Парсинг
Содержание:
- Как пользоваться парсером?
- Парсите страницы сайтов в структуры данных
- Основные понятия
- Что такое парсинг сайта
- cURL и аутентификация в веб-формах (передача данных методом GET и POST)
- Правовые нормы, применяемые к парсингу
- A-Parser — парсер для профессионалов#
- Обзор лучших парсеров
- Ограничения при парсинге
- Парсить — что это обозначает простыми словами?
- Парсеры поисковых систем#
- Как работает парсинг, что это такое? Алгоритм работы парсера
- Парсер как функтор
- Еще пару парсеров для примера
- Выводы
Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
- актуализация информации о цене той или иной товарной единицы,
- парсинг каталога товаров с сайтов поставщиков или конкурентов.
В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов. Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
Парсите страницы сайтов в структуры данных
Что такое Диггернаут и что такое диггер?

Диггернаут — это облачный сервис для парсинга сайтов, сбора информации и других ETL (Extract, Transform, Load) задач. Если ваш бизнес лежит в плоскости торговли и ваш поставщик не предоставляет вам данные в нужном вам формате, например в csv или excel, мы можем вам помочь избежать ручной работы, сэкономив ваши время и деньги!
Все, что вам нужно сделать — создать парсер (диггер), крошечного робота, который будет парсить сайты по вашему запросу, извлекать данные, нормализовать и обрабатывать их, сохранять массивы данных в облаке, откуда вы сможете скачать их в любом из доступных форматов (например, CSV, XML, XLSX, JSON) или забрать в автоматическом режиме через наш API.
Какую информацию может добывать Диггернаут?

- Цены и другую информацию о товарах, отзывы и рейтинги с сайтов ритейлеров.
- Данные о различных событиях по всему миру.
- Новости и заголовки с сайтов различных новостных агентств и агрегаторов.
- Данные для статистических исследований из различных источников.
- Открытые данные из государственных и муниципальных источников. Полицейские сводки, документы по судопроизводству, росреест, госзакупки и другие.
- Лицензии и разрешения, выданные государственными структурами.
- Мнения людей и их комментарии по определенной проблематике на форумах и в соцсетях.
- Информация, помогающая в оценке недвижимости.
- Или что-то иное, что можно добыть с помощью парсинга.
Должен ли я быть экспертом в программировании?

Если вы никогда не сталкивались с программированием, вы можете использовать наш специальный инструмент для построения конфигурации парсера (диггера) — Excavator. Он имеет графическую оболочку и позволяет работать с сервисом людям, не имеющих теоретических познаний в программировании. Вам нужно лишь выделить данные, которые нужно забрать и разместить их в структуре данных, которую создаст для вас парсер. Для более простого освоения этого инструмента, мы создали серию видео уроков, с которыми вы можете ознакомиться в документации.
Если вы программист или веб-разработчик, знаете что такое HTML/CSS и готовы к изучению нового, для вас мы приготовили мета-язык, освоив который вы сможете решать очень сложные задачи, которые невозможно решить с помощью конфигуратора Excavator. Вы можете ознакомиться с документацией, которую мы снабдили примерами из реальной жизни для простого и быстрого понимания материала.
Если вы не хотите тратить свое время на освоение конфигуратора Excavator или мета-языка и хотите просто получать данные, обратитесь к нам и мы создадим для вас парсер в кратчайшие сроки.
