Какие страницы следует закрывать от индексации
Содержание:
- Закрываем от индексации поисковиков
- Зачем закрывать сайт от индексации
- Как понимать «Попросить поисковые системы не индексировать сайт»
- Внутренние ссылки
- Ошибки использования robots и X-Robots-Tag
- Индексация сайта в поиске
- Способ от программистов. Через тег meta robots
- Польза метатега robots и X-Robots-Tag для SEO
- Популярные статьи
- Пример настройки файла robots.txt
- Robots.txt для Яндекса и Google
- Директивы robots.txt и правила настройки
- Правильный robots.txt для Joomla
- Noindex
- Использование спецсимволов в командах robots.txt
- Закрытие от индексации Раздела по параметру в URL
- Как закрыть страницу от индексации?
- Шаг 2 — Защита вашего сайта WordPress паролем
- Зачем сайт закрывают для индекса?
- От сисадмина. Запрет по Useragent через .htaccess
Закрываем от индексации поисковиков
Перед тем как рассказать о способе с применением robots.txt, мы покажем, как на WordPress закрыть от индексации сайт через админку. В настройках (раздел чтение), есть удобная функция:

Можно убрать видимость сайта, но обратите внимание на подсказку. В ней говорится, что поисковые системы всё же могут индексировать ресурс, поэтому лучше воспользоваться проверенным способом и добавить нужный код в robots.txt
Текстовый файл robots находится в корне сайта, а если его там нет, создайте его через блокнот.
Закрыть сайт от индексации поможет следующий код:
User-agent: *
Disallow: /
Просто добавьте его на первую строчку (замените уже имеющиеся строчки). Если нужно закрыть сайт только от Яндекса, вместо звездочки указывайте Yandex, если закрываете ресурс от Google, вставляйте Googlebot.
Когда проделаете эти действия, сайт больше не будет индексироваться, это самый лучший способ для закрытия ресурса от поисковых роботов.
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых
систем может быть множество. Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.

Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы
находитесь в стадии разработки (или доработки) ресурса. В таком случае его
лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в
индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной
готовности и наполненности контентом.

Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.

Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.

Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах. В этом случае, может потребоваться закрытие какого-либо домена в какой-либо поисковой системе.

Как понимать «Попросить поисковые системы не индексировать сайт»
Вы задумывались, как поисковые системы индексируют сайт и оценивают его SEO? Они делают это с помощью автоматизированной программы, называемой пауком, также известной как робот или краулер. Пауки «ползают» по сети, посещая веб-сайты и регистрируя их контент. Google использует их, чтобы ранжировать и размещать веб-сайты в результатах поиска, извлекать фрагменты текста из статей для страницы результатов поиска и вставлять изображения в Картинки Google.
Когда устанавливается флажок «Попросить поисковые системы не индексировать сайт», WordPress изменяет файл robots.txt (файл, дающий паукам инструкции о том, как сканировать сайт). А еще может добавить метатег в заголовок сайта, который сообщает Google и другим поисковым системам, что сайт или какой-либо контент закрыт от индексации.
Ключевое слово здесь – «попросить»: поисковые системы не обязаны выполнять этот запрос, особенно поисковые системы, не использующие стандартный синтаксис robots.txt, который использует Google.
Сканеры по-прежнему смогут найти ваш сайт. Но правильно настроенные сканеры прочитают файл robots.txt и уйдут, не индексируя контент и не показывая его в результатах поиска.
В прошлом эта опция в WordPress не мешала Google показывать веб-сайт в результатах поиска, просто индексируя его контент. Вы по-прежнему можете видеть, что ваши страницы отображаются в результатах поиска с ошибкой типа «Информация для этой страницы недоступна» или «Описание этого результата недоступно из-за файла robots.txt сайта».
Хотя Google не индексировал страницу, он также и не скрывал ее полностью. Эта аномалия привела к тому, что люди могли посещать страницы, которые им не предназначались. Благодаря WordPress 5.3 теперь он работает правильно, блокируя как индексацию, так и листинг сайта.
Представляете, как это разрушит SEO сайта, если случайно будет включен этот флажок? Критически важно использовать эту опцию только в том случае, если вы действительно не хотите, чтобы кто-либо видел контент – и даже в этом случае это не единственная мера, которую нужно предпринять
Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.

Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:

Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег на
При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Ошибки использования robots и X-Robots-Tag
Несогласованность с файлом robots.txt
В официальных справках по X-Robots-Tag и метатегу robots в Google и Яндексе сказано, что у поискового робота должен быть доступ к сканированию контента, который нужно скрыть из индекса. В этом случае указание директивы disallow для определенной страницы в файле robots.txt делает невидимыми директивы страницы, в том числе запрещающие индексацию.
Еще одной ошибкой является попытка запретить индексацию страниц с помощью robots.txt. Основная функция robots.txt — в ограничении сканирования, а не запрете индексации. Следовательно, для управления отображением страниц в поиске нужно использовать метатег robots и тег x-robots.
Несвоевременное удаление атрибута noindex с актуальной страницы
Если вы используете директиву noindex, чтобы временно скрыть контент из индекса, важно вовремя удалить ее со страницы и открыть роботу доступ. Например, это может быть страница с запланированным акционным предложением, которое уже вступило в силу
Или же станица, которая была в процессе разработки и теперь полностью готова. Если директиву не убрать, страница не появится в выдаче, а значит не будет генерировать трафик.
Наличие обратных ссылок на страницу с атрибутом nofollow
Команда nofollow может не сработать, если сама страница — не единственный способ для поисковика узнать об URL-адресах, и на них ведут внешние ссылки с «открытых» источников.
Удаление URL-адреса из карты сайта до его деиндексации
Если страница содержит директиву noindex или отдает запрет индексации URL, стоит ли ее удалить из файла sitemap.xml? Такое решение будет неверным, поскольку карта сайта дает роботу возможность быстрее находить все страницы, в том числе те, которые нужно убрать из индекса.
Правильным решением будет создать отдельный файл sitemap.xml со списком страниц, содержащих директивы noindex, и удалять URL оттуда по мере их деиндексации. Чтобы ускорить процесс обхода дополнительной карты сайта роботом, можно загрузить ее в Google Search Console или Яндекс.Вебмастер.
Отсутствие проверки индексации после внесения изменений
При самостоятельной настройке индексации или в ходе работы программиста бывают ситуации, когда важный контент ошибочно оказался под запретом индексации. После внесения изменений страницы сайта нужно проверять.
Как избежать ошибочной деиндексации важных страниц?
Кроме проверки индексации URL указанными выше способами, можно отследить изменения кода на сайте с помощью инструмента «Отслеживание изменений» в SE Ranking.
Как быть, если актуальная страница перестала отображаться в поиске?
Необходимо удалить директивы, запрещающие индексацию страницы, а также проверить, нет ли запрета ее сканирования командой disallow в robots.txt и указан ли ее адрес в файле sitemap. Запросить индексацию URL, а также уведомить поисковики об обновленной карте сайта можно через Яндекс.Вебмастер и Google Search Console.
Больше информации можно найти в статье о принципах индексации сайта в поисковиках.
Индексация сайта в поиске
Теперь, когда мы рассказали, что такое индексация, почему она так важна и как её проверить, приступим к практике.
Как ускорить индексацию?
Мы писали выше, что управлять индексацией, что бы кто не говорил, вы не можете. Но повлиять на процесс или даже ускорить возможно.
Советы по ускорению индексации
- Обязательно добавьте сайт во все сервисы Яндекса и Google, особенно в Яндекс Вебмастер и Google Search Console.
- Создайте sitemap.xml, поместите карту в корень сайта и постоянно обновляйте.
- Следите за robots.txt и исключайте ненужные страницы (об этом ниже).
- Выберите надёжный и быстрый хостинг, чтобы робот мог беспрепятственно индексировать содержимое сайта.
