Html мета-теги
Содержание:
- Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
- Definition and Usage
- Это будет интересно новичкам
- Charset names
- Syntax[edit]
- Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
- Тег
- Преобразование строки в массив байтов
- Модуль ngx_http_charset_module
- Что такое кодировка
- Понимание Схем Кодирования
- Скалярные значения Юникода
- Расшифровка мира кодировки UTF-8
- HTML Tags
- Другие Места, Где Кодирование Важно
- Java 8 для базы 64
- Is it a ranking factor for SEO?
Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
Программа Faster 9.4 позволяет ускорить процесс работы программиста
(работает в любом текстовом редакторе).
Подсказка при вводе текста на основе ранее введенного текста и настроенных шаблонов.
Программа Faster позволяет делится кодом с другими программистами в два клика или передать ссылку через QR Код.
Исправление введенных фраз двойным Shift (с помощью speller.yandex). Переводчик текста. Переворачивает текст случайно набранный на другой раскладке.
Полезная утилита для тех, кто печатает много однотипного текста, кодирует в среде Windows на разных языках программирования.
Через некоторое время работы с программой у вас соберется своя база часто используемых словосочетаний и кусков кода.
Настройка любых шорткатов под себя с помощью скриптов.
Никаких установок и лицензий, все бесплатно.
1 стартмани
Definition and Usage
The tag defines metadata about an
HTML document. Metadata is data (information) about data.
tags always go inside the <head> element,
and are typically used to specify character set, page description,
keywords, author of the document, and viewport settings.
Metadata will not be displayed on the page, but is machine parsable.
Metadata is used by browsers (how to display content or reload page),
search engines (keywords), and other web services.
There is a method to let web designers take control over the viewport
(the user’s visible area of a web page), through the tag (See «Setting
The Viewport» example below).
Это будет интересно новичкам
А теперь смотрите как все работает. Находите вы сайт и очень вам нравится какой-то элемент. Например, вот этот. Как открыть код элемента вы уже знаете.
Теперь копируете его.
Я пользуюсь , вставляю этот код в новый html файл, в тег body (тело по-английски).
Теперь посмотрим, как это все будет выглядеть в браузере.
Готово. Чтобы текст был выровнен по краям и приобрел зеленоватый цвет нужно подключить к этому документу css и скопировать еще один код с того сайта, с которого мы тырили этот.
Сейчас я не буду этим заниматься. На это нужно больше времени: и моего, и вашего. Думаю, что все подробности я опишу в своих будущих публикациях. Подписывайтесь на рассылку и узнаете о появлении статьи первым.
Если же терпеть нет сил, а узнать больше о html и css хочется уже сейчас, то могу по традиции порекомендовать вам бесплатные обучающие курсы.
Здесь 33 урока, которые позволят освоить html — «Бесплатный курс по HTML»
А тут полная информация о css — «Бесплатный курс по CSS (45 видеоуроков!)»
Теперь вы знаете чуть больше. Желаю вам успехов в ваших начинаниях. До новых встреч!
Ctrl + U
Как посмотреть исходный код элемента?
Нажмите правую кнопку мыши на интересующем элементе страницы.
Google Chrome : “Просмотр кода элемента”
Opera : “Проинспектировать элемент”
FireFox : “Анализировать элемент”
В других браузерах ищите подобный по смыслу пункт меню.
Всем привет!
Специально вначале статьи выложил всю суть, для тех, кто ищет быстрый ответ.
Информация может быть многим известна, но поскольку пишу для начинающих блоггеров, веб-программистов и прочих старателей, то эта справочная статья обязательно должна присутствовать.
В будущем вы обязательно будете изучать исходный код страниц и отдельных элементов.
Давайте посмотрим на конкретном примере как можно использовать просмотр исходного кода страницы.
Например, мы хотим посмотреть какие ключевые слова (keywords) используются для конкретной страницы. Заходим на интересующую нас веб-страницу и нажимаем Ctrl+U . В отдельном окне или в отдельной закладке откроется исходный код данной страницы. Нажимаем Ctrl+F для поиска фрагмента кода. В данном случае печатаем в окне поиска слово “keywords”.
