубликатов цветом
- Использование сводных таблиц для определения повторяющихся значений
- Поиск и выделение дубликатов цветом в Excel
- Поиск дубликатов при помощи встроенных фильтров Excel
Как выделить дублирующиеся строки.
В предыдущем примере демонстрировалось, как окрашивать целые строки при появлении повторяющихся значений в определенной колонке. Но что, если вы хотите просмотреть строки с одинаковыми значениями в нескольких колонках? Или как выделить из них абсолютно одинаковые, которые имеют совершенно одинаковые значения?
Для этого используйте функцию СЧЁТЕСЛИМН, которая позволяет сравнивать по нескольким критериям. Например, чтобы выделить строки с одинаковыми значениями в B и C, то есть найти заказы одного и того же товара одним заказчиком, используйте одну из следующих формул:
Чтобы выделить совпадающие, кроме 1-го вхождения :
=COUNTIFS($A$2:$A2, $A2, $B$2:$B2, $B2)>1

Обратите внимание, что форматирование мы применяем ко всей таблице. Чтобы выделить все неуникальные:
Чтобы выделить все неуникальные:
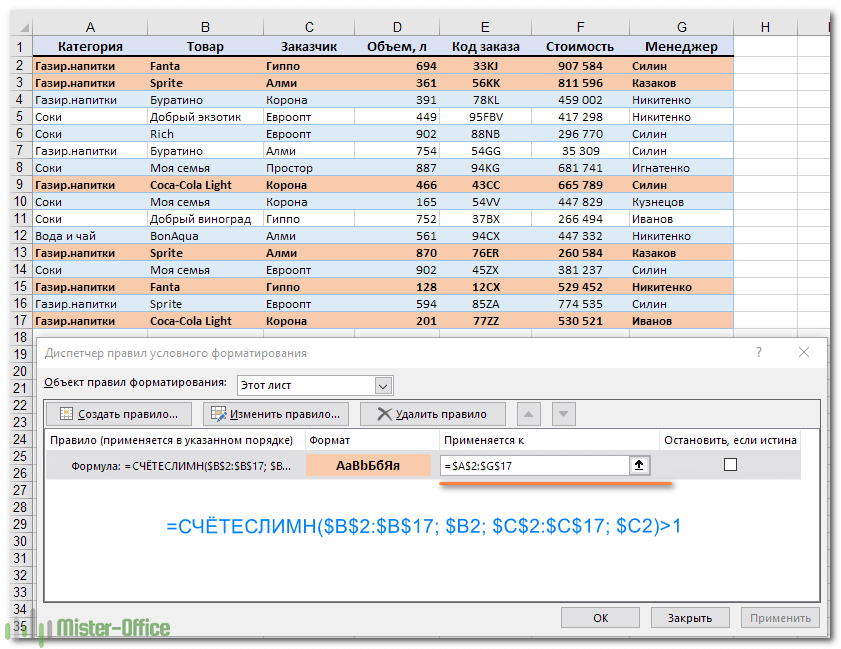
Как вы понимаете, приведенный выше пример только для демонстрационных целей. При выделении дублирующихся строк в ваших реальных таблицах вы, естественно, не ограничены сравнением значений только в 2 столбцах. Функция СЧЁТЕСЛИМН может обрабатывать до 127 пар диапазон / критерий.
Обработка найденных дубликатов
Отлично, мы нашли записи в первом столбце, которые также присутствуют во втором столбце. Теперь нам нужно что-то с ними делать. Просматривать все повторяющиеся записи в таблице вручную довольно неэффективно и занимает слишком много времени. Существуют пути получше.
Показать только повторяющиеся строки в столбце А
Если Ваши столбцы не имеют заголовков, то их необходимо добавить. Для этого поместите курсор на число, обозначающее первую строку, при этом он превратится в чёрную стрелку, как показано на рисунке ниже:
Кликните правой кнопкой мыши и в контекстном меню выберите Insert (Вставить):
Дайте названия столбцам, например, «Name» и «Duplicate?» Затем откройте вкладку Data (Данные) и нажмите Filter (Фильтр):
После этого нажмите меленькую серую стрелку рядом с «Duplicate?«, чтобы раскрыть меню фильтра; снимите галочки со всех элементов этого списка, кроме Duplicate, и нажмите ОК.