Основные понятия
- входной символьный поток (далее входной поток или поток) — поток символов для разбора, подаваемый на вход парсера
- parser/парсер (разборщик, анализатор) — программа, принимающая входной поток и преобразующая его в AST и/или позволяющая привязать исполняемые функции к элементам грамматики
- AST(Abstract Syntax Tree)/АСД(Абстрактное синтаксическое дерево) (выходная структура данных) — Структура объектов, представляющая иерархию нетерминальных сущностей грамматики разбираемого потока и составляющих их терминалов. Например, алгебраический поток (1 + 2) + 3 можно представить в виде ВЫРАЖЕНИЕ(ВЫРАЖЕНИЕ(ЧИСЛО(1) ОПЕРАТОР(+) ЧИСЛО(2)) ОПЕРАТОР(+) ЧИСЛО(3)). Как правило, потом это дерево как-то обрабатывается клиентом парсера для получения результатов (например, подсчета ответа данного выражения)
- CFG(Context-free grammar)/КСГ(Контекстно-свободная грамматика) — вид наиболее распространенной грамматики, используемый для описания входящего потока символов для парсера (не только для этого, разумеется). Характеризуется тем, что использование её правил не зависит от контекста (что не исключает того, что она в некотором роде задает себе контекст сама, например правило для вызова функции не будет иметь значения, если находится внутри фрагмента потока, описываемого правилом комментария). Состоит из правил продукции, заданных для терминальных и не терминальных символов.
- Терминальные символы (терминалы) — для заданного языка разбора — набор всех (атомарных) символов, которые могут встречаться во входящем потоке
- Не терминальные символы (не терминалы) — для заданного языка разбора — набор всех символов, не встречающихся во входном потоке, но участвующих в правилах грамматики.
- язык разбора (в большинстве случаев будет КСЯ(контекстно-свободный язык)) — совокупность всех терминальных и не терминальных символов, а также КСГ для данного входного потока. Для примера, в естественных языках терминальными символами будут все буквы, цифры и знаки препинания, используемые языком, не терминалами будут слова и предложения (и другие конструкции, вроде подлежащего, сказуемого, глаголов, наречий и т.п.), а грамматикой собственно грамматика языка.
-
BNF(Backus-Naur Form, Backus normal form)/БНФ(Бэкуса-Наура форма) — форма, в которой одни синтаксические категории последовательно определяются через другие. Форма представления КСГ, часто используемая непосредственно для задания входа парсеру. Характеризуется тем, что определяемым является всегда ОДИН нетерминальный символ. Классической является форма записи вида:
Так же существует ряд разновидностей, таких как ABNF(AugmentedBNF), EBNF(ExtendedBNF) и др. В общем, эти формы несколько расширяют синтаксис обычной записи BNF. - LL(k), LR(k), SLR,… — виды алгоритмов парсеров. В этой статье мы не будем подробно на них останавливаться, если кого-то заинтересовало, внизу я дам несколько ссылок на материал, из которого можно о них узнать. Однако остановимся подробнее на другом аспекте, на грамматиках парсеров. Грамматика LL/LR групп парсеров является BNF, это верно. Но верно также, что не всякая грамматика BNF является также LL(k) или LR(k). Да и вообще, что значит буква k в записи LL/LR(k)? Она означает, что для разбора грамматики требуется заглянуть вперед максимум на k терминальных символов по потоку. То есть для разбора (0) грамматики требуется знать только текущий символ. Для (1) — требуется знать текущий и 1 следующий символ. Для (2) — текущий и 2 следующих и т.д. Немного подробнее о выборе/составлении BNF для конкретного парсера поговорим ниже.
- PEG(Parsing expression grammar)/РВ-грамматика — грамматика, созданная для распознавания строк в языке. Примером такой грамматики для алгебраических действий +, -, *, / для неотрицательных чисел является:
Что такое парсинг сайта
 Здравствуйте, друзья! Что такое парсинг сайтов? Это синтаксический анализ или сбор данных. С английского языка переводится, как parsing, что значит парсинг или парсить. Если говорить по-простому, то парсинг сайта – это процесс сбора данных с различных ресурсов Интернета. Данный процесс автоматизируют с помощью специальных программ парсеров. Они собирают данные с помощью ботов, и структурируют информацию в качестве таблиц, документов, набор данных. Также, парсинг можно делать вручную, но это отнимает время.
Здравствуйте, друзья! Что такое парсинг сайтов? Это синтаксический анализ или сбор данных. С английского языка переводится, как parsing, что значит парсинг или парсить. Если говорить по-простому, то парсинг сайта – это процесс сбора данных с различных ресурсов Интернета. Данный процесс автоматизируют с помощью специальных программ парсеров. Они собирают данные с помощью ботов, и структурируют информацию в качестве таблиц, документов, набор данных. Также, парсинг можно делать вручную, но это отнимает время.