- Используйте инструменты Яндекс Вебмастера (Индексирование → Переобход страниц) и Google Search Console (Проверка URL → Запросить индексирование). Способ идеально подходит для работы с отдельными страницами.
- Если ваша CMS любит создавать дубли (например, Битрикс), то используйте атрибут rel=canonical.
- Автоматизируйте создание новых ссылок со старых страниц. Как вариант, можно сделать блок на главной с новыми товарами или статьями.
- Ведите соцсети и анонсируйте новые товары, услуги, страницы. Замечено, что ссылки с соцсетей могут ускорить процесс.
- Создавайте качественный контент на каждой странице. Под качественным контентом мы понимаем актуальную, релевантную и уникальную информацию для пользователей.
- Работайте над структурой сайта и делайте её удобной и понятной пользователю. Помните о правиле 3 кликов: это оптимальное количество действий для пользователя.
- Проверяйте периодически сайт на вирусы и санкции поисковых систем. В Яндекс Вебмастере раздел Диагностика → Безопасность и нарушения, в Google Search Console — раздел Проблемы безопасности и меры, принятые вручную.
- Улучшайте свой ссылочный профиль и пишите анонсы на других сайтах (в рамках правил поисковых систем).
- Используйте родные браузеры (Chrome, Яндекс Браузер) и заходите на новые страницы с них.
Как запретить индексацию?
Выше мы рассмотрели основные способы, как ускорить индексацию, и рассказали, что такое краулинговый бюджет и почему он ограничен для каждого сайта. Поэтому чтобы его не тратить зря, советуем закрывать от индексации служебные и технические страницы, кабинеты пользователей и конфиденциальную информацию, а также страницы в разработке и дубли.
3 основных способа запретить индексацию:
- Директива Disallow в файле robots. Мы писали, что такой запрет может не сработать в отдельных случаях. Тем не менее это основной способ запрета индексации.
- В коде страницы указать метатег robots с директивой noindex (для текста) и/или nofollow (для ссылок). Хорошо подходит для запрета индексации отдельных страниц.
- Настроить HTTP-заголовок X-Robots-Tag с директивой noindex и/или nofollow. Лучше всего подходит для закрытия индексации не HTML-файлов (PDF, изображения, видео и другие).
Используйте все наши советы по улучшению индексации на полную мощь.
Максимальное внимание уделите улучшению структуры и навигации и обновлению карты сайта.
Структура сайта должна быть проста и понятна, охватывать весь спектр ключевых запросов, а каждая страница сайта в идеале должна быть доступна в 3–4 клика
Для этого используйте дополнительные блоки на главной странице и в разделах.
Хорошо работает облако тегов: с помощью него часто получается продвигать категории, улучшать навигацию и полно охватывать семантику.
Для многостраничных сайтов действительно важно постоянно обновлять sitemap.xml
Зачастую в таких случаях карту делят на несколько частей, чтобы охватить весь список страниц.
Настройте маски (автоматические шаблоны) метатегов для новых страниц в категориях и каталогах.
Скорее всего, вам не обойтись без команды профессионалов, которые смогут обеспечить техподдержку, производство контента и SEO-продвижение.
Способ от программистов. Через тег meta robots
Если вы закрываете от индексации тестовый сайт, то определить его можно через настройку главного модуля «Установка для разработки». Этот параметр должен быть установлен на всех сайтах для разработки, по правилам Битрикс.
В файл /local/php_interface/init.php, либо в /bitrix/php_interface/init.php, в зависимости от того, какой файл у вас есть, добавляем строки
if (\Bitrix\Main\Config\Option::get('main', 'update_devsrv') === 'Y') {
$APPLICATION->SetPageProperty('robots', 'noindex');
}
Если вы хотите закрыть продакш сайт, то уберите условие, чтобы свойство устанавливалось всегда.
На всём сайте должна появиться такая строчка в исходном коде

Вот что нам говорит гугл по поводу тега.

