Чтение и запись списков в файл в python
Содержание:
- Открытие файлов в Python
- Использование методов
- Извлечение текста с помощью PyPDF2
- Другие способы преобразования файлов Excel в CSV
- Как открыть текстовый файл в Python с помощью open()
- Чтение CSV-файла при помощи csv.reader(). Метод 1
- How to Open a Text File
- Генератор случайных файлов
- Использование Python¶
- Что такое метод read() в Python?
- Найти все страницы, где есть заданный текст
- 1.3. Анализ текста из файла на Python
- Чтение параграфов
- Открытие файла с помощью функции open()
- Основа
- Модуль OS Python
- Форматы файлов в Python 3
- Разделение PDF‑файлов на страницы с помощью PyPDF2
- The file Object Attributes
- Модуль PyYAML¶
- The need for “open with” statement
Открытие файлов в Python
Python по умолчанию предоставляет нам функцию open(), которая предназначена для открытия файла. Рассмотрим пример использования данной функции.
file = open("text.txt") # Открытие файла
file = open("C:/text.txt") #Открытие файла по его пути
Существует несколько режимов открытия файла, r — для чтения, w — для записи, a — для добавления. По умолчанию Python использует режим чтение файла
| Режим | Описание |
| r | Открывает файл для чтения. (по умолчанию) |
| w | Открывает файл для записи. Создает новый файл, если он не существует, или усекает файл, если он существует. |
| x | Открывает файл для эксклюзивного создания. Если файл уже существует, операция завершается неудачей. |
| a | Открывает файл для добавления в конце файла без его усечения. Создает новый файл, если он не существует. |
| t | Открывается в текстовом режиме. (по умолчанию) |
| b | Открывается в двоичном режиме. |
| + | Открывает файл для обновления (чтения и записи) |
Режим открытия указывается следующим образом:
f = open("text.txt") #Режим r по умолчанию
f = open("text.txt", "w")# Режим записи в файл
f = open("text.txt", "a") # Режим добавления
Кроме того, надо учитывать кодировку файла, по умолчанию кодировка зависит от вашей операционной системы. Для Windows, кодировка cp1251, а для Linux utf — 8. Соответственно, что бы наша программа вела себя одинаково на разных платформах, лучшим решением будет указание явной кодировки.
file = open("text.txt", "r", encoding = "utf-8" )
Использование методов
Для работы с символами (строками) отлично работают основные методы. Сохранить такой список построчно в файл listfile.txt можно следующим образом:
# define list of places
places =
with open('listfile.txt', 'w') as filehandle:
for listitem in places:
filehandle.write('%s\n' % listitem)
В строке 6 элемент списка, во-первых, расширяется переносом строки «\n» и, во-вторых, сохраняется в выходном файле. Чтобы прочитать весь список из файла listfile.txt, этот код Python показывает вам, как это работает:
# define an empty list
places = []
# open file and read the content in a list
with open('listfile.txt', 'r') as filehandle:
for line in filehandle:
# remove linebreak which is the last character of the string
currentPlace = line
# add item to the list
places.append(currentPlace)
Имейте в виду, что вам нужно удалить перенос строки с конца строки. В этом случае нам помогает то, что Python также допускает операции со списком для строк. В строке 8 приведенного выше кода это удаление просто выполняется, как операция списка над самой строкой, которая сохраняет все, кроме последнего элемента. Этот элемент содержит символ «\n», обозначающий разрыв строки в системах UNIX и Linux.
Извлечение текста с помощью PyPDF2
Начнём с . Ниже приведен скрипт, который позволяет извлечь из PDF‑файла текст и вывести него в консоль.
Сначала импортируем , помня о том, что пакет уже установлен. Задаём имя файла из папки (можете загрузить туда свой файл и поменять в скрипте на имя загруженного файла), открывает документ и получаем информацию о документе, используя метод и общее количество страниц . Далее в цикле читаем каждую страницу, получаем содержимое и печатаем в .