Вот и всё, теперь Вы видите только те элементы столбца А, которые дублируются в столбце В. В нашей учебной таблице таких ячеек всего две, но, как Вы понимаете, на практике их встретится намного больше.
Чтобы снова отобразить все строки столбца А, кликните символ фильтра в столбце В, который теперь выглядит как воронка с маленькой стрелочкой и выберите Select all (Выделить все). Либо Вы можете сделать то же самое через Ленту, нажав Data (Данные) > Select & Filter (Сортировка и фильтр) > Clear (Очистить), как показано на снимке экрана ниже:
Изменение цвета или выделение найденных дубликатов
Если пометки «Duplicate» не достаточно для Ваших целей, и Вы хотите отметить повторяющиеся ячейки другим цветом шрифта, заливки или каким-либо другим способом…
В этом случае отфильтруйте дубликаты, как показано выше, выделите все отфильтрованные ячейки и нажмите Ctrl+1, чтобы открыть диалоговое окно Format Cells (Формат ячеек). В качестве примера, давайте изменим цвет заливки ячеек в строках с дубликатами на ярко-жёлтый. Конечно, Вы можете изменить цвет заливки при помощи инструмента Fill (Цвет заливки) на вкладке Home (Главная), но преимущество диалогового окна Format Cells (Формат ячеек) в том, что можно настроить одновременно все параметры форматирования.
Теперь Вы точно не пропустите ни одной ячейки с дубликатами:
Удаление повторяющихся значений из первого столбца
Отфильтруйте таблицу так, чтобы показаны были только ячейки с повторяющимися значениями, и выделите эти ячейки.
Если 2 столбца, которые Вы сравниваете, находятся на разных листах, то есть в разных таблицах, кликните правой кнопкой мыши выделенный диапазон и в контекстном меню выберите Delete Row (Удалить строку):
Нажмите ОК, когда Excel попросит Вас подтвердить, что Вы действительно хотите удалить всю строку листа и после этого очистите фильтр. Как видите, остались только строки с уникальными значениями:
Если 2 столбца расположены на одном листе, вплотную друг другу (смежные) или не вплотную друг к другу (не смежные), то процесс удаления дубликатов будет чуть сложнее. Мы не можем удалить всю строку с повторяющимися значениями, поскольку так мы удалим ячейки и из второго столбца тоже. Итак, чтобы оставить только уникальные записи в столбце А, сделайте следующее:
- Отфильтруйте таблицу так, чтобы отображались только дублирующиеся значения, и выделите эти ячейки. Кликните по ним правой кнопкой мыши и в контекстном меню выберите Clear contents (Очистить содержимое).
- Очистите фильтр.
- Выделите все ячейки в столбце А, начиная с ячейки А1 вплоть до самой нижней, содержащей данные.
- Откройте вкладку Data (Данные) и нажмите Sort A to Z (Сортировка от А до Я). В открывшемся диалоговом окне выберите пункт Continue with the current selection (Сортировать в пределах указанного выделения) и нажмите кнопку Sort (Сортировка):
- Удалите столбец с формулой, он Вам больше не понадобится, с этого момента у Вас остались только уникальные значения.
- Вот и всё, теперь столбец А содержит только уникальные данные, которых нет в столбце В:
Как видите, удалить дубликаты из двух столбцов в Excel при помощи формул – это не так уж сложно.
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача — найти их, то следующая формула для вас:
Где А2 — первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.
Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что — уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
Если же вам нужно, чтобы формула указывала только на дубли, замените «Уникальное» на пустоту («»):
В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми
То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
На скриншоте ниже вы видите эту формулу в деле.
Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент — они не чувствительны к регистру. Быть может, для вас это не принципиально
Но если в ваших данных абв, Абв и АБВ — это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (—).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:
Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Метод 5: формула для удаления повторяющихся строк
Последний метод достаточно сложен, и им мало, кто пользуется, так как здесь предполагается использование сложной формулы, объединяющей в себе несколько простых функций. И чтобы настроить формулу для собственной таблицы с данными, нужен определенный опыт и навыки работы в Эксель.
