Модуль http в python
Содержание:
Задержка
Часто бывает нужно ограничить время ожидания ответа. Это можно сделать с помощью параметра timeout
Перейдите на
раздел — / #/ Dynamic_data / delete_delay__delay_
и изучите документацию — если делать запрос на этот url можно выставлять время, через которое
будет отправлен ответ.
Создайте файл
timeout_demo.py
следующего содержания
Задержка равна одной секунде. А ждать ответ можно до трёх секунд.
python3 timeout_demo.py
<Response >
Измените код так, чтобы ответ приходил заведомо позже чем наш таймаут в три секунды.
Задержка равна семи секундам. А ждать ответ можно по-прежнему только до трёх секунд.
python3 timeout_demo.py
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 421, in _make_request
six.raise_from(e, None)
File «<string>», line 3, in raise_from
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 416, in _make_request
httplib_response = conn.getresponse()
File «/usr/lib/python3.8/http/client.py», line 1347, in getresponse
response.begin()
File «/usr/lib/python3.8/http/client.py», line 307, in begin
version, status, reason = self._read_status()
File «/usr/lib/python3.8/http/client.py», line 268, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), «iso-8859-1»)
File «/usr/lib/python3.8/socket.py», line 669, in readinto
return self._sock.recv_into(b)
File «/usr/lib/python3/dist-packages/urllib3/contrib/pyopenssl.py», line 326, in recv_into
raise timeout(«The read operation timed out»)
socket.timeout: The read operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 439, in send
resp = conn.urlopen(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 719, in urlopen
retries = retries.increment(
File «/usr/lib/python3/dist-packages/urllib3/util/retry.py», line 400, in increment
raise six.reraise(type(error), error, _stacktrace)
File «/usr/lib/python3/dist-packages/six.py», line 703, in reraise
raise value
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 665, in urlopen
httplib_response = self._make_request(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 423, in _make_request
self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 330, in _raise_timeout
raise ReadTimeoutError(
urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «timeout_demo.py», line 4, in <module>
r = requests.get(‘https://httpbin.org/delay/7’, timeout=3)
File «/usr/lib/python3/dist-packages/requests/api.py», line 75, in get
return request(‘get’, url, params=params, **kwargs)
File «/usr/lib/python3/dist-packages/requests/api.py», line 60, in request
return session.request(method=method, url=url, **kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 533, in request
resp = self.send(prep, **send_kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 646, in send
r = adapter.send(request, **kwargs)
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 529, in send
raise ReadTimeout(e, request=request)
requests.exceptions.ReadTimeout: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
Если такая обработка исключений не вызывает у вас восторга — измените код используя try except
python3 timeout_demo.py
Response is taking too long.
Custom Authentication¶
Requests allows you to specify your own authentication mechanism.
Any callable which is passed as the argument to a request method will
have the opportunity to modify the request before it is dispatched.
Authentication implementations are subclasses of ,
and are easy to define. Requests provides two common authentication scheme
implementations in : and
.
Let’s pretend that we have a web service that will only respond if the
header is set to a password value. Unlikely, but just go with it.
from requests.auth import AuthBase
class PizzaAuth(AuthBase):
"""Attaches HTTP Pizza Authentication to the given Request object."""
def __init__(self, username):
# setup any auth-related data here
self.username = username
def __call__(self, r):
# modify and return the request
r.headers'X-Pizza' = self.username
return r
Then, we can make a request using our Pizza Auth:
Выполнение запросов POST
Запросы HTTP POST противоположны запросам GET, поскольку они предназначены для отправки данных на сервер, а не для их получения. Хотя запросы POST также могут получать данные в ответе, как и запросы GET.
Вместо использования метода get() нам нужно использовать метод post(). Для передачи аргумента мы можем передать его внутри параметра данных:
import requests
payload = {'user_name': 'admin', 'password': 'password'}
r = requests.post("http://httpbin.org/post", data=payload)
print(r.url)
print(r.text)
Вывод:
http://httpbin.org/post
{"args":{},"data":"","files":{},"form":{"password":"password","user_name":"admin"},"headers":{"Accept":"*/*","Accept-Encoding":"gzip, deflate","Connection":"close","Content-Length":"33","Content-Type":"application/x-www-form-urlencoded","Host":"httpbin.org","User-Agent":"python-requests/2.9.1"},"json":null,"origin":"103.9.74.222","url":"http://httpbin.org/post"}
По умолчанию данные будут «закодированы в форме». Вы также можете передавать более сложные запросы заголовков, такие как кортеж, если несколько значений имеют один и тот же ключ, строку вместо словаря или файл с многокомпонентным кодированием.