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов при извлекает первую страницу документа
from PyPDF2 import PdfFileReader
pdf_document = "source/Computer-Vision-Resources.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
 Извлечение текста с помощью PyPDF2
Извлечение текста с помощью PyPDF2
Как видите, извлеченный текст печатается сплошным потоком. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены на странице. В основном, это зависит от внутренней структуры документа PDF и от того, как поток инструкций, создан во время его записи, поэтому их использование может привести к неожиданностям, надо дополнительно «парсить», не очень удобно.
Другие способы преобразования файлов Excel в CSV
Описанные выше способы экспорта данных из Excel в CSV (UTF-8 и UTF-16) универсальны, т.е. подойдут для работы с любыми специальными символами и в любой версии Excel от 2003 до 2013.
Существует множество других способов преобразования данных из формата Excel в CSV. В отличие от показанных выше решений, эти способы не будут давать в результате чистый UTF-8 файл (это не касается , который умеет экспортировать файлы Excel в несколько вариантов кодировки UTF). Но в большинстве случаев получившийся файл будет содержать правильный набор символов, который далее можно безболезненно преобразовать в формат UTF-8 при помощи любого текстового редактора.
Преобразуем файл Excel в CSV при помощи Таблиц Google
Как оказалось, можно очень просто преобразовать файл Excel в CSV при помощи Таблиц Google. При условии, что на Вашем компьютере уже установлен , выполните следующие 5 простых шагов:
- В Google Drive нажмите кнопку Создать (Create) и выберите Таблица (Spreadsheet).
- В меню Файл (File) нажмите Импорт (Import).
- Кликните Загрузка (Upload) и выберите файл Excel для загрузки со своего компьютера.
- В диалоговом окне Импорт файла (Import file) выберите Заменить таблицу (Replace spreadsheet) и нажмите Импорт (Import).
Совет: Если файл Excel относительно небольшой, то для экономии времени можно перенести из него данные в таблицу Google при помощи копирования / вставки.
- В меню Файл (File) нажмите Скачать как (Download as), выберите тип файла CSV – файл будет сохранён на компьютере.
В завершение откройте созданный CSV-файл в любом текстовом редакторе, чтобы убедиться, что все символы сохранены правильно. К сожалению, файлы CSV, созданные таким способом, не всегда правильно отображаются в Excel.
Сохраняем файл .xlsx как .xls и затем преобразуем в файл CSV
Для этого способа не требуется каких-либо дополнительных комментариев, так как из названия уже всё ясно.
Это решение я нашёл на одном из форумов, посвящённых Excel, уже не помню, на каком именно. Честно говоря, я никогда не использовал этот способ, но, по отзывам множества пользователей, некоторые специальные символы теряются, если сохранять непосредственно из .xlsx в .csv, но остаются, если сначала .xlsx сохранить как .xls, и затем как .csv, как мы .
Так или иначе, попробуйте сами такой способ создания файлов CSV из Excel, и если получится, то это будет хорошая экономия времени.
Сохраняем файл Excel как CSV при помощи OpenOffice
OpenOffice – это пакет приложений с открытым исходным кодом, включает в себя приложение для работы с таблицами, которое отлично справляется с задачей экспорта данных из формата Excel в CSV. На самом деле, это приложение предоставляет доступ к большему числу параметров при преобразовании таблиц в файлы CSV (кодировка, разделители и так далее), чем Excel и Google Sheets вместе взятые.
Просто открываем файл Excel в OpenOffice Calc, нажимаем Файл > Сохранить как (File > Save as) и выбираем тип файла Текст CSV (Text CSV).
На следующем шаге предлагается выбрать значения параметров Кодировка (Character sets) и Разделитель поля (Field delimiter). Разумеется, если мы хотим создать файл CSV UTF-8 с запятыми в качестве разделителей, то выбираем UTF-8 и вписываем запятую (,) в соответствующих полях. Параметр Разделитель текста (Text delimiter) обычно оставляют без изменения – кавычки («). Далее нажимаем ОК.
Таким же образом для быстрого и безболезненного преобразования из Excel в CSV можно использовать ещё одно приложение – LibreOffice. Согласитесь, было бы здорово, если бы Microsoft Excel предоставил возможность так же настраивать параметры при создании файлов CSV.