Рассмотрим наглядный пример из жизни, чтобы вы понимали, как работает парсинг. Допустим, открылся новый магазин и необходимо правильно подобрать цены для товаров. В таком случае, нанимают человека для анализа и рассмотрения цен у конкурентов. После сбора информации, создатели магазина принимают решение установить цену на товар, например, ниже, чем у конкурентов. С помощью парсинга в Сети можно делать многое. Об этом мы расскажем далее в статье.
cURL и аутентификация в веб-формах (передача данных методом GET и POST)
Аутентификация в веб-формах – это тот случай, когда мы вводим логин и пароль в форму на сайте. Именно такая аутентификация используется при входе в почту, на форумы и т. д.
Использование curl для получения страницы после HTTP аутентификации очень сильно различается в зависимости от конкретного сайта и его движка. Обычно, схема действий следующая:
1) С помощью Burp Suite или Wireshark узнать, как именно происходит передача данных. Необходимо знать: адрес страницы, на которую происходит передача данных, метод передачи (GET или POST), передаваемая строка.
2) Когда информация собрана, то curl запускается дважды – в первый раз для аутентификации и получения кукиз, второй раз – с использованием полученных кукиз происходит обращение к странице, на которой содержаться нужные сведения.
Используя веб-браузер, для нас получение и использование кукиз происходит незаметно. При переходе на другую страницу или даже закрытии браузера, кукиз не стираются – они хранятся на компьютере и используются при заходе на сайт, для которого предназначены. Но curl по умолчанию кукиз не хранит. И поэтому после успешной аутентификации на сайте с помощью curl, если мы не позаботившись о кукиз вновь запустим curl, мы не сможем получить данные.
Для сохранения кукиз используется опция —cookie-jar, после которой нужно указать имя файла. Для передачи данных методом POST используется опция —data. Пример (пароль заменён на неверный):
curl --cookie-jar cookies.txt http://forum.ru-board.com/misc.cgi --data 'action=dologin&inmembername=f123gh4t6&inpassword=111222333&ref=http%3A%2F%2Fforum.ru-board.com%2Fmisc.cgi%3Faction%3Dlogout'
Далее для получения информации со страницы, доступ на которую имеют только зарегестрированные пользователи, нужно использовать опцию -b, после которой нужно указать путь до файла с ранее сохранёнными кукиз:
curl -b cookies.txt 'http://forum.ru-board.com/topic.cgi?forum=35&topic=80699&start=3040' | iconv -f windows-1251 -t UTF-8
Эта схема может не работать в некоторых случаях, поскольку веб-приложение может требовать указание кукиз при использовании первой команды (встречалось такое поведение на некоторых роутерах), также может понадобиться указать верного реферера, либо другие данные, чтобы аутентификация прошла успешно.
Правовые нормы, применяемые к парсингу
Специфика работы роботов-парсеров и в целом системы парсинга приводит к следующему вопросу: разрешено ли использовать контент, размещенный в свободном доступе на других сайтах, в своих целях? Существуют определенные законодательные нормы, касающиеся вопросов интеллектуальной собственности и размещаемой в интернете информации. Согласно им:
-
запрещен сбор данных, имеющих отношение к коммерческой и государственной тайне;
-
противозаконным является нарушение авторских и смежных прав;
-
под запретом также находится доступ к охраняемой законом информации;
-
наконец, запрещено использовать гражданские права для ограничения конкуренции.
Исходя из этого, парсинг не является противозаконной операцией, но осуществлять его можно только при соблюдении соответствующих условий:
-
исследуемая информация должна находиться в открытом доступе и не быть под защитой закона об авторских и смежных правах;
-
сбор данных не должен приводить к сбоям в работе сети интернет и проблемам с ресурсами, являющимися источниками информации (слишком активная работа парсера может быть принята за DOS-атаку);
-
сбор должен проводиться только законными способами;
-
парсинг не должен ограничивать конкуренцию.