POST Multiple Multipart-Encoded Files¶
You can send multiple files in one request. For example, suppose you want to
upload image files to an HTML form with a multiple file field ‘images’:
<input type="file" name="images" multiple="true" required="true"/>
To do that, just set files to a list of tuples of :
>>> url = 'https://httpbin.org/post'
>>> multiple_files =
... ('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
... ('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]
>>> r = requests.post(url, files=multiple_files)
>>> r.text
{
...
'files': {'images': 'data:image/png;base64,iVBORw ....'}
'Content-Type': 'multipart/form-data; boundary=3131623adb2043caaeb5538cc7aa0b3a',
...
}
Utilities¶
These functions are used internally, but may be useful outside of
Requests.
Status Code Lookup
- requests.codes(name=None)
-
Dictionary lookup object.
>>> requests.codes'temporary_redirect' 307 >>> requests.codes.teapot 418 >>> requests.codes'\o/' 200
Cookies
- requests.utils.dict_from_cookiejar(cj)
-
Returns a key/value dictionary from a CookieJar.
Parameters: cj – CookieJar object to extract cookies from.
- requests.utils.cookiejar_from_dict(cookie_dict)
-
Returns a CookieJar from a key/value dictionary.
Parameters: cookie_dict – Dict of key/values to insert into CookieJar.
- requests.utils.add_dict_to_cookiejar(cj, cookie_dict)
-
Returns a CookieJar from a key/value dictionary.
Parameters: - cj – CookieJar to insert cookies into.
- cookie_dict – Dict of key/values to insert into CookieJar.
Заголовки HTTP в Requests
HTTP-заголовки ответов на запросы тоже могут дать нам полезную информацию. Например, тип содержимого ответного payload либо ограничения по времени для кэширования ответа. Чтобы посмотреть заголовок, надо заглянуть в атрибут .headers. Вот, как это может выглядеть:
>>> response.headers
{'Server' 'GitHub.com', 'Date' 'Mon, 10 Dec 2018 17:49:54 GMT', 'Content-Type' 'application/json; charset=utf-8', 'Transfer-Encoding' 'chunked', 'Status' '200 OK', 'X-RateLimit-Limit' '60', 'X-RateLimit-Remaining' '59', 'X-RateLimit-Reset' '1544467794', 'Cache-Control' 'public, max-age=60, s-maxage=60', 'Vary' 'Accept', 'ETag' 'W/"7dc470913f1fe9bb6c7355b50a0737bc"', 'X-GitHub-Media-Type' 'github.v3; format=json', 'Access-Control-Expose-Headers' 'ETag, Link, Location, Retry-After, X-GitHub-OTP, X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset, X-OAuth-Scopes, X-Accepted-OAuth-Scopes, X-Poll-Interval, X-GitHub-Media-Type', 'Access-Control-Allow-Origin' '*', 'Strict-Transport-Security' 'max-age=31536000; includeSubdomains; preload', 'X-Frame-Options' 'deny', 'X-Content-Type-Options' 'nosniff', 'X-XSS-Protection' '1; mode=block', 'Referrer-Policy' 'origin-when-cross-origin, strict-origin-when-cross-origin', 'Content-Security-Policy' "default-src 'none'", 'Content-Encoding' 'gzip', 'X-GitHub-Request-Id' 'E439:4581:CF2351:1CA3E06:5C0EA741'}
Заголовок .headers возвращает словарь и предоставляет доступ к значению HTTP-заголовка по ключу. К примеру, чтобы посмотреть тип содержимого ответного payload, надо использовать Content-Type.
>>> response.headers'Content-Type' 'application/json; charset=utf-8'
Согласно специфике HTTP, заголовки являются нечувствительными к регистру. Таким образом, при получении доступа к заголовкам мы можем не беспокоиться о том, какие буквы использованы: строчные либо прописные.
Это лишь базовые знания по теме библиотеки Requests в Python и HTTP-заголовков. Если хотите знать больше, вам могут быть полезны следующие статьи:
— «Requests в Python – Примеры выполнения HTTP-запросов»;
— «Краткое руководство по библиотеке Python Requests».