Формула, позволяющая искать пересечения в пределах конкретного столбца в общем виде выглядит так:
Давайте посмотрим, как с ней работать на примере нашей таблицы:
- Добавляем в конце таблицы новый столбец, специально предназначенный для отображения повторяющихся значений (дубликаты).
- В верхнюю ячейку нового столбца (не считая шапки) вводим формулу, которая для данного конкретного примера будет иметь вид ниже, и жмем Enter: =ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;A2:A90)>1;0;1);0));»») .
- Выделяем до конца новый столбец для задвоенных данных, шапку при этом не трогаем. Далее действуем строго по инструкции:
- ставим курсор в конец строки формул (нужно убедиться, что это, действительно, конец строки, так как в некоторых случаях длинная формула не помещается в пределах одной строки);
- жмем служебную клавишу F2 на клавиатуре;
- затем нажимаем сочетание клавиш Ctrl+SHIFT+Enter.
- Эти действия позволяют корректно заполнить формулой, содержащей ссылки на массивы, все ячейки столбца. Проверяем результат.
Как уже было сказано выше, этот метод сложен и функционально ограничен, так как не предполагает удаления найденных столбцов. Поэтому, при прочих равных условиях, рекомендуется использовать один из ранее описанных методов, более логически понятных и, зачастую, более эффективных.
Удаление дубликатов в Microsoft Excel
Для меня человека который проводит время в отпуске и работает с мобильного интернета скорость которого измеряется от 1-2 мегабита, прокачивать в пустую такое кол-во товара с фотографиями смысла не имеет и время пустое и трафика сожрет не мало, поэтому решил повторяющиеся товары просто удалить и тут столкнулся с тем, что удалить дублирующиеся значения в столбце не так то и просто, потому как стандартная функция excel 2010 делает это топорно и после удаления дубликата двигает вверх нижние значения и в итоге у нас все перепутается в документе и будет каша.
В данной статье будет представлено два варианта решения проблемы.
1 Вариант — Стандартная функция в эксель — Удалить дубликаты
Я не могу пропустить этот вариант, хоть он и самый примитивный но может это то, что именно Вы искали для своей ситуации, поэтому давайте рассмотрим тот функционал который идет из коробки самого экселя
Для этого выделим те столбцы или область в какой надо удалить дубликаты и зайдем в меню Данные и потом выберем Удалить дубликаты, после чего у нас удаляться дубликаты, но будет сдвиг ячеек, если для вас это не критично, то этот способ Ваш!
2 Вариант — Пометить дубликаты строк в Лож или Истина
Этот вариант самый простой и отсюда сразу вылетает птичка которая ограничит этот вариант в действии, а именно в том, что им можно воспользоваться если у вас все дублирующие значения идут по порядку, а не в разнобой по всему документу
для примера возьмем два столбика с данными, в одном (пример1) дублирующие значения повторяются, а в (примере2) в разнобой и не идут друг за другом.
В примере1 мы должны в стоящей рядом ячейки нажать знак ровно и выбрать первое и нижние значение что бы формула была такая:
и нажимаем энтер, и у нас в этой ячейки в зависимости от данных должно появится значение Лож или Истина
ЛОЖ — если А1 не будет равно А2
Истина — если А1 будет ровно А2
если применить этот вариант на столбце Пример2, то как вы поняли везде будет значение Лож
Этот вариант хорош только в редких случаях, но его тоже надо знать, его ограничение в том что эта формула сравнивает себя и следующее значение, тоесть она применима только одновременно к двум ячейкам, а не ко всему столбцу. Но если у вас данные как с столбце Пример2, тогда читайте дальше )
3 Вариант — Удалить дубликаты в столбе
Вот этот вариант уже более сложный, но он решит вашу проблему на все 100% и сразу ответит на все вопросы.
Как видим у нас имеется столбец в котором все значения идут не по порядку и они перемешаны
Мы как и в прошлый раз в соседнюю ячейку вставляем следующую формулу
После применения которой у нас будет либо пуская ячейка, либо значение из ячейки напротив.