A-Parser — парсер для профессионалов#
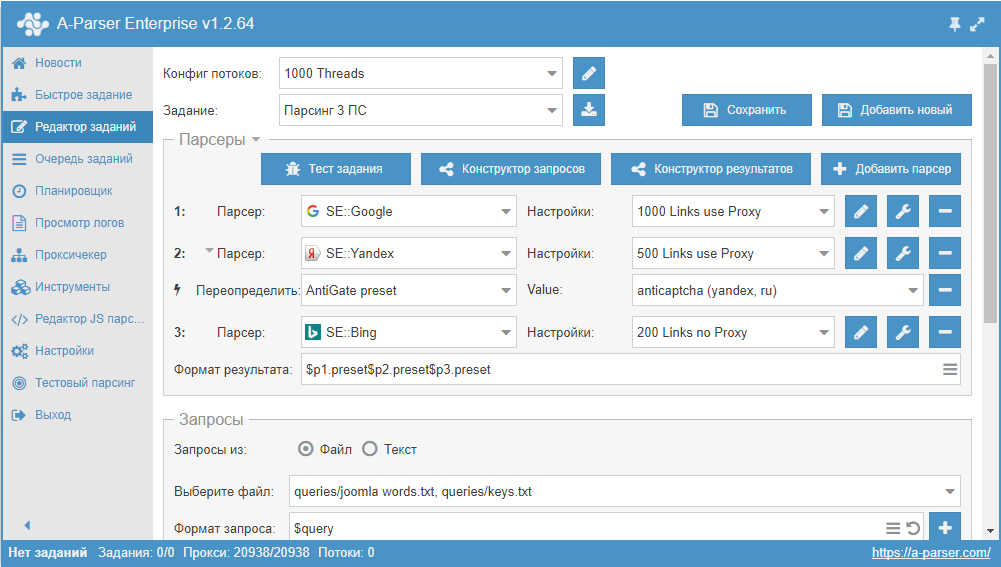
A-Parser — многопоточный парсер поисковых систем, сервисов оценки сайтов, ключевых слов, контента(текст, ссылки, произвольные данные) и других различных сервисов(youtube, картинки, переводчик…), A-Parser содержит более 90 встроенных парсеров.

Ключевыми особенностями A-Parser является поддержка платформ Windows/Linux, веб интерфейс с возможностью удаленного доступа, возможность создания своих собственных парсеров без написания кода, а также возможность создавать парсеры со сложной логикой на языке JavaScript / TypeScript с поддержкой NodeJS модулей.
Производительность, работа с прокси, обход защиты CloudFlare, быстрый HTTP движок, поддержка управления Chrome через puppeteer, управлением парсером по API и многое другое делают A-Parser уникальным решением, в данной документации мы постараемся раскрыть все преимущества A-Parser и способы его использования.
Обзор лучших парсеров
Далее рассмотрим наиболее популярные и востребованные приложения для сканирования сайтов и извлечения из них необходимых данных.
В виде облачных сервисов
Под облачными парсерами подразумеваются веб-сайты и приложения, в которых пользователь вводит инструкции для поиска определенной информации. Оттуда эти инструкции попадают на сервер к компаниям, предлагающим услуги парсинга. Затем на том же ресурсе отображается найденная информация.
Преимущество этого облака заключается в отсутствии необходимости устанавливать дополнительное программное обеспечение на компьютер. А еще у них зачастую есть API, позволяющее настроить поведение парсера под свои нужды. Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
Наиболее популярные облачные парсеры
- Import.io – востребованный набор инструментов для поиска информации на ресурсах. Позволяет парсить неограниченное количество страниц, поддерживает все популярные форматы вывода данных и автоматически создает удобную структуру для восприятия добытой информации.
- Mozenda – сайт для сбора информации с сайтов, которому доверяют крупные компании в духе Tesla. Собирает любые типы данных и конвертирует в необходимый формат (будь то JSON или XML). Первые 30 дней можно пользоваться бесплатно.