Client Side Certificates¶
You can also specify a local cert to use as client side certificate, as a single
file (containing the private key and the certificate) or as a tuple of both
files’ paths:
>>> requests.get('https://kennethreitz.org', cert=('/path/client.cert', '/path/client.key'))
<Response >
or persistent:
s = requests.Session() s.cert = '/path/client.cert'
If you specify a wrong path or an invalid cert, you’ll get a SSLError:
>>> requests.get('https://kennethreitz.org', cert='/wrong_path/client.pem')
SSLError: _ssl.c:347: error:140B0009:SSL routines:SSL_CTX_use_PrivateKey_file:PEM lib
Работа с JSON ответами
import requests
r = requests.get("https://egorovegor.ru/wp-json/")
print (r.json())
Ответ сервера:
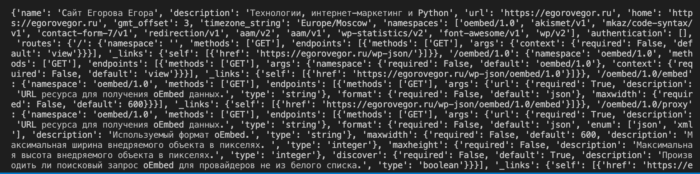
Обратите внимание, я сократил ответ сервера из за большого количества информации в json. r.json() разбирает ответ в Python-совместимый тип данных, т.е
словарь или список. Разберем на примере как использовать полученные JSON данные
r.json() разбирает ответ в Python-совместимый тип данных, т.е. словарь или список. Разберем на примере как использовать полученные JSON данные.
import requests
r = requests.get("https://egorovegor.ru/wp-json/")
data = r.json()
name = data
description = data
url = data
timezone = data
print(f"Информация о сайте: {url}")
print(f"Название: {name}")
print(f"Описание: {description}")
print(f"Часовой пояс: {timezone}")
Выполнив данный сценарий мы получим результат указанный ниже.
Информация о сайте: https://egorovegor.ru Название: Cайт Егорова Егора Описание: Технологии, интернет-маркетинг и Python Часовой пояс: Europe/Moscow
POST Multiple Multipart-Encoded Files¶
You can send multiple files in one request. For example, suppose you want to
upload image files to an HTML form with a multiple file field ‘images’:
<input type="file" name="images" multiple="true" required="true"/>
To do that, just set files to a list of tuples of :
>>> url = 'https://httpbin.org/post'
>>> multiple_files =
... ('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
... ('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]
>>> r = requests.post(url, files=multiple_files)
>>> r.text
{
...
'files': {'images': 'data:image/png;base64,iVBORw ....'}
'Content-Type': 'multipart/form-data; boundary=3131623adb2043caaeb5538cc7aa0b3a',
...
}
Чтение ответа
Ответ на HTTP-запрос может содержать множество заголовков, содержащих различную информацию.
httpbin – популярный веб-сайт для тестирования различных операций HTTP. В этой статье мы будем использовать httpbin или get для анализа ответа на запрос GET. Прежде всего, нам нужно узнать заголовок ответа и то, как он выглядит. Вы можете использовать любой современный веб-браузер, чтобы найти его, но для этого примера мы будем использовать браузер Google Chrome:
- В Chrome откройте URL-адрес http://httpbin.org/get, щелкните правой кнопкой мыши в любом месте страницы и выберите параметр «Проверить».
- Это откроет новое окно в вашем браузере. Обновите страницу и перейдите на вкладку «Сеть».
- Эта вкладка «Сеть» покажет вам все различные типы сетевых запросов, сделанных браузером. Щелкните запрос «получить» в столбце «Имя» и выберите вкладку «Заголовки» справа.
Содержание «Заголовков ответа» является нашим обязательным элементом. Вы можете увидеть пары ключ-значение, содержащие различную информацию о ресурсе и запросе. Попробуем разобрать эти значения с помощью библиотеки запросов:
import requests
r = requests.get('http://httpbin.org/get')
print(r.headers)
print(r.headers)
print(r.headers)
print(r.headers)
print(r.headers)
print(r.headers)
print(r.headers)
print(r.headers)
Мы получили информацию заголовка с помощью r.headers, и мы можем получить доступ к каждому значению заголовка с помощью определенных ключей
Обратите внимание, что ключ не чувствителен к регистру.. Точно так же попробуем получить доступ к значению ответа
Заголовок выше показывает, что ответ находится в формате JSON: (Content-type: application/json). Библиотека запросов поставляется с одним встроенным парсером JSON, и мы можем использовать request.get (‘url’). Json() для анализа его как объекта JSON. Затем значение для каждого ключа результатов ответа можно легко проанализировать, как показано ниже:
Точно так же попробуем получить доступ к значению ответа. Заголовок выше показывает, что ответ находится в формате JSON: (Content-type: application/json). Библиотека запросов поставляется с одним встроенным парсером JSON, и мы можем использовать request.get (‘url’). Json() для анализа его как объекта JSON. Затем значение для каждого ключа результатов ответа можно легко проанализировать, как показано ниже:
import requests
r = requests.get('http://httpbin.org/get')
response = r.json()
print(r.json())
print(response)
print(response)
print(response)
print(response)
print(response)
print(response)
print(response)
print(response)
print(response)
Приведенный выше код напечатает следующий вывод:
{'headers': {'Host': 'httpbin.org', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'close', 'Accept': '*/*', 'User-Agent': 'python-requests/2.9.1'}, 'url': 'http://httpbin.org/get', 'args': {}, 'origin': '103.9.74.222'}
{}
{'Host': 'httpbin.org', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'close', 'Accept': '*/*', 'User-Agent': 'python-requests/2.9.1'}
*/*
gzip, deflate
close
httpbin.org
python-requests/2.9.1
103.9.74.222
http://httpbin.org/get
Третья строка, ierjson(), напечатала значение ответа JSON. Мы сохранили значение JSON в ответе переменной, а затем распечатали значение для каждого ключа
Обратите внимание, что в отличие от предыдущего примера, пара «ключ-значение» чувствительна к регистру.