из нашего примера сразу видно, что в этом столбце было два дубля и эта формула нам значительно сэкономила времени, а дальше фильтруем второй столбец и в фильтре выбираем пустые ячейки и дальше удаляем строки, вот и все)
Таким образом я в документе который который скачал у поставщика создал перед артикулом пустой столбце и далее применил эту формулу и после отфильтровав получил документ который был на 6-8 тыс строк меньше и самое главное после удаление дубликатов у меня не поднимались значения вверх, все стояло на своих местах
Надеюсь статья была полезная, если не поняли я прикрепил к каналу видео смотрите его или задавайте вопросы,
Иные способы удаления дубликатов в Excel
Итак, давайте подведем некоторые итоги касаемо того, как удалять повторы в Excel в разных ситуациях. Начем с повторений в одной колонке.
Удаление дубликатов в одном столбце
Если вся нужная информация находится в одной колонке, а требуется удаление повторяющихся данных, то нужно выполнить такие шаги:
- Выделить нужный диапазон.
- Развернуть вкладку «Данные» на Панели инструментов и найти кнопку «Удалить дубликаты».
- После этого появится окно, где возле пункта «Мои данные содержат заголовки» ставится флажок, если в соответствующем диапазоне заголовок имеется. Кроме этого, надо посмотреть на меню «Колонны», чтобы убедиться, что галочка стоит возле нужного столбца.
После того, как будет нажата кнопка «Ок», системой будут удалены все копии в столбце.
Удаление дубликатов в нескольких столбцах
Представим, что у нас есть таблица, в которой имена, сумма продаж и регион совпадают, но при этом отличаются даты.
26
Это может произойти, если при вводе информации в таблицу была допущена ошибка. Если необходимо удалить такие повторения, то нужно осуществить следующие действия:
- Выделить информацию в таблице.
- Развернуть вкладку «Данные», там отыскать часть инструментов, обозначенную заголовком «Работа с данными», после чего кликнуть на знакомую нам кнопку «Удалить дубликаты». Дальше действия осуществляются аналогично, но при нужно не ставить флажок возле столбца с датой.
После этого все дубли будут убраны системой.
Удаление дублирующих строк с данными
Чтобы автоматически убрать все повторения строк, нужно выполнить такие действия:
- Выделить часть ячеек, где нужно убрать дубли.
- После этого найти функцию «Удалить дубликаты» и выполнять те же действия, что описаны выше. Но в этом случае надо убедиться в том, что все флажки стоят. Тогда Эксель автоматически проверит всю информацию на предмет наличия в ней повторяющейся.
После нажатия ОК мы получаем нужный нам результат.
Excel — как удалить дубликаты но оставить уникальные значения?
Всем добрый вечер! Случалось ли Вам когда нибудь работать с данными в excel строковое значение которых переваливает за пару десятков тысяч? А вот мне человеку который создает и продвигает сайты и интернет магазины приходится сталкиваться достаточно часто, особенно когда дело касается загрузки и выгрузки данных от поставщика на сайт интернет магазина. Данная заметка родилась не на пустом месте, а прямо так сказать с пылу жару! Сегодня делал загрузку на свой интернет магазин по интим тематике (см портфолио) и после того как скачал прайс от поставщика и открыв его в excel (перед загрузкой на сайт я сначала все сверяю, на случай ошибок и случайных изменений столбцов со стороны поставщика) и увидел что из 25 тыс строк более 6-8 тыс являются дубликатами, зачем и почему так делает поставщик мы сейчас обсуждать не будем, на это не хочется тратить не сил, ни времени, а просто понимаем, что так сделал программист и по другому это делать нельзя!
После долгих колупаний решил выложить Вам инструкцию как удалить дубли строк без сдвига значений вверх.
Как убрать дубликаты строк с помощью формул.
Еще один способ удалить неуникальные данные — идентифицировать их с помощью формулы, затем отфильтровать, а затем после этого удалить лишнее.
Преимущество этого подхода заключается в универсальности: он позволяет вам:
- находить и удалять повторы в одном столбце,
- находить дубликаты строк на основе значений в нескольких столбиках данных,
- оставлять первые вхождения повторяющихся записей.
Недостатком является то, что вам нужно будет запомнить несколько формул.
В зависимости от вашей задачи используйте одну из следующих формул для обнаружения повторов.
Формулы для поиска повторяющихся значений в одном столбце
Добавляем еще одну колонку, в которой запишем формулу.