Вас автоматически перебросит на фрагмент кода с этим мета-тегом и выделит искомое слово.
По аналогии можно искать и изучать другие фрагменты кода.
Просмотр всего исходного кода страницы в большинстве случаев не очень удобен, поэтому во всех браузерах существует возможность просмотреть код отдельного элемента или фрагмента.
Давайте применим на конкретном примере просмотр кода элемента. Например, посмотрим есть ли у ссылки атрибут nofollow . Нажимаем правой кнопкой мыши на интересующей нас ссылке и в выпадающем контекстном меню левой кнопкой кликаем по пункту “Просмотр кода элемента” или подобному (в зависимости от вашего браузера). Внизу, в специальном окне для анализа кода, получаем нечто подобное.
Мы видим, что в коде ссылки присутствует rel=”nofollow” . Это значит, что по этой ссылке не будет “утекать” и PR. Об этом подробней поговорим в следующих статьях
Сейчас же важно то, что вы теперь знаете как посмотреть исходный код страницы и исходный код отдельного элемента
Просматривая бесчисленное множество сайтов в интернете, можно встретить такие, которые очень нам нравятся. Сразу же возникает ряд вопросов. Сайт сделан с помощью самописного кода или какой-нибудь CMS? Какие у него CSS стили? Какие у него мета-теги? И так далее.
Существует много инструментов, с помощью которых можно извлечь информацию о коде страницы сайта. Но под рукой у нас всегда есть правая кнопка мыши. Её-то мы и будем использовать, на примере моего сайта.
Charset names
Charsets are named by strings composed of the following characters:
-
The uppercase letters 'A' through 'Z'
('\u0041' through '\u005a'), -
The lowercase letters 'a' through 'z'
('\u0061' through '\u007a'), -
The digits '0' through '9'
('\u0030' through '\u0039'), -
The dash character '-'
('\u002d', HYPHEN-MINUS), -
The plus character '+'
('\u002b', PLUS SIGN), -
The period character '.'
('\u002e', FULL STOP), -
The colon character ':'
('\u003a', COLON), and -
The underscore character '_'
('\u005f', LOW LINE).
RFC 2278: IANA Charset
Registration Procedures
Every charset has a canonical name and may also have one or more
aliases. The canonical name is returned by the method
of this class. Canonical names are, by convention, usually in upper case.
The aliases of a charset are returned by the
method.
Some charsets have an historical name that is defined for
compatibility with previous versions of the Java platform. A charset’s
historical name is either its canonical name or one of its aliases. The
historical name is returned by the getEncoding() methods of the
and classes.
If a charset listed in the IANA Charset
Registry is supported by an implementation of the Java platform then
its canonical name must be the name listed in the registry. Many charsets
are given more than one name in the registry, in which case the registry
identifies one of the names as MIME-preferred. If a charset has more
than one registry name then its canonical name must be the MIME-preferred
name and the other names in the registry must be valid aliases. If a
supported charset is not listed in the IANA registry then its canonical name
must begin with one of the strings "X-" or "x-".
The IANA charset registry does change over time, and so the canonical
name and the aliases of a particular charset may also change over time. To
ensure compatibility it is recommended that no alias ever be removed from a
charset, and that if the canonical name of a charset is changed then its
previous canonical name be made into an alias.
Syntax[edit]
The syntax of data URIs was defined in Request for Comments (RFC) 2397, published in August 1998, and follows the . A data URI consists of:
data:[<media type>][;base64],<data>
- The scheme, . It is followed by a colon ().
- An optional media type. If one is not specified, the media type of the data URI is assumed to be . It can contain an optional character set parameter, separated from the preceding part by a semicolon () . A character set parameter comprises the label , an equals sign (), and a value from the IANA list of official character set names. If this parameter is not present, the character set of the content is assumed to be (ASCII).
- The optional base64 extension , separated from the preceding part by a semicolon. When present, this indicates that the data content of the URI is binary data, encoded in ASCII format using the Base64 scheme for binary-to-text encoding. Data URIs encoded in Base64 may contain whitespace for human readability.