Что важно понять — если вы заблокируете индексацию через robots.txt, дополнительно через тег meta, а на сайт есть ссылки из вне — сайт попадет в поиск. Уберите запрет из robots.txt
Польза метатега robots и X-Robots-Tag для SEO
Рассмотрим, когда стоит использовать данные теги и как это помогает оптимизировать сайт.
1. Управление индексацией страниц
Не все страницы сайта полезны для привлечения органического трафика. Индексация некоторых из них, например, дублей, может и вовсе навредить видимости ресурса. Поэтому с помощью команды noindex обычно скрывают:
- дубликаты страниц;
- страницы сортировки и фильтров;
- страницы поиска и пагинации;
- служебные и технические страницы;
- сервисные сообщения для клиентов (об успешной регистрации, заказе и т.д.);
- посадочные страницы для рекламных кампаний и тестирования гипотез;
- страницы в процессе наполнения и разработки (лучше закрывать паролем);
- информацию, которая пока не актуальна (будущая акция, запуск новинки, анонсы запланированных мероприятий);
- устаревшие и неэффективные страницы, которые не приносят трафик;
- страницы, которые нужно закрыть от некоторых видов ботов.
2. Управление индексацией файлов определенного формата
От робота можно скрывать не только html-страницы, но и документ с другим расширением, например, страницу изображения или pdf-файл.
3. Сохранение веса страницы
Запрещая роботам переходить по ссылкам с помощью команды nofollow, можно сохранить вес страницы — он не будет передаваться сторонним ресурсам или другим страницам сайта, которые не приоритетны для индексации.
4. Рациональный расход краулингового бюджета
Чем больше ресурс, тем важнее направлять робота только на самые важные страницы. Если поисковики будут сканировать все подряд, краулинговый бюджет исчерпается до того, как робот начнет сканировать ценный для пользователей и SEO-контент. Соответственно, эти страницы не попадут в индекс или окажутся там с опозданием.
Популярные статьи

- 35.4K
- 10 мин.
Сим-сим, откройся: что важно знать о ключевых запросах
Любому человеку, занимающемуся продвижением сайта, необходимо знать, что такое ключевые запросы. Это база, на которой основывается эффективное продвижение сайта
Ключевые слова – это специальные слова или словосочетания, по которым производится поиск информации в интернете. В статье мы расскажем, какие виды ключевых слов бывают, как строятся поисковые запросы, о чем стоит помнить при составлении семантического ядра и многое другое.
- 8 апреля 2019
- Продвижение

- 27.9K
- 10 мин.
ТОП 150 блогов по интернет-маркетингу
Чтобы оставаться в курсе всех событий, которые происходят в области интернет-маркетинга, нужно следить за тематическими СМИ. Для упрощения задачи по поиску информации мы сделали для вас подборку блогов и разбили ее по тематикам.
- 10 марта 2018
- Продвижение