Повторы наименований товаров, без учета первого вхождения:
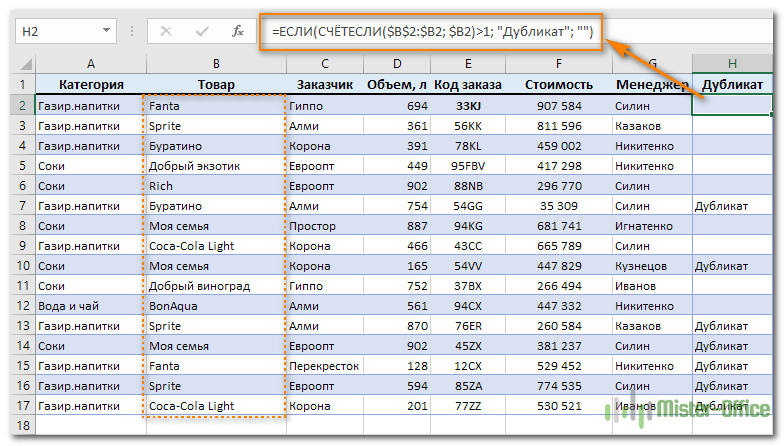
Как видите, когда значение встречается впервые (к примеру, в B4), оно рассматривается как вполне обычное. А вот второе его появление (в B7) уже считается повтором.
Отмечаем все повторы вместе с первым появлением:
Где A2 — первая, а A10 — последняя ячейка диапазона, в котором нужно найти совпадения.

Ну а теперь, чтобы убрать ненужное, устанавливаем фильтр и в столбце H и оставляем только «Дубликат». После чего строки, оставшиеся на экране, просто удаляем.
Вот небольшая пошаговая инструкция.
- Выберите любую ячейку и примените автоматический фильтр, нажав кнопку «Фильтр» на вкладке «Данные».
- Отфильтруйте повторяющиеся строки, щелкнув стрелку в заголовке нужного столбца.
- И, наконец, удалите повторы. Для этого выберите отфильтрованные строки, перетаскивая указатель мыши по их номерам, щелкните правой кнопкой мыши и выберите «Удалить строку» в контекстном меню. Причина, по которой вам нужно сделать это вместо простого нажатия кнопки «Удалить» на клавиатуре, заключается в том, что это действие будет удалять целые строки, а не только содержимое ячейки.
Формулы для поиска повторяющихся строк.
В случае, если нам нужно найти и удалить повторяющиеся строки (либо часть их), действуем таким же образом, как для отдельных ячеек. Только формулу немного меняем.
Отмечаем при помощи формулы неуникальные строчки, кроме 1- го вхождения:
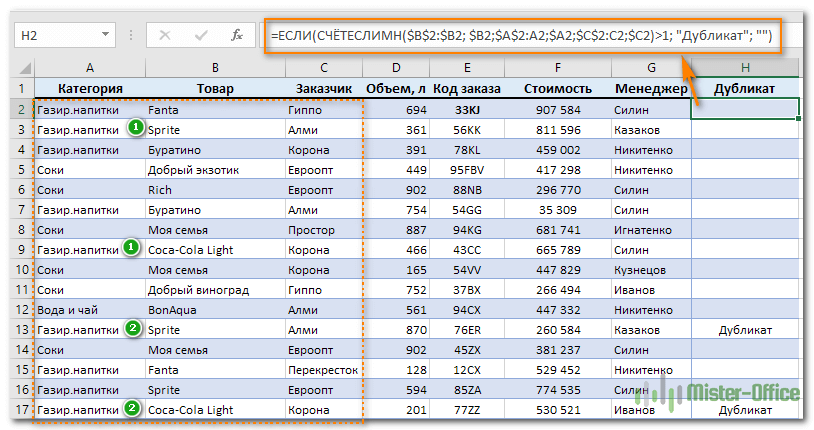
В результате видим 2 повтора.
Теперь самый простой вариант действий – устанавливаем фильтр по столбцу H и слову «Дубликат». После этого просто удаляем сразу все отфильтрованные строки.
Если нам нужно исключить все повторяющиеся строки вместе с их первым появлением:
Далее вновь устанавливаем фильтр и действуем аналогично описанному выше.
Насколько удобен этот метод – судить вам.