Подобно JSON и текстовому контенту, мы можем использовать запросы для чтения контента ответа в байтах для нетекстовых запросов, используя свойство .content. Это автоматически декодирует gzip и дефлирует закодированные файлы.
GET и POST запросы с использованием Python
Существует два метода запросов HTTP (протокол передачи гипертекста): запросы GET и POST в Python.
Что такое HTTP/HTTPS?
HTTP — это набор протоколов, предназначенных для обеспечения связи между клиентами и серверами. Он работает как протокол запроса-ответа между клиентом и сервером.
Веб-браузер может быть клиентом, а приложение на компьютере, на котором размещен веб-сайт, может быть сервером.
Итак, чтобы запросить ответ у сервера, в основном используют два метода:
- GET: запросить данные с сервера. Т.е. мы отправляем только URL (HTTP) запрос без данных. Метод HTTP GET предназначен для получения информации от сервера. В рамках GET-запроса некоторые данные могут быть переданы в строке запроса URI в формате параметров (например, условия поиска, диапазоны дат, ID Объекта, номер счетчика и т.д.).
- POST: отправить данные для обработки на сервер (и получить ответ от сервера). Мы отправляем набор информации, набор параметров для API. Метод запроса POST предназначен для запроса, при котором веб-сервер принимает данные, заключённые в тело сообщения POST запроса.
Чтобы сделать HTTP-запросы в python, мы можем использовать несколько HTTP-библиотек, таких как:
- HTTPLIB
- URLLIB
- REQUESTS
Самая элегантная и простая из перечисленных выше библиотек — это Requests. Библиотека запросов не является частью стандартной библиотеки Python, поэтому вам нужно установить ее, чтобы начать работать с ней.
Если вы используете pip для управления вашими пакетами Python, вы можете устанавливать запросы, используя следующую команду:
pip install requests
Если вы используете conda, вам понадобится следующая команда:
conda install requests
После того, как вы установили библиотеку, вам нужно будет ее импортировать
Давайте начнем с этого важного шага:
import requests
Синтаксис / структура получения данных через GET/POST запросы к API
Есть много разных типов запросов. Наиболее часто используемый, GET запрос, используется для получения данных.
Когда мы делаем запрос, ответ от API сопровождается кодом ответа, который сообщает нам, был ли наш запрос успешным. Коды ответов важны, потому что они немедленно сообщают нам, если что-то пошло не так.
Чтобы сделать запрос «GET», мы будем использовать функцию.
Метод используется, когда вы хотите отправить некоторые данные на сервер.
Ниже приведена подборка различных примеров использования запросов GET и POST через библиотеку REQUESTS. Безусловно, существует еще больше разных случаев. Всегда прежде чем, писать запрос, необходимо обратиться к официальной документации API (например, у Yandex есть документация к API различных сервисов, у Bitrix24 есть документация к API, у AmoCRM есть дока по API, у сервисов Google есть дока по API и т.д.). Вы смотрите какие методы есть у API, какие запросы API принимает, какие данные нужны для API, чтобы он мог выдать информацию в соответствии с запросом. Как авторизоваться, как обновлять ключи доступа (access_token). Все эти моменты могут быть реализованы по разному и всегда нужно ответ искать в официальной документации у поставщика API.