- 117.3K
- 11 мин.
Сколько стоит продвижение сайта в Яндекс и Google?
Яндекс и Google – две очень мощные поисковые системы, которыми пользуется огромное количество людей. В статье мы разберем, сколько стоит продвижение сайта в Яндексе и Google в месяц. Расскажем об особенностях и нюансах оптимизации под каждую из поисковых систем, сравним их с точки зрения цен.
- 18 октября 2019
- Продвижение
Пример настройки файла robots.txt
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд из которого будет подробно рассмотрено в статье.
В данном файле мы видим, что от поисковых систем Яндекс и Google закрыты от индексации все документы на сайте, кроме страницы /test.html
Остальные поисковые системы могут индексировать все документы, кроме:
- документов в разделах /personal/ и /help/
- документа по адресу /index.html
- документов, адреса которых включают параметр clear_cache=Y
Последние две команды требуют отдельного внимания.
Командой /index.html закрыт от индексации дубль главной страницы сайта. Как правило, главная страница доступна по двум адресам:
- site.com
- site.com/index.html или site.com/index.php
Если не закрыть второй адрес от индексации, то в поиске может появиться две главных страницы!
Команда Disallow: /*?clear_cache=Y закрывает от индексации все страницы, в адресах которых используется последовательность символов ?clear_cache=Y. Часто различный функционал на сайте, например, сортировки или формы подбора добавляют к адресам страниц различные параметры, из-за чего генерируется множество страниц-дублей. Закрывая дубли с параметрами от индексации, Вы решаете проблему попадания дублей в базу поисковых систем.
Посмотрите, какие страницы необходимо закрывать от индексации, в статье про проведение технического аудита сайта.
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
 Доступная для пользователей ссылка
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Правильный robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Sitemap: https://site.ru/sitemap.xml
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Правильно настроенный файл robots.txt способен оказать позитивное влияние на продвижение сайта. Если вы хотите избавиться от мусора и навести порядок на сайте, файл robots.txt готов прийти на помощь.
Noindex
Теперь речь пойдёт о теге noidex. Этот тег придумал небезызвестный всем нам поисковик Яндекс.
Он раньше не распознавал тег rel=”nofollow”, поэтому все сеошники пользовались именно тегом noidex для закрытия своих ссылок от индексации Яндекса.
Но вскоре ситуация изменилась — Яндекс стал учитывать nofollow и вебмастера начали очень редко использовать noidex.
Например, различные коды с использование скриптов. Это связано с тем, что тег noidex в отличие от nofollow закрывает от индексации не определённую ссылку, а конкретный участок кода.
На моём блоге я нигде не использую тег noidex, а применяю только nofollow. Вам тоже, врятли, он понадобится.
Даже баннеры на сегодняшний день очень редко выводятся через скрипт. В основном с помощью php-кода:
Однако, если Вам позарез нужно воспользоваться noidex, прописывать его в коде нужно правильно. Вот несколько рекомендаций:
1. Если в коде используется тег, например вида <div>, то <noindex> ставится перед ним и после закрывающегося тега </div>:
2. В любом скрипте тег ставится в начале <noindex> и в конце скрипта </noindex>:
Проверка закрытия ссылок от индексации
Для того, чтобы проверить, если ли у Вас на сайте не закрытые от индексации внешние или ненужные ссылки, можно использовать специальный сервис для анализа продвижения сайтов: http://be1.ru/stat/.
Переходите по этой ссылке, добавляйте свой блог и Вы сможете просмотреть какие ссылки не закрыты от индекса.
Закрытые ссылки вашего блога на этом сервисе будут помечены красными восклицательными знаками !
Это здорово поможет Вам отыскать незакрытые ссылки и исправить положение. Кроме того, этот сервис помогает увидеть ошибки при использовании тега noindex на своём блоге.
Мне кажется, на сегодня всё. Задавайте вопросы, если что-то не понятно. Применяйте на практике этот метод и продвигайте свой блог.