Поиск и выделение дубликатов цветом
Чтобы выделить дубликаты на фоне других ячеек каким-то цветом, надо использовать условное форматирование. Этот инструмент имеет множество функций, в том числе, и возможность выставлять цвет для обнаруженных дубликатов.
В одном столбце
Условное форматирование – это наиболее простой способ определить, где находятся дубликаты в Excel и выделить их. Что нужно сделать для этого?
- Найти ту область поиска дубликатов и выделить ее.
- Переключить свой взор на Панель инструментов, и там развернуть вкладку «Главная». После нажатия на эту кнопку появляется набор пунктов, и нас, как уже было понятно исходя из информации выше, интересует пункт «Повторяющиеся значения».
- Далее появляется окно, в котором нужно выбрать пункт «Повторяющиеся» и нажать на клавишу ОК.
Теперь дубликаты подсвечены красным цветом. После этого нужно их просто удалить, если в этом есть необходимость.
В нескольких столбцах
Если стоит задача определить дубликаты, расположенные больше, чем в одной колонке, то принципиальных отличий от стандартного использования условного форматирования нет. Единственная разница заключается в том, что необходимо выделить несколько столбцов.
Последовательность действий, в целом, следующая:
- Выделить колонки, в которых будет осуществляться поиск дубликатов.
- Развернуть вкладку «Главная». После этого находим пункт «Условное форматирование» и выставляем правило «Повторяющиеся значения» так, как это было описано выше.
- Далее снова выбираем пункт «Повторяющиеся» в появившемся окошке, а в списке справа выбираем цвет заливки. После этого кликаем по «ОК» и радуемся жизни.
Дубликаты строк
Важно понимать, что между поиском дублей ячеек и строк есть огромная разница. Давайте ее рассмотрим более подробно
Посмотрите на эти две таблицы.
1718
Характерная особенность тех таблиц, которые были приведены выше, заключается в том, что в них приводятся одни и те же значения. Все потому, что в первом примере осуществлялся поиск дубликатов ячеек, а во втором видим уже повторение строк с информацией.
Итак, что нужно сделать для поиска повторяющихся значений в рядах?
- Создаем еще одну колонку в правой части по отношению к таблице с исходной информацией. В нем записывается формула, которая выводит объединенную информацию со всех ячеек, входящих в состав строки. =A2&B2&C2&D2
- После этого мы увидим информацию, которая была объединена.
- После этого следует выбрать дополнительную колонку (а именно, те ячейки, которые содержат объединенные данные).
- Далее переходим на «Главная», а затем снова выбираем пункт «Повторяющиеся значения» аналогично описанному выше.
- Далее появится диалоговое окно, где снова выбираем пункт «Повторяющиеся», а в правом перечне находим цвет, с использованием которого будет осуществляться выделение.
После того, как будет нажата кнопка «ОК», повторы будут обозначены тем цветом, который пользователь выбрал на предыдущем этапе.
Хорошо, предположим, перед нами стоит задача выбрать те строки, которые располагаются в исходном диапазоне, а не по вспомогательной колонке? Чтобы это сделать, нужно предпринять следующие действия:
- Аналогично предыдущему примеру, делаем вспомогательную колонну, где записываем формулу объединения предыдущих столбцов. =A2&B2&C2&D2
- Далее мы получаем все содержащиеся в строке значения, указанные в соответствующих ячейках каждой из строк.
- После этого осуществляем выделение всей содержащиеся информации, не включая дополнительный столбец. В случае с нами это такой диапазон: A2:D15. После этого переходим на вкладку «Главная» и выбираем пункт «Условное форматирование» – создать правило (видим, что последовательность немного другая).
- Далее нас интересует пункт «Использовать формулу для определения форматируемых ячеек», после чего вставляем в поле «Форматировать значения, для которых следующая формула является истинной», такую формулу. =СЧЁТЕСЛИ($E$2:$E$15;$E2)>1
Для дублированных строк обязательно установить правильный формат. С помощью приведенной выше формулы можно осуществить проверку диапазона на предмет наличия повторов и выделить их определенным пользователем цветом в таблице.
23
Использование сводных таблиц для определения повторяющихся значений
Воспользуемся уже знакомой нам таблицей с тремя столбцами и добавим четвертый, под названием Счетчик, и заполним его единицами (1). Выделяем всю таблицу и переходим по вкладке Вставка в группу Таблицы, щелкаем по кнопке Сводная таблица.