Как открыть текстовый файл в Python с помощью open()
Если вы хотите прочитать текстовый файл с помощью Python, вам сначала нужно его открыть.
Вот так выглядит основной синтаксис функции :
open("name of file you want opened", "optional mode")
Имена файлов и правильные пути
Если текстовый файл, который нужно открыть, и ваш текущий файл находятся в одной директории (папке), можно просто указать имя файла внутри функции . Например:
open ("demo.txt")
На скрине видно, как выглядят файлы, находящиеся в одном каталоге:
Но если ваш текстовый файл находится в другом каталоге, вам необходимо указать путь к нему.
В этом примере файл со случайным текстом находится в папке, отличной от той, где находится файл с кодом main.py:
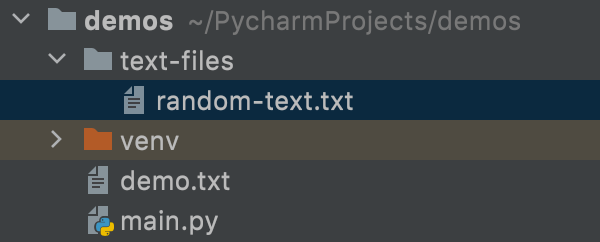
В таком случае, чтобы получить доступ к этому файлу в main.py, вы должны включить имя папки с именем файла.
Если путь к файлу будет указан неправильно, вы получите сообщение об ошибке .
Таким образом, чтобы указать путь к файлу правильно, важно отслеживать, в каком каталоге вы находитесь
Необязательный параметр режима в open()
При работе с файлами существуют разные режимы. Режим по умолчанию – это режим чтения.
Он обозначается буквой .
open("demo.txt", mode="r")
Вы также можете опустить и просто написать .
open("demo.txt", "r")
Существуют и другие типы режимов, такие как для записи или для добавления. Мы не будем вдаваться в подробности о других режимах, потому что в этой статье сосредоточимся исключительно на чтении файлов.
Полный список других режимов можно найти в .
Дополнительные параметры для функции open() в Python
Функция может также принимать следующие необязательные параметры:
- buffering
- encoding
- errors
- newline
- closefd
- opener
Если вы хотите узнать больше об этих опциональных параметрах, можно заглянуть в .
Чтение CSV-файла при помощи csv.reader(). Метод 1
Пример 1. Использование запятой в качестве разделителя
Допустим, у нас есть файл с именем sample1, содержащий некоторые данные. Такой файл можно создать с помощью любого текстового редактора или путем передачи значений в какую-нибудь программу для записи файла CSV. Как это делается, мы расскажем чуть позже.
Текст в этом файле разделен запятыми. Наши данные — сведения о различных книгах (порядковый номер, название, имя автора).
Переходим к коду. Чтобы прочитать файл CSV, нам нужен объект reader для выполнения функции чтения. Первым делом импортируем модуль (встроенный модуль Python). Далее укажем имя файла, который нужно открыть (или путь к нему). Затем инициализируем объект . Он будет перебираться в цикле .
reader = csv.reader(файл)
Данные из указанного файла выводятся построчно.
Запустим наш код. Можем увидеть, что наши данные автоматически преобразовались в списки, состоящие из элементов данных каждой строки.
Пример 2. Использование табуляции в качестве разделителя
В первом примере текст разделяется запятой. Однако мы можем сделать наш код более настраиваемым, добавив различные функции.
Возьмём код из предыдущего примера и сделаем лишь одно изменение: напрямую укажем разделитель (). В предыдущем примере не было никакой необходимости его указывать, потому что запятая — разделитель по умолчанию.
reader = csv.reader(file, delimiter = ‘\t’)
Как видите, результат немного изменился. Теперь все элементы строки являются одним элементом списка. Так произошло потому, что в этот раз мы указали в качестве разделителя не запятую, а .
How to Open a Text File
Let’s start by learning how to open a file with Python. In this case, what we mean is to actually use Python to open it and not some other program. For that, we have two choices (in Python 2.x): open or file. Let’s take a look and see how it’s done!