- Octoparse – парсер, главным преимуществом которого считается простота. Чтобы его освоить, не придется изучать программирование и хоть какое-то время тратить на работу с кодом. Можно получить необходимую информацию в пару кликов.
- ParseHub – один из немногих полностью бесплатных и довольно продвинутых парсеров.
Похожих сервисов в сети много. Причем как платных, так и бесплатных. Но вышеперечисленные используются чаще остальных.
В виде компьютерных приложений
Есть и десктопные версии. Большая их часть работает только на Windows. То есть для запуска на macOS или Linux придется воспользоваться средствами виртуализации. Либо загрузить виртуальную машину с Windows (актуально в случае с операционной системой Apple), либо установить утилиту в духе Wine (актуально в случае с любым дистрибутивом Linux). Правда, из-за этого для сбора данных потребуется более мощный компьютер.
Наиболее популярные десктопные парсеры
- ParserOK – приложение, сфокусированное на различных типах парсинга данных. Есть настройки для сбора данных о стоимости товаров, настройки для автоматической компиляции каталогов с товарами, номеров, адресов электронной почты и т.п.
- Datacol – универсальный парсер, который, по словам разработчиков, может заменить решения конкурентов в 99% случаев. А еще он прост в освоении.
- Screaming Frog – мощный инструмент для SEO-cпециалистов, позволяющий собрать кучу полезных данных и провести аудит ресурса (найти сломанные ссылки, структуру данных и т.п.). Можно анализировать до 500 ссылок бесплатно.
- Netspeak Spider – еще один популярный продукт, осуществляющий автоматический парсинг сайтов и помогающий проводить SEO-аудит.
Это наиболее востребованные утилиты для парсинга. У каждого из них есть демо-версия для проверки возможностей до приобретения. Бесплатные решения заметно хуже по качеству и часто уступают даже облачным сервисам.
В виде браузерных расширений
Это самый удобный вариант, но при этом наименее функциональный. Расширения хороши тем, что позволяют начать парсинг прямо из браузера, находясь на странице, откуда надо вытащить данные. Не приходится вводить часть параметров вручную.
Но дополнения к браузерам не имеют таких возможностей, как десктопные приложения. Ввиду отсутствия тех же ресурсов, что могут использовать программы для ПК, расширения не могут собирать такие огромные объемы данных.
Но для быстрого анализа данных и экспорта небольшого количества информации в XML такие дополнения подойдут.
Наиболее популярные расширения-парсеры
- Parsers – плагин для извлечения HTML-данных с веб-страниц и импорта их в формат XML или JSON. Расширение запускается на одной странице, автоматически разыскивает похожие страницы и собирает с них аналогичные данные.
- Scraper – собирает информацию в автоматическом режиме, но ограничивает количество собираемых данных.
- Data Scraper – дополнение, в автоматическом режиме собирающее данные со страницы и экспортирующее их в Excel-таблицу. До 500 веб-страниц можно отсканировать бесплатно. За большее количество придется ежемесячно платить.
- kimono – расширение, превращающее любую страницу в структурированное API для извлечения необходимых данных.
Ограничения при парсинге
Есть несколько вариантов ограничений, которые могут затруднить работу парсера:
- По user-agent. Это запрос, в котором программа сообщает сайту о себе. Парсеры банят многие веб-ресурсы. Однако в настройках данные можно изменить на YandexBot или Googlebot и отсылать правильные запросы.
- По robots.txt, в котором прописан запрет для индексации поисковыми роботами Яндекса или (ими мы представились сайту выше) определенных страниц. Необходимо задать в настройках программы игнорирование robots.txt.
- По IP-адресу, если с него в течение долгого времени поступают на сайт однотипные запросы. Решение — использовать VPN.
- По капче. Если действия похожи на автоматические, выводится капча. Научить парсеры распознавать конкретные виды достаточно сложно и дорогостояще.
Парсить — что это обозначает простыми словами?