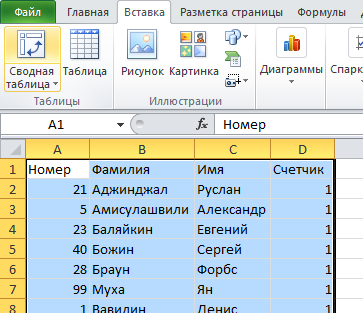
Создаем сводную таблицу. В поле Название строк помещаем три первых столбца, в поле Значения помещаем столбец со счетчиком. В созданной сводной таблице, записи со значением больше единицы будут дубликатами, само значение будет означать количество повторяющихся значений. Для большей наглядности, можно отсортировать таблицу по столбцу Счетчик, чтобы сгруппировать дубликаты.
Поиск и выделение дубликатов цветом в Excel
Дубликаты в таблицах могу встречаться в разных формах. Это могут быть повторяющиеся значения в одной колонке и в нескольких, а также в одной или нескольких строках.
Поиск и выделение дубликатов цветом в одном столбце в Эксель
Самый простой способ найти и выделить цветом дубликаты в Excel, это использовать условное форматирование.
Как это сделать:
Выделим область с данными, в которой нам нужно найти дубликаты:
На вкладке “Главная” на Панели инструментов нажимаем на пункт меню “Условное форматирование” -> “Правила выделения ячеек” -> “Повторяющиеся значения”:

Во всплывающем диалоговом окне выберите в левом выпадающем списке пункт “Повторяющиеся”, в правом выпадающем списке выберите каким цветом будут выделены дублирующие значения. Нажмите кнопку “ОК”:

После этого, в выделенной колонке, будут подсвечены цветом дубликаты:
Поиск и выделение дубликатов цветом в нескольких столбцах в Эксель
Если вам нужно вычислить дубликаты в нескольких столбцах, то процесс по их вычислению такой же как в описанном выше примере. Единственное отличие, что для этого вам нужно выделить уже не одну колонку, а несколько:
- Выделите колонки с данными, в которых нужно найти дубликаты;
- На вкладке “Главная” на Панели инструментов нажимаем на пункт меню “Условное форматирование” -> “Правила выделения ячеек” -> “Повторяющиеся значения”;
- Во всплывающем диалоговом окне выберите в левом выпадающем списке пункт “Повторяющиеся”, в правом выпадающем списке выберите каким цветом будут выделены повторяющиеся значения. Нажмите кнопку “ОК”:
- После этого в выделенной колонке будут подсвечены цветом дубликаты:
Поиск и выделение цветом дубликатов строк в Excel
Поиск дубликатов повторяющихся ячеек и целых строк с данными это разные понятия
Обратите внимание на две таблицы ниже:


В таблицах выше размещены одинаковые данные. Их отличие в том, что на примере слева мы искали дубликаты ячеек, а справа мы нашли целые повторяющие строчки с данными.
Рассмотрим как найти дубликаты строк:
Справа от таблицы с данными создадим вспомогательный столбец, в котором напротив каждой строки с данными проставим формулу, объединяющую все значения строки таблицы в одну ячейку:
Во вспомогательной колонке вы увидите объединенные данные таблицы:

Теперь, для определения повторяющихся строк в таблице сделайте следующие шаги:
- Выделите область с данными во вспомогательной колонке (в нашем примере это диапазон ячеек E2:E15>);
- На вкладке “Главная” на Панели инструментов нажимаем на пункт меню “Условное форматирование” -> “Правила выделения ячеек” -> “Повторяющиеся значения”;
- Во всплывающем диалоговом окне выберите в левом выпадающем списке “Повторяющиеся”, в правом выпадающем списке выберите каким цветом будут выделены повторяющиеся значения. Нажмите кнопку “ОК”:
- После этого в выделенной колонке будут подсвечены дублирующиеся строки:

На примере выше, мы выделили строки в созданной вспомогательной колонке.
Но что, если нам нужно выделить цветом строки не во вспомогательном столбце, а сами строки в таблице с данными?