# the open keyword opens a file in read-only mode by default
f = open("path/to/file.txt")
# read all the lines in the file and return them in a list
lines = f.readlines()
f.close()
As you can see, it’s really quite easy to open and read a text file. You can replace the «open» keyword with the «file» keyword and it will work the same. If you want to be extra explicit, you can write the open command like this instead:
f = open("path/to/file.txt", mode="r")
The «r» means to just read the file. You can also open a file in «rb» (read binary), «w» (write), «a» (append), or «wb» (write binary). Note that if you use either «w» or «wb», Python will overwrite the file, if it exists already or create it if the file doesn’t exist.
If you want to read the file, you can use the following methods:
- read — reads the whole file and returns the whole thing in a string
- readline — reads the first line of the file and returns it as a string
- readlines — reads the entire file and returns it as a list of strings
You can also read a file with a loop, like this:
f = open("path/to/file.txt")
for line in f:
print line
f.close()
Pretty cool, huh? Python rocks! Now it’s time to take a look at how to open a file with another program.
Генератор случайных файлов
Создадим папку , а внутри нее еще одну — . Дерево каталогов теперь должно выглядеть вот так:
ManageFiles/ | |_RandomFiles/
Чтобы поиграться с файлами, мы сгенерируем их случайным образом в директории . Создайте файл в папке . Вот что должно получиться:
ManageFiles/ | |_ create_random_files.py |_RandomFiles/
Готово? Теперь поместите в файл следующий код, и перейдем к его рассмотрению:
import os
from pathlib import Path
import random
list_of_extensions =
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
for item in list_of_extensions:
# создать 20 случайных файлов для каждого расширения имени
for num in range(20):
# пусть имя файла начинается со случайного числа от 1 до 50
file_name = random.randint(1, 50)
file_to_create = str(file_name) + item
Path(file_to_create).touch()
Начиная с Python 3.4 мы получили pathlib, нашу маленькую волшебную палочку. Также мы импортируем функцию для генерации случайных чисел, но ее мы посмотрим в действии чуть ниже.
Сперва создадим
список файловых расширений для формирования названий файлов. Не стесняйтесь
добавить туда свои варианты.
Далее мы переходим в папку и запускаем цикл. В нем мы просто говорим: возьми каждый элемент и сделай с ним кое-что во внутреннем цикле 20 раз.
Теперь пришло время для импортированной функции . Используем ее для производства случайных чисел от 1 до 50. Это просто не очень творческий способ побыстрее дать названия нашим тестовым файлам: к сгенерированному числу добавим расширение файла и получим что-то вроде или . И так 20 раз для каждого расширения. В итоге образуется беспорядок, достаточный для того, чтобы его было лень сортировать вручную.
Итак, запустим
наш генератор хаоса через терминал.
python create_random_files.py
Поздравляю,
теперь у нас полная папка неразберихи. Будем распутывать.
В той же директории, где , создадим файл и поместим туда следующий код.
Использование Python¶
Python-программа, установленная по умолчанию, называется интерпретатором. Интепретатор принимает команды и выполняет их после ввода. Очень удобно для тестирования чего-либо.
Чтобы запустить интерпретатор, просто введи python и нажми Enter.
Чтобы узнать, какая версия Python запущена, используй
Взаимодействие с Python’ом
Когда Python запустится, ты увидишь что-то вроде этого:
Python 3.3.2 (default, May 21 2013, 15:40:45) on linux Type "help", "copyright", "credits" or "license" for more information. >>>
Примечание
>>> в последней строке означает, что сейчас мы находимся в интерактивном интерпретаторе Python, также называемом “Оболочкой Python (Python shell)”. Это не то же самое, и что обычная командная строка!
Теперь ты можешь ввести немного Python-кода. Попробуй:
print("Hello world")
Нажми и посмотри, что произошло. После вывода результата Python вернёт тебя обратно в интерактивную оболочку, в которой мы можем ввести какую-нибудь другую команду:
>>> print("Hello world")
Hello world
>>> (1 + 4) * 2
10
Очень полезна команда , которая поможет тебе изучить досконально изучить Python, не выходя из интерпретатора. Нажми , чтобы закрыть окно со справкой и вернуться в командную строку Python.