До новых встреч в новых статьях!
Использование спецсимволов в командах robots.txt
В командах robots.txt может использоваться два спецсимвола: * и $:
- Звездочка * заменяет собой любую последовательность символов.
- По умолчанию в конце каждой команды добавляется *. Чтобы отменить это, в конце строки необходимо поставить символ $.
Допустим, у нас имеется сайт с адресом site.com, и мы хотим настроить файл robots.txt для нашего проекта. Разберем действие спецсимволов на примерах:
| Команда | Что обозначает |
| Disallow: /basket/ | Запрещает индексацию всех документов в разделе /basket/, например:site.com/basket/ site.com/basket/2/ site.com/basket/3/ site.com/basket/4/ |
| Disallow: /basket/$ | Запрещает индексацию только документа: site.com/basket/Документы: site.com/basket/2/ site.com/basket/3/ site.com/basket/4/остаются открытыми для индексации. |
Закрытие от индексации Раздела по параметру в URL
Для этого можно использовать 2 метода:
- Txt
- Meta robots
Рассмотрим 1 вариант
К примеру, у нас на сайте есть раздел, в котором находится неуникальная информация или Та информация, которую мы не хотим отдавать на индексацию и вся эта информация находится в 1 папке или 1 разделе сайта.
Тогда для закрытия данной ветки достаточно добавить в Robots.txt такие строки:
Если закрываем папку, то:
Disallow: /папка/
Если закрываем раздел, то:
Disallow: /Раздел/*
Также можно закрыть определенное расшерение файла:
User-agent: *
Disallow: /*.js
Данный метод достаточно прост в использовании, однако как всегда не гарантирует 100% неиндексации.
Потому лучше в добавок делать еще закрытие при помощи
META NAME=»ROBOTS» CONTENT=»NOINDEX”
Который должен быть добавлен в секцию Хед на каждой странице, которую нужно закрыть от индекса.
Точно также можно закрывать от индекса любые параметры Ваших УРЛ, например:
?sort
?price
?”любой повторяющийся параметр”
Однозначно самым простым вариантом является закрытие от индексации при помощи Роботс.тхт, однако, как показывает практика — это не всегда действенный метод.
Как закрыть страницу от индексации?
Если нужно скрыть только одну страницу, то в файле robots нужно будет прописать другой код:
User-agent: *
Disallow: /category/kak-nachat-zarabatyvat
Во второй строчке вам нужно указать адрес страницы, но без названия домена. Как вариант, вы можете закрыть страницу от индексации, если пропишите в её коде:
<META NAME=»ROBOTS» CONTENT=»NOINDEX»>
Это более сложный вариант, но если нет желания добавлять строчки в robots.txt, то это отличный выход. Если вы попали на эту страницу в поисках способа закрытия от индексации дублей, то проще всего добавить все ссылки в robots.
Как закрыть от индексации ссылку или текст?
Здесь тоже нет ничего сложного, нужно лишь добавить специальные теги в код ссылки или окружить её ими:
<noindex>
<a rel=»nofollow» href=»http://Workion.ru/»>Анкор</a>
</noindex>
Используя эти же теги noindex, вы можете скрывать от поисковых систем разный текст. Для этого нужно в редакторе статьи прописать этот тег.
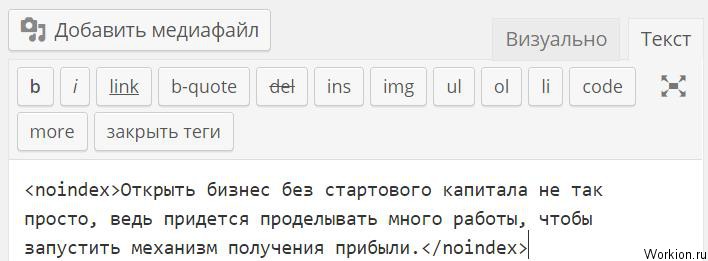
К сожалению, у Google такого тега нет, поэтому скрыть от него часть текста не получится. Самый простой вариант сделать это – добавить изображение с текстом.
Скрывайте от поисковых роботов всё, что не уникально или каким-то образом может нарушать их правила. А если вы решили полностью переделать сайт, то обязательно закрывайте его от индексации, чтобы боты не индексировали внесенные изменения до того, как вы над ними поработаете и всё протестируете.
Вам также будет интересно: — Скорость сайта – важный фактор — Почему Яндекс не индексирует сайт? — Оригинальные тексты для защиты от Yandex
Шаг 2 — Защита вашего сайта WordPress паролем
Поисковые системы и поисковые роботы не имеют доступа к файлам защищенных паролем. Защитить свои файлы паролем можно следующими методами:
Метод 1 — Защита паролем вашего сайта с помощью контрольной панели вашего хостинга
Если вы являетесь клиентом Hostinger, функция защиты паролем может быть легко включена с помощью инструмента под названием Защита Папок Паролем:
- Войдите в контрольную панель Hostinger и нажмите иконку Защита Папок Паролем.