С появлением новых технологий в нашем обиходе появляются новые слова, значения которых многие не знают и не могут понять, что они означают. Много терминов приходит с других языков. В основном в последние десятилетия они приходят в русский язык из англоязычных стран. Одним из таких является слово «парсить«. Так что же это такое?
Определение
Термин «парсить» пришло в русский из английского языка и означает – разбирать, проводить анализ. Это слово употребляют в своей терминологии разработчики Интернет ресурсов, программисты и т. д. В их среде в большинстве случаев означает поиск и копирование чужого контента на свой сайт, а также процедура разбора, проведения анализа статьи. Ещё в информатике это означает – проведение анализа, при котором разрабатываются математические модели сравнения.
Также означает сбор информации в Интернете, используя для этого специально разработанные программы – «парсеры«, которые позволяют сравнивать предложенные сегменты в разработанной базе с теми, что есть в Интернете. Они часто используются аналитиками, экономистами и бизнесменами в разных сегментах экономики.

Для чего применяются
Сбор сведений для исследования рынка
Такая программный продукт может отследить необходимую информацию, что даст специалисту определить, в каком направлении будет развиваться та или иная компания или отрасль в целом, например, в ближайшие полгода. Таким образом, утилита даёт фундамент, базу специалисту для проведения глубокого анализа, что даст компании поднять свой уровень продаж в своём рыночном секторе услуг или производства.
Подобная утилита способна получать информацию от многих источников, которые специализируются на проведении аналитики и компаний по исследованию рынка. И только потом можно будет объединять все полученные сведения для сравнения и проведения глубокого анализа.
Отбор сотрудников или поиск работы
Для работодателя, который динамично разыскивает претендентов в интересах принятия на работу в свою фирму, либо для соискателя, который подыскивает себе работу с определённой должностью, подобная разработка также будет востребована. С её помощью проводится настройка и подборка исходных данных в базе разных применяемых фильтров и результативно извлекать нужное, без обыденного поиска вручную.
Получение сведений
- Так же их применяют, для того чтобы составлять и классифицировать информацию:
- почтовые или электронные адреса,
- контакты с разных веб-сайтов и соцсетей.
Это даёт возможность создавать простые списки контактов и целой сопутствующих данных в интересах бизнеса – о покупателях, посредниках либо изготовителях.
- Изучение стоимости товара в различных онлайн магазинах
- Такие ресурсы могут быть полезны и тем, кто оживлённо пользуется предложениями онлайн магазинов, следит за ценами на продукты питания, разыскивает товары на многих сайтах одновременно.
Самые известные парсеры
https://youtube.com/watch?v=6Anf5nIhuCI
Самые крупные и известные системы, которые занимаются парсером – это, конечно же, Яндекс и Google. Их программы, когда юзер хочет что-то найти во Всемирной паутине и вводит в поисковик, что именно необходимо ему найти, начинают искать из десятков миллионов веб-ресурсов именно то, что нужно юзеру. Выдают ему несколько сотен сайтов на выбранную тему, из которых он ищет необходимую ему информацию.
А перечисленные выше возможности программ для того чтобы «парсить» являются более узкоспециализированными, и их программисты разрабатывают для различных крупных фирм, которые с их помощью определяют свои возможности и конкурентов. Всё это облегчает проведение необходимых мероприятий, так как происходит всё в автоматическом режиме, и специалист может получить всё нужное в виде таблиц или графиков, что упрощает его дальнейшую работу. Ему не нужно тратит драгоценное время на поиск.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
Как работает парсинг, что это такое? Алгоритм работы парсера
Независимо от того на каком формальном языке программирования написан парсер, алгоритм его действия остается одинаковым:
- выход в интернет, получение доступа к коду веб-ресурса и его скачивание;
- чтение, извлечение и обработка данных;
- представление извлеченных данных в удобоваримом виде – файлы .txt, .sql, .xml, .html и других форматах.
В интернете часто встречаются выражения, из которых следует, будто парсер (поисковый робот, бот) путешествует по Всемирной сети. Но зачастую эта программа никогда не покидает компьютера, на котором она инсталлирована.