Чтобы выйти из интерактивной оболочки, нажми и затем , если используешь Windows, и , если используешь GNU/Linux или OS X. Этого же можно добиться вводом Python-команды .
Запуск файлов с Python-кодом
Когда Python-кода становится слишком много, лучше записывать его в файлы. Это, например, позволит тебе редактировать отдельные части кода (исправлять ошибки) и тут же запускать их без необходимости перепечатывать текст. Просто сохрани код в файл, и передай его имя python‘у. Записанный в файл исходный код будет выполнен без запуска интерактивного интерпретатора.
Давай попробуем сделать это. С помощью своего любимого текстового редактора создай файл в текущей директории и запиши в него программу команду, выводящую фразу “Hello world”, из примера выше. На GNU/Linux или OS X также можно выполнить команду , чтобы создать пустой файл для последующего редактирования. Выполнить сохранённую в файле программу проще простого:
$ python hello.py
Примечание
Для начала убедись, что ты находишься в командной строке (на конце строк должны находиться символы или , а не , как в интерактивной оболочке Python).
В Windows нужно два раза кликнуть на пиктограмму файла, чтобы запустить его.
Когда ты нажмешь <Enter> в консоли, наш файл выполнится и результат его работы будет выведен на экран. В этот момент интерпретатор Python выполнит все инструкции, находящиеся в скрипте и вернет управление командной строке, а не интерактивной оболчке Python.
Теперь всё готово, и мы можем приступить к черепашке!
Примечание
Вместо ожидаемого “Hello world” ты получил какие-то странные ошибки “can’t open file” или “No such file or directory”? Скорее всего, что ты работаешь не в той директории где сохранен твой Pyhton-скрипт. С помощью командной строки легко сменить текущий активный каталог, используя команду cd, что означает “change directory” (сменить каталог). В Windows эта команда может выглядеть так:
> cd Desktop\Python_Exercises
В Linux или OS X:
$ cd Desktop/Python_Exercises
С помощью этой команды мы перейдем в папку Python_Exercises, которая находиться в папке Desktop (конечно же, на твоем компьютере названия папок будут отличаться). Если ты не знаешь путь к каталогу, где ты сохранил свой файл, попробуй просто перетащить папку в окно консоли. А если ты не знаешь в какой папке ты сейчас находишься в консоли — воспользуйся командой pwd, которая означает “print working directory” (показать активную директорию).
Предупреждение
Эксперементируя с черепашкой, не называй рабочий файл — лучше выбрать более подходящие имена, такие как или , иначе при обращении к Python будет использовать твой файл вместо из стандартной библиотеки.
Что такое метод read() в Python?
Метод будет считывать все содержимое файла как одну строку. Это хороший метод, если в вашем текстовом файле мало содержимого .
В этом примере давайте используем метод для вывода на экран списка имен из файла demo.txt:
file = open("demo.txt")
print(file.read())
Запустим этот код и получим следующий вывод:
# Output: # This is a list of names: # Jessica # James # Nick # Sara
Этот метод может принимать необязательный параметр, называемый размером. Вместо чтения всего файла будет прочитана только его часть.
Если мы изменим предыдущий пример, мы сможем вывести только первое слово, добавив число 4 в качестве аргумента для .
file = open("demo.txt")
print(file.read(4))
# Output:
# This
Если аргумент размера опущен или число отрицательное, то будет прочитан весь файл.
Найти все страницы, где есть заданный текст
Этот скрипт довольно практичен и работает аналогично . Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат заданную строку поиска. Страницы загружаются одна за другой и с помощью метода обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение печатается на :
import fitz
filename = "source/Computer-Vision-Resources.pdf"
search_term = "COMPUTER VISION"
pdf_document = fitz.open(filename)
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s найдено на странице %i" % (search_term, current_page+1))
 Результаты поиска COMPUTER VISION
Результаты поиска COMPUTER VISION
Методы, показанные здесь, довольно мощные. Сравнительно небольшое количество строк кода позволяет легко получить результат. Другие варианты применения рассматриваются во второй части, посвященной добавлению водяного знака и картинок в PDF.