- В левой части выберите каталоги, которые хотите защитить. В нашем случае WordPress установлен в public_html.
- После выбора каталога, введите имя пользователя и пароль в правой панели и нажмите кнопку Защитить.

Если вы используете cPanel, процесс довольно схож:
- Войдите в вашу учетную запись cPanel и нажмите Конфиденциальность каталога.

- Выберите папку в которой установлен WordPress. Обычно это public_html.
- Затем выберите опцию Защитить этот каталог паролем. Далее введите имя каталога, который хотите защитить. Нажмите кнопку Сохранить. Используя форму, создайте учетную запись пользователя для доступа к защищенным каталогам. После завершения нажмите кнопку Сохранить.

Метод 2 — Использование плагинов для защиты WordPress
Вы также можете установить плагины для достижения такого же результата. Существуют различные плагины, которые могут вам в этом помочь. Среди них можно назвать: Password Protected Plugin, WordFence и множество других. Выберите самый свежий плагин и установите его, как только он будет установлен, перейдите в настройки плагина и установите пароль для сайта. Когда ваш сайт станет защищен паролем, поисковые системы не смогут получить к нему доступ и следовательно проиндексировать его.
Зачем сайт закрывают для индекса?
Есть несколько причин, которые заставляют вебмастеров скрывать свои проекты от поисковых роботов. Зачастую к такой процедуре они прибегают в двух случаях:
-
- Когда только создали блог и меняют на нем интерфейс, навигацию и прочие параметры, наполняют его различными материалами. Разумеется, веб-ресурс и контент, содержащийся на нем, будет не таким, каким бы вы хотели его видеть в конечном итоге. Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.
Не думайте, что если ваш ресурс только появился на свет и вы не отправили поисковикам ссылки для его индексации, то они его не заметят. Роботы помимо ссылок учитывают еще и ваши посещения через браузер.
- Иногда разработчикам требуется поставить вторую версию сайта, аналог основной на которой они тестируют доработки, эту версию с дубликатом сайта лучше тоже закрывать от индексации, чтобы она не смогла навредить основному проекту и не ввести поисковые системы в заблуждение.
- Когда только создали блог и меняют на нем интерфейс, навигацию и прочие параметры, наполняют его различными материалами. Разумеется, веб-ресурс и контент, содержащийся на нем, будет не таким, каким бы вы хотели его видеть в конечном итоге. Естественно, пока сайт не доработан, разумно будет закрыть его от индексации Яндекса и Google, чтобы эти мусорные страницы не попадали в индекс.
От сисадмина. Запрет по Useragent через .htaccess
В корне сайт в файл .htaccess требуется добавить стоки
<IfModule mod_setenvif.c>
SetEnvIfNoCase User-Agent Googlebot search_bot
SetEnvIfNoCase User-Agent YandexBot search_bot
SetEnvIfNoCase User-Agent yandex.com/bots search_bot
SetEnvIfNoCase User-Agent Slurp search_bot
SetEnvIfNoCase User-Agent dotbot search_bot
SetEnvIfNoCase User-Agent BLEXbot search_bot
SetEnvIfNoCase User-Agent MJ12bot search_bot
SetEnvIfNoCase User-Agent Ahrefsbot search_bot
SetEnvIfNoCase User-Agent Semrush search_bot
<Limit GET POST>
Order Allow,Deny
Allow from all
Deny from env=search_bot
</Limit>
</IfModule>
Так мы запрещает доступ к серверу пользователям, чье имя браузера содержит Googlebot, YandexBot… Так помечают себя поисковики.
Строка «yandex.com/bots» добавлена, так как имя браузера бота яндекса не всегда содержит YandexBot. Может быть «Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots)». Список всех вариантов роботов от Яндекс.
Так поисковики не смогут попасть на сайт, соответственно не смогут его и проиндексировать. Но работать с . htaccess следует аккуратно, так как можно «положить» весь сайт.
Чтобы проверить способ, в браузер потребуется установить расширение для смены useragent. В маркетплейсе расширений ищите «User agent switcher», устанавливайте любое, в котором можно ставить свое значение, а не только выбирать из списка.. В расширении ставите useragent из списка роботов яндекс, ссылка выше.