Этим парсер коренным образом отличается от компьютерного вируса – автономной программы, способной к размножению, хотя по сути своей работы он похож на трояна. Ведь он получает данные, иногда конфиденциального характера, не спрашивая желания их владельца.
Парсер как функтор
Можно выделить целый класс типов-контейнеров, для которых верно следующее: если известно, как преобразовывать объекты внутри контейнера, то можно преобразовывать и сами контейнеры. Простейший пример — список в качестве контейнера и функция , которая есть практически во всех высокоуровневых языках. Действительно, можно пройтись по всем элементам списка типа , применить к каждому функцию и получить список типа .
Такой класс типов называется , у класса есть один метод :
Предположим, что мы уже умеем разбирать строки в объекты некоторого типа , и, кроме того, знаем, как преобразовать объекты типа в объекты типа . Можно ли сказать, что тогда есть парсер для объектов типа ?
Если выразить это в виде функции, то она будет иметь следующий тип:
Этот тип совпадает с типом функции , поэтому попробуем сделать парсер функтором. Создадим с нуля парсер значений типа , который будет сначала вызывать первый парсер (он у нас уже есть), а затем применять функцию к результатам его разбора.
У функции есть удобный инфиксный синоним: .
Если в качестве аргумента использовать функцию, просто заменяющую свой первый аргумент на новое значение, то получим ещё одну полезную операцию, которая уже реализована для всех функторов даже в двух экземплярах (они отличаются только порядком аргументов):
Помните парсер, который пропускает определённую строку ()? Теперь можно его реализовать следующим образом:
Еще пару парсеров для примера
Как я уже говорил — парсеров огромное количество и они созданы под разные сайты и задачи. Для примера разберем еще парочку парсеров, чтобы у вас сложилось полное понимание этой сферы.
К примеру есть парсер turboparser.ru — он считается одним из самых удобных парсеров, помогающих организаторам совместных покупок.
Данный сервис позволяет пропарсить:
- весь каталог или раздел сайта в несколько кликов;
- любую страницу сайта поставщика путем нажатия на специальную кнопку;
- делать парсинг с вводом ссылки в адресную строку;
- делать сбор при помощи виджета (отдельного элемента или информационного блока на сайте).
Среди основных преимуществ ТурбоПарсера:
Отметить отдельно хочется и Grably-parser.ru – тоже парсер. Что это за программа? В общем-то, это первый бесплатный парсер с аналогичными функциями. Чтобы воспользоваться его преимуществами, достаточно зарегистрироваться на сайте. После этого вы уже сразу сможете пользоваться функционалом сайта: быстро найти описание, фото и характеристики нужных товаров, создать каталоги, спарсить нужный сайт. Грабли-парсер имеют техническую поддержку как на аналогичных платных ресурсах.
Выводы
- Если речь про сервисы и облачные решения, то парсеры могут копировать данные с сайта и предоставлять их пользователям от имени иного бренда;
- Если речь про сайт информационного плана, то весь скопированный и размещенный в сети контент может быть проиндексирован поисковыми системами. В результате оригинальный источник будет терять трафик.
- Идентифицируйте роботов на основе данных о трафике, к примеру используя Google reCAPTCHA;
- Создайте белый и черный списки роботов;
- Настройте систему анализа и блокировки роботов.
капч
- Защита от парсинга сайта;
- Снижение нагрузки на сервер сайта. Увеличение скорости загрузки страниц;
- Защита от спама, который роботы создают для усложнения выполнения работ по аналитике;
- Блокировка спама в комментариях;
- Защита от анализа сайта злоумышленниками с использованием роботов;
- Защита от подбора паролей;
- Защита от сервисов конкурентной разведки;
- Защита от анализа сайта роботами на предмет возможности XSS и SQL инъекций.
парсинг цен
- Как удалить страницы конкурентов из поисковой выдачи, если на них размещен скопированный контент? Что такое DMCA?;
- Как извлечь пользу, если контент скопировали? Как защитить контент от копирования на уровне сервера?
лишь часть аудитории
С этим читают