Продолжение цикла статей-конспектов на сайте
Источники вдохновения:
1.3. Анализ текста из файла на Python
Python может анализировать текстовые файлы, содержащие целые книги. Возьмем книгу «Алиса в стране чудес» и попробуем подсчитать количество слов в книге. Текстовый файл с книгой можете скачать здесь(‘ alice ‘) или загрузить любое другое произведение. Напишем простую программу, которая подсчитает количество слов в книге и сколько раз повторяется имя Алиса в книге.
filename = ‘alice.txt’
with open(filename, encoding=’utf-8′) as file:
contents = file.read()
n_alice = contents..count(‘алиса’)
words = contents.split()
n_words = (words)
print(«Книга ‘Алиса в стране чудес’ содержит {n_words} слов.»)print(«Имя Алиса повторяется {n_alice} раз.»)
При открытии файла добавился аргумент encoding=’utf-8′. Он необходим, когда кодировка вашей системы не совпадает с кодировкой читаемого файла. После чтения файла, сохраним его в переменной contents.
Для подсчета вхождения слова или выражений в строке можно воспользоваться методом count(), но прежде привести все слова к нижнему регистру функцией . Количество вхождений сохраним в переменной n_alice.
Чтобы подсчитать количество слов в тексе, воспользуемся методом split(), предназначенный для построения списка слов на основе строки. Метод split() разделяет строку на части, где обнаружит пробел и сохраняет все части строки в элементах списка. Пример метода split():
title = ‘Алиса в стране чудес’
print(title.split())
После использования метода split(), сохраним список в переменной words и далее подсчитаем количество слов в списке, с помощью функции len(). После подсчета всех данных, выведем на экран результат:
Книга ‘Алиса в стране чудес’ содержит 28389 слов.
Имя Алиса повторяется 419 раз.
Чтение параграфов
С помощью объекта класса Document и пути к файлу можно получить доступ ко всем абзацам документа с помощью атрибута paragraphs. Пустая строка также читается как абзац.
Извлечем все абзацы из файла my_word_file.docx и затем отобразим общее количество абзацев документа:
all_paras = doc.paragraphs len(all_paras)
Вывод:
10
Теперь поочередно выведем все абзацы, присутствующие в файле my_word_file.docx:
for para in all_paras:
print(para.text)
print("-------")
Вывод:
------- Introduction ------- ------- Welcome to stackabuse.com ------- The best site for learning Python and Other Programming Languages ------- Learn to program and write code in the most efficient manner ------- ------- Details ------- ------- This website contains useful programming articles for Java, Python, Spring etc. -------
Вывод демонстрирует все абзацы, присутствующие в файле my_word_file.docx.
Также можно получить доступ к определенному абзацу, индексируя свойство paragraphs как массив. Давайте выведем пятый абзац в файле:
single_para = doc.paragraphs print(single_para.text)
Вывод:
The best site for learning Python and Other Programming Languages
Открытие файла с помощью функции open()
Первый шаг к работе с файлами в Python – научиться открывать файл. Вы можете открывать файлы с помощью метода open().
Функция open() в Python принимает два аргумента. Первый – это имя файла с полным путем, а второй – режим открытия файла.
Ниже перечислены некоторые из распространенных режимов чтения файлов:
- ‘r’ – этот режим указывает, что файл будет открыт только для чтения;
- ‘w’ – этот режим указывает, что файл будет открыт только для записи. Если файл, содержащий это имя, не существует, он создаст новый;
- ‘a’ – этот режим указывает, что вывод этой программы будет добавлен к предыдущему выводу этого файла;
- ‘r +’ – этот режим указывает, что файл будет открыт как для чтения, так и для записи.
Кроме того, для операционной системы Windows вы можете добавить «b» для доступа к файлу в двоичном формате. Это связано с тем, что Windows различает двоичный текстовый файл и обычный текстовый файл.
Предположим, мы помещаем текстовый файл с именем file.txt в тот же каталог, где находится наш код. Теперь мы хотим открыть этот файл.
Однако функция open (filename, mode) возвращает файловый объект. С этим файловым объектом вы можете продолжить свою дальнейшую работу.