- The data, separated from the preceding part by a comma (). The data is a sequence of octets represented as characters. Permitted characters within a data URI are the ASCII characters for the lowercase and uppercase letters of the modern English alphabet, and the Arabic numerals. Octets represented by any other character must be percent-encoded, as in for an ampersand ().
Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Simple WMS Client – это визуальный конструктор мобильного клиента для терминала сбора данных(ТСД) или обычного телефона на Android. Приложение работает в онлайн режиме через интернет или WI-FI, постоянно общаясь с базой посредством http-запросов (вариант для 1С-клиента общается с 1С напрямую как обычный клиент). Можно создавать любые конфигурации мобильного клиента с помощью конструктора и обработчиков на языке 1С (НЕ мобильная платформа). Вся логика приложения и интеграции содержится в обработчиках на стороне 1С. Это очень простой способ создать и развернуть клиентскую часть для WMS системы или для любой другой конфигурации 1С (УТ, УПП, ERP, самописной) с минимумом программирования. Например, можно добавить в учетную систему адресное хранение, учет оборудования и любые другие задачи. Приложение умеет работать не только со штрих-кодами, но и с распознаванием голоса от Google. Это бесплатная и открытая система, не требующая обучения, с возможностью быстро получить результат.
5 стартмани
Тег
Тег <title> является частью метаданных и используется для указания заголовка страницы. Заголовок страницы можно сравнить с названием главы книги, так как он должен говорить пользователям и поисковым системам об информации представленной на странице.
Заголовок должен содержать важные ключевые слова для того, чтобы поисковые системы могли включить вашу страницу в результаты поиска по определенным запросам. Также он может помочь пользователям решить, стоит ли посетить ваш сайт или нет, так как они будут видеть заголовок в качестве текста ссылки в результатах поиска:
Тег <title> является одним из наиболее важных тегов на странице. Рассмотрим небольшой список рекомендаций, которых нужно придерживаться для написания оптимизированного заголовка для поисковых систем:
- Длина заголовка не должна превышать 70 символов, включая пробелы.
- Самые важные ключевые слова нужно располагать первыми в заголовке, т.е. поисковые системы будут определять ценность ключевых слов по их очередности в заголовке: первое будет считаться наиболее важным, последнее — наименее.
- Для разделения ключевых слов или фраз лучше использовать вертикальную черту «|». Знаки пунктуации, подчеркивания и другие символы разделители желательно не использовать или использовать в тех случаях, когда ключевое слово или фразу без них написать нельзя.
- Старайтесь исключить из заголовка разные частицы речи (например: и, если, но, потом и т.д.).
- Можно включить в заголовок название сайта или фирмы, если название является частью ключей фразы, или если это бренд, видя который, пользователи будут заходить именно на ваш сайт.
- Не дублируйте текст тега <title>, заголовок должен быть уникальным для каждой страницы сайта.
- Заголовок должен быть актуален для страницы, он должен описывать то, что в данный момент представлено на странице, например его можно написать так:
<title>Тема страницы|Ключевые слова|Название компании или сайта</title> <!-- или так --> <title>Ключевые слова|О нас|Название компании или сайта</title>
Преобразование строки в массив байтов
Иногда нам нужно преобразовать Строку в байт[] . Самый простой способ сделать это-использовать метод String getBytes() :
String originalInput = "test input"; byte[] result = originalInput.getBytes(); assertEquals(originalInput.length(), result.length);
String originalInput = "test input"; byte[] result = originalInput.getBytes(StandardCharsets.UTF_16); assertTrue(originalInput.length() < result.length);
Если наша строка Base64 закодирована, мы можем использовать декодер Base64 |:
String originalInput = "dGVzdCBpbnB1dA==";
byte[] result = Base64.getDecoder().decode(originalInput);
assertEquals("test input", new String(result));
Мы также можем использовать DatatypeConverter parseBase64Binary() метод :
String originalInput = "dGVzdCBpbnB1dA==";
byte[] result = DatatypeConverter.parseBase64Binary(originalInput);
assertEquals("test input", new String(result));
Наконец, мы можем преобразовать шестнадцатеричную строку в байт[] с помощью метода DatatypeConverter :
String originalInput = "7465737420696E707574";
byte[] result = DatatypeConverter.parseHexBinary(originalInput);
assertEquals("test input", new String(result));
Модуль ngx_http_charset_module
Модуль добавляет указанную
кодировку в поле “Content-Type” заголовка ответа.