#GET запрос без параметров
response = requests.get('https://api-server-name.com/methodname_get')
#GET запрос с параметрами в URL
response = requests.get("https://api-server-name.com/methodname_get?param1=ford¶m2=-234¶m3=8267")
# URL запроса преобразуется в формат https://api-server-name.com/methodname_get?key2=value2&key1=value1
param_request = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://api-server-name.com/methodname_get', params=param_request)
#GET запрос с заголовком
url = 'https://api-server-name.com/methodname_get'
headers = {'user-agent': 'my-app/0.0.1'}
response = requests.get(url, headers=headers)
#POST запрос с параметрами в запросе
response = requests.post('https://api-server-name.com/methodname_post', data = {'key':'value'})
#POST запрос с параметрами через кортеж
param_tuples =
response = requests.post('https://api-server-name.com/methodname_post', data=param_tuples)
#POST запрос с параметрами через словарь
param_dict = {'param': }
response = requests.post('https://api-server-name.com/methodname_post', data=payload_dict)
#POST запрос с параметрами в формате JSON
import json
url = 'https://api-server-name.com/methodname_post'
param_dict = {'param': 'data'}
response = requests.post(url, data=json.dumps(param_dict))
Использование Translate API
Теперь перейдем к чему-то более интересному. Мы используем API Яндекс.Перевод (Yandex Translate API) для выполнения запроса на перевод текста на другой язык.
Чтобы использовать API, нужно предварительно войти в систему. После входа в систему перейдите к Translate API и создайте ключ API. Когда у вас будет ключ API, добавьте его в свой файл в качестве константы. Далее приведена ссылка, с помощью которой вы можете сделать все перечисленное: https://tech.yandex.com/translate/
script.py
Ключ API нужен, чтобы Яндекс мог проводить аутентификацию каждый раз, когда мы хотим использовать его API. Ключ API представляет собой облегченную форму аутентификации, поскольку он добавляется в конце URL запроса при отправке.
Чтобы узнать, какой URL нам нужно отправить для использования API, посмотрим документацию Яндекса.
Там мы найдем всю информацию, необходимую для использования их Translate API для перевода текста.

Если вы видите URL с символами амперсанда (&), знаками вопроса (?) или знаками равенства (=), вы можете быть уверены, что это URL запроса GET. Эти символы задают сопутствующие параметры для URL.
Обычно все, что размещено в квадратных скобках ([]), будет необязательным. В данном случае для запроса необязательны формат, опции и обратная связь, но обязательны параметры key, text и lang.
Добавим код для отправки на этот URL. Замените первый созданный нами запрос на следующий:
script.py
Существует два способа добавления параметров. Мы можем прямо добавить параметры в конец URL, или библиотека Requests может сделать это за нас. Для последнего нам потребуется создать словарь параметров. Нам нужно указать три элемента: ключ, текст и язык. Создадим словарь, используя ключ API, текст и язык , т. к. нам требуется перевод с английского на испанский.
Другие коды языков можно посмотреть здесь. Нам нужен столбец 639-1.
Мы создаем словарь параметров, используя функцию , и передаем ключи и значения, которые хотим использовать в нашем словаре.
script.py
Теперь возьмем словарь параметров и передадим его функции .
script.py
Когда мы передаем параметры таким образом, Requests автоматически добавляет параметры в URL за нас.
Теперь добавим команду печати текста ответа и посмотрим, что мы получим в результате.
script.py

Мы видим три вещи. Мы видим код состояния, который совпадает с кодом состояния ответа, мы видим заданный нами язык и мы видим переведенный текст внутри списка. Итак, мы должны увидеть переведенный текст .
Повторите эту процедуру с кодом языка en-fr, и вы получите ответ .
script.py

Посмотрим заголовки полученного ответа.
script.py

Разумеется, заголовки должны быть другими, поскольку мы взаимодействуем с другим сервером, но в данном случае мы видим тип контента application/json вместо text/html. Это означает, что эти данные могут быть интерпретированы в формате JSON.
Если ответ имеет тип контента application/json, библиотека Requests может конвертировать его в словарь и список, чтобы нам было удобнее просматривать данные.
Для обработки данных в формате JSON мы используем метод на объекте response.
Если вы распечатаете его, вы увидите те же данные, но в немного другом формате.
script.py
 Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Допустим, нам нужно получить доступ к тексту. Поскольку сейчас это словарь, мы можем использовать ключ текста.
script.py
 Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
script.py

Теперь мы видим только переведенное слово.
Разумеется, если мы изменим параметры, мы получим другие результаты. Изменим переводимый текст с на , изменим язык перевода на испанский и снова отправим запрос.
script.py
 Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.
Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.