Для этого давайте сделаем следующее:
Также как и в примере выше создадим вспомогательный столбец, в каждой строке которого проставим следующую формулу:
Таким образом, мы получим в одной ячейке собранные данные всей строки таблицы:
- Теперь, выделим все данные таблицы (за исключением вспомогательного столбца). В нашем случае это ячейки диапазона A2:D15>;
- Затем, на вкладке “Главная” на Панели инструментов нажмем на пункт “Условное форматирование” -> “Создать правило”:

В диалоговом окне “Создание правила форматирования” кликните на пункт “Использовать формулу для определения форматируемых ячеек” и в поле “Форматировать значения, для которых следующая формула является истинной” вставьте формулу:

Не забудьте задать формат найденных дублированных строк.
Эта формула проверяет диапазон данных во вспомогательной колонке и при наличии повторяющихся строк выделяет их цветом в таблице:

Поиск дубликатов при помощи встроенных фильтров Excel
Организовав данные в виде списка, Вы можете применять к ним различные фильтры. В зависимости от набора данных, который у Вас есть, Вы можете отфильтровать список по одному или нескольким столбцам. Поскольку я использую Office 2010, то мне достаточно выделить верхнюю строку, в которой находятся заголовки, затем перейти на вкладку Data (Данные) и нажать команду Filter (Фильтр). Возле каждого из заголовков появятся направленные вниз треугольные стрелки (иконки выпадающих меню), как на рисунке ниже.
Если нажать одну из этих стрелок, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с Вашим выбором. Это быстрый способ подвести итог или увидеть объём выбранных данных. Вы можете убрать галочку с пункта Select All (Выделить все), а затем выбрать один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные Вами пункты. Так гораздо проще найти дубликаты, если они есть.
После настройки фильтра Вы можете удалить дубликаты строк, подвести промежуточные итоги или дополнительно отфильтровать данные по другому столбцу. Вы можете редактировать данные в таблице так, как Вам нужно. На примере ниже у меня выбраны элементы XP и XP Pro.
В результате работы фильтра, Excel отображает только те строки, в которых содержатся выбранные мной элементы (т.е. людей на чьём компьютере установлены XP и XP Pro). Можно выбрать любую другую комбинацию данных, а если нужно, то даже настроить фильтры сразу в нескольких столбцах.
Расширенный фильтр для поиска дубликатов в Excel
На вкладке Data (Данные) справа от команды Filter (Фильтр) есть кнопка для настроек фильтра – Advanced (Дополнительно). Этим инструментом пользоваться чуть сложнее, и его нужно немного настроить, прежде чем использовать. Ваши данные должны быть организованы так, как было описано ранее, т.е. как база данных.
Перед тем как использовать расширенный фильтр, Вы должны настроить для него критерий. Посмотрите на рисунок ниже, на нем виден список с данными, а справа в столбце L указан критерий. Я записал заголовок столбца и критерий под одним заголовком. На рисунке представлена таблица футбольных матчей. Требуется, чтобы она показывала только домашние встречи. Именно поэтому я скопировал заголовок столбца, в котором хочу выполнить фильтрацию, а ниже поместил критерий (H), который необходимо использовать.
Теперь, когда критерий настроен, выделяем любую ячейку наших данных и нажимаем команду Advanced (Дополнительно). Excel выберет весь список с данными и откроет вот такое диалоговое окно:
Как видите, Excel выделил всю таблицу и ждёт, когда мы укажем диапазон с критерием. Выберите в диалоговом окне поле Criteria Range (Диапазон условий), затем выделите мышью ячейки L1 и L2 (либо те, в которых находится Ваш критерий) и нажмите ОК. Таблица отобразит только те строки, где в столбце Home / Visitor стоит значение H, а остальные скроет. Таким образом, мы нашли дубликаты данных (по одному столбцу), показав только домашние встречи:
Это достаточно простой путь для нахождения дубликатов, который может помочь сохранить время и получить необходимую информацию достаточно быстро. Нужно помнить, что критерий должен быть размещён в ячейке отдельно от списка данных, чтобы Вы могли найти его и использовать. Вы можете изменить фильтр, изменив критерий (у меня он находится в ячейке L2). Кроме этого, Вы можете отключить фильтр, нажав кнопку Clear (Очистить) на вкладке Data (Данные) в группе Sort & Filter (Сортировка и фильтр).