#directory: /home/imtiaz/code.py
text_file = open('file.txt','r')
#Another method using full location
text_file2 = open('/home/imtiaz/file.txt','r')
print('First Method')
print(text_file)
print('Second Method')
print(text_file2)
Результатом следующего кода будет:
================== RESTART: /home/imtiaz/code.py ================== First Method Second Method >>>
Основа
Python может с относительной легкостью обрабатывать различные форматы файлов:
| Тип файла | Описание |
| Txt | Обычный текстовый файл хранит данные, которые представляют собой только символы (или строки) и не включает в себя структурированные метаданные. |
| CSV | Файл со значениями,для разделения которых используются запятые (или другие разделители). Что позволяет сохранять данные в формате таблицы. |
| HTML | HTML-файл хранит структурированные данные и используется большинством сайтов |
| JSON | JavaScript Object Notation — простой и эффективный формат, что делает его одним из часто используемых для хранения и передачи данных. |
В этой статье основное внимание будет уделено формату txt
Модуль OS Python
Переименование файла
Модуль Python os обеспечивает взаимодействие с операционной системой. Модуль os предоставляет функции, которые участвуют в операциях обработки файлов, таких как переименование, удаление и т. д. Он предоставляет нам метод rename() для переименования указанного файла в новое имя. Синтаксис для использования метода rename() приведен ниже.
Синтаксис:
rename(current-name, new-name)
Первый аргумент – это текущее имя файла, а второй аргумент – это измененное имя. Мы можем изменить имя файла, минуя эти два аргумента.
Пример 1:
import os
#rename file2.txt to file3.txt
os.rename("file2.txt","file3.txt")
Приведенный выше код переименовал текущий file2.txt в file3.txt.
Удаление файла
Модуль os предоставляет метод remove(), который используется для удаления указанного файла. Синтаксис метода remove() приведен ниже.
remove(file-name)
Пример 1
import os;
#deleting the file named file3.txt
os.remove("file3.txt")
Форматы файлов в Python 3
Python очень гибкий и может относительно легко обрабатывать множество различных форматов файлов. Вот основные форматы:
| Формат | Описание |
| txt | Обычный текстовый файл, который хранит данные в виде символов (или строк) и исключает структурированные метаданные. |
| CSV | Файл, который хранит данные в виде таблицы; для структурирования хранимых данных используются запятые (или другие разделители). |
| HTML | Файл Hypertext Markup Language хранит структурированные данные; такие файлы используются большинством сайтов. |
| JSON | Простой файл JavaScript Object Notation, один из наиболее часто используемых форматов для хранения и передачи данных. |
Данное руководство рассматривает только формат txt.
Разделение PDF‑файлов на страницы с помощью PyPDF2
Для этого примера, в первую очередь необходимо импортировать классы и . Затем мы открываем файл PDF, создаем объект для чтения и перебираем все страницы, используя метод объекта для чтения .
Внутри цикла мы создаем новый экземпляр , который еще не содержит страниц. Затем мы добавляем текущую страницу к нашему объекту записи, используя метод . Этот метод принимает объект страницы, который мы получаем, используя метод .
Следующим шагом является создание уникального имени файла, что мы делаем, используя исходное имя файла плюс слово «page» плюс номер страницы. Мы добавляем 1 к текущему номеру страницы, потому что PyPDF2 считает номера страниц, начиная с нуля.
Наконец, мы открываем новое имя файла в режиме (режиме ) записи двоичного файла и используем метод класса для сохранения извлеченной страницы на диск.
Листинг 4: Разделение PDF на отдельные страницы.
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "source/Computer-Vision-Resources.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter()
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "dist/Computer-Vision-Resources-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
 Разделили исходный файл на страницы
Разделили исходный файл на страницы
The file Object Attributes
Once a file is opened and you have one file object, you can get various information related to that file.