Кроме того, модуль может перекодировать данные из одной кодировки в другую
с некоторыми ограничениями:
- перекодирование осуществляется только в одну сторону — от сервера к клиенту,
- перекодироваться могут только однобайтные кодировки
- или однобайтные кодировки в UTF-8 и обратно.
| Синтаксис: | |
|---|---|
| Умолчание: |
charset off; |
| Контекст: | , , , |
Добавляет указанную кодировку в поле “Content-Type”
заголовка ответа.
Если эта кодировка отличается от указанной в директиве
, то выполняется перекодирование.
Параметр отменяет добавление кодировки
в поле “Content-Type” заголовка ответа.
Кодировка может быть задана с помощью переменной:
В этом случае необходимо, чтобы все возможные значения переменной
присутствовали хотя бы один раз в любом месте конфигурации в виде
директив , или
.
Для кодировок ,
и для этого достаточно включить в конфигурацию
файлы , и
.
Для других кодировок можно просто сделать фиктивную таблицу перекодировки,
например:
Кроме того, кодировка может быть задана в поле “X-Accel-Charset”
заголовка ответа.
Эту возможность можно запретить с помощью директив
,
,
,
и
.
| Синтаксис: | |
|---|---|
| Умолчание: |
— |
| Контекст: |
Описывает таблицу перекодирования из одной кодировки в другую.
Таблица для обратного перекодирования строится на основании тех же данных.
Коды символов задаются в шестнадцатеричном виде.
Неописанные символы в пределах 80-FF заменяются на “”.
При перекодировании из UTF-8 символы, отсутствующие в однобайтной кодировке,
заменяются на “”.
Пример:
При описании таблицы перекодирования в UTF-8, коды кодировки UTF-8 должны
быть указаны во второй колонке, например:
Полные таблицы преобразования из в
и из и
в
входят в дистрибутив и находятся в файлах ,
и .
| Синтаксис: | |
|---|---|
| Умолчание: |
charset_types text/html text/xml text/plain text/vnd.wap.wml application/javascript application/rss+xml; |
| Контекст: | , , |
Эта директива появилась в версии 0.7.9.
Разрешает работу модуля в ответах с указанными MIME-типами
в дополнение к “”.
Специальное значение “” соответствует любому MIME-типу
(0.8.29).
| Синтаксис: | |
|---|---|
| Умолчание: |
override_charset off; |
| Контекст: | , , , |
Определяет, выполнять ли перекодирование для ответов,
полученных от проксированного сервера или от FastCGI/uwsgi/SCGI/gRPC-сервера,
если в ответах уже указана кодировка в поле “Content-Type”
заголовка ответа.
Если перекодирование разрешено, то в качестве исходной кодировки
используется кодировка, указанная в полученном ответе.
| Синтаксис: | |
|---|---|
| Умолчание: |
— |
| Контекст: | , , , |
Задаёт исходную кодировку ответа.
Если эта кодировка отличается от указанной в директиве
, то выполняется перекодирование.
Что такое кодировка
Кодировка – специальный метод, позволяющий отображать текст на экране таким образом, чтобы он был понятен каждому пользователю. Все символы, которые мы видим в интернете, – это буквы и цифры только для нас, компьютер их не понимает. Он воспринимает информацию в байтах, весь текст на экране монитора – это совокупность байтов. У каждого символа есть свое кодовое значение, которое компьютер использует при выводе слов и чисел на экран.
Вот наглядный пример того, как воспринимается компьютером латинский алфавит и прочие символы:
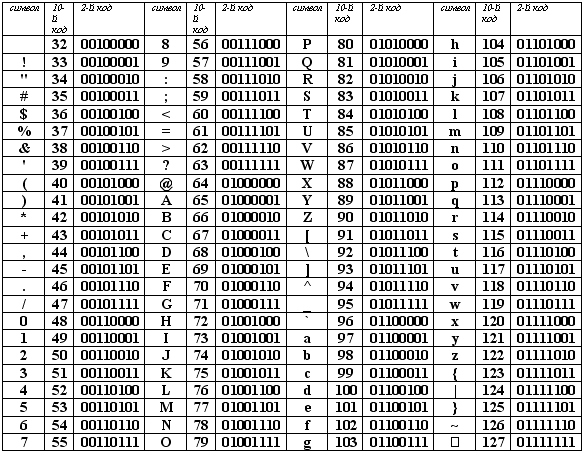
Если никакая кодировка не установлена, вместо символов мы увидим такие значения. Чтобы понять компьютер, необходимо установить нужную кодировку для расшифровки символов из этой таблицы.