Here is a list of all attributes related to file object −
| Sr.No. | Attribute & Description |
|---|---|
| 1 |
file.closed Returns true if file is closed, false otherwise. |
| 2 |
file.mode Returns access mode with which file was opened. |
| 3 |
file.name Returns name of the file. |
| 4 |
file.softspace Returns false if space explicitly required with print, true otherwise. |
Example
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
print "Closed or not : ", fo.closed
print "Opening mode : ", fo.mode
print "Softspace flag : ", fo.softspace
This produces the following result −
Name of the file: foo.txt Closed or not : False Opening mode : wb Softspace flag : 0
Модуль PyYAML¶
Для работы с YAML в Python используется модуль PyYAML. Он не входит в
стандартную библиотеку модулей, поэтому его нужно установить:
pip install pyyaml
Работа с ним аналогична модулям csv и json.
Чтение из YAML
Попробуем преобразовать данные из файла YAML в объекты Python.
Файл info.yaml:
- BS 1550 IT 791 id 11 name Liverpool to_id 1 to_name LONDON - BS 1510 IT 793 id 12 name Bristol to_id 1 to_name LONDON - BS 1650 IT 892 id 14 name Coventry to_id 2 to_name Manchester
Чтение из YAML (файл yaml_read.py):
import yaml
from pprint import pprint
with open('info.yaml') as f
templates = yaml.safe_load(f)
pprint(templates)
Результат:
$ python yaml_read.py
Формат YAML очень удобен для хранения различных параметров, особенно,
если они заполняются вручную.
Запись в YAML
Запись объектов Python в YAML (файл yaml_write.py):
import yaml
trunk_template =
'switchport trunk encapsulation dot1q', 'switchport mode trunk',
'switchport trunk native vlan 999', 'switchport trunk allowed vlan'
access_template =
'switchport mode access', 'switchport access vlan',
'switchport nonegotiate', 'spanning-tree portfast',
'spanning-tree bpduguard enable'
to_yaml = {'trunk' trunk_template, 'access' access_template}
with open('sw_templates.yaml', 'w') as f
yaml.dump(to_yaml, f, default_flow_style=False)
with open('sw_templates.yaml') as f
print(f.read())
Файл sw_templates.yaml выглядит таким образом:
access - switchport mode access - switchport access vlan - switchport nonegotiate - spanning-tree portfast - spanning-tree bpduguard enable trunk - switchport trunk encapsulation dot1q - switchport mode trunk - switchport trunk native vlan 999 - switchport trunk allowed vlan
The need for “open with” statement
Before going into the “with statement” we need to understand the requirement behind it. For that, we first need to know how to open a file in python.
In python to read or write a file, we need first to open it and python provides a function open(), which returns a file object. Using this file object, we can read and write in the file. But in the end, we need to close the file using this same.
Check out this example,
# open a file
file_object = open('sample.txt')
# read the file content
data = file_object.read()
# print file content
print(data)
#close the file
file_object.close()
This is a sample file. It contains some sample string. you are going to use it. Thanks.
FileNotFoundError: No such file or directory: 'sample.txt'
In the above example, we opened a file sample.txt using open() function, which returned a file object. Then read file’s content as string using file object’s read() function. Then printed that and in the end closed this file using the same file object.
This will work fine in typical scenarios, but there can be problems in some situations like,
What if someone forgets to close the file in the end?
Well, it seems highly impossible now, but in big projects, people usually do big stuff after opening files, and it includes many conditions and checks. So, there can be scenarios when the return statement hit before close() function gets called, or it got skipped sue to some if condition in code.
Well, in scenarios like these, till we don’t call the close() function, the file will remain open, and its object will be consuming the memory of our process. Also, there might be chances that data will not entirely be flushed to the file. Closing a file using close() function is a graceful way of closing the file.
What if an exception comes?
Check out this code
# File is not closed in case of exception
try:
# open a file
file_object = open('sample.txt')
# read file content
data = file_object.read()
# It will raise an exception
x = 1 / 0
print(data)
file_object.close()
except:
# Handling the exception
print('An Error')
finally:
if file_object.closed == False:
print('File is not closed')
else:
print('File is closed')
An Error File is not closed
# File is not closed in case of exception
try:
# open a file
file_object = open('sample.txt')
# read file content
data = file_object.read()
# It will raise an exception
x = 1 / 0
print(data)
file_object.close()
except:
file_object.close()
# Handling the exception
print('An Error')
finally:
if file_object.closed == False:
print('File is not closed')
else:
print('File is closed')