Понимание Схем Кодирования
Кодировка символов может принимать различные формы в зависимости от количества символов, которые она кодирует.
Количество закодированных символов имеет прямое отношение к длине каждого представления, которое обычно измеряется как количество байтов. Наличие большего количества символов для кодирования по существу означает необходимость более длинных двоичных представлений.
Давайте рассмотрим некоторые из популярных схем кодирования на практике сегодня.
4.1. Однобайтовое кодирование
Одна из самых ранних схем кодирования, называемая ASCII (Американский стандартный код для обмена информацией), использует однобайтовую схему кодирования. По сути, это означает, что каждый символ в ASCII представлен семибитными двоичными числами. Это все еще оставляет один бит свободным в каждом байте!
Ascii 128-символьный набор охватывает английские алфавиты в нижнем и верхнем регистрах, цифры и некоторые специальные и контрольные символы.
Давайте определим простой метод в Java для отображения двоичного представления символа в определенной схеме кодирования:
String convertToBinary(String input, String encoding)
throws UnsupportedEncodingException {
byte[] encoded_input = Charset.forName(encoding)
.encode(input)
.array();
return IntStream.range(0, encoded_input.length)
.map(i -> encoded_input)
.mapToObj(e -> Integer.toBinaryString(e ^ 255))
.map(e -> String.format("%1$" + Byte.SIZE + "s", e).replace(" ", "0"))
.collect(Collectors.joining(" "));
}
Теперь символ ” T ” имеет кодовую точку 84 в US-ASCII (ASCII в Java называется US-ASCII).
И если мы используем наш метод утилиты, мы можем увидеть его двоичное представление:
assertEquals(convertToBinary("T", "US-ASCII"), "01010100");
Это, как мы и ожидали, семиразрядное двоичное представление символа “T”.
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. В то же время ASCII оставил довольно много непредставленных символов,
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. || В то же время ASCII оставил довольно много непредставленных символов,
Было предложено и принято несколько вариантов схемы кодирования ASCII.
Многие расширения ASCII имели разные уровни успеха, но, очевидно, это
Одним из наиболее популярных расширений ASCII был ISO-8859-1 , также называемый “ISO Latin 1”.
4.2. Многобайтовое кодирование
Поскольку потребность в размещении все большего количества символов росла, однобайтовые схемы кодирования, такие как ASCII, не были устойчивыми.
Это привело к появлению многобайтовых схем кодирования, которые имеют гораздо большую емкость, хотя и за счет увеличения требований к пространству.
BIG 5 и SHIFT-JIS являются примерами многобайтовых схем кодирования символов, которые начали использовать как один, так и два байта для представления более широких наборов символов . Большинство из них были созданы для того, чтобы представлять китайские и аналогичные сценарии, которые имеют значительно большее количество символов.
Давайте теперь вызовем метод convertToBinary с вводом как “語”, китайский символ, и кодирование как “Big5”:
assertEquals(convertToBinary("語", "Big5"), "10111011 01111001");
Вывод выше показывает, что кодировка Big5 использует два байта для представления символа “語”.
полный список кодировок символов, наряду с их псевдонимами, ведется Международным органом по номерам.
Скалярные значения Юникода
Термин относится ко всем кодовым точкам, кроме суррогатных. Другими словами, скалярное значение — это любая кодовая точка, которой присвоен символ или которой может быть присвоен символ в будущем. Слово «символ» здесь относится ко всему, что может быть назначено кодовой точке, включая действия, которые определяют способ отображения текста или символов.
На приведенной ниже схеме показаны точки кода скалярного значения.
Тип Rune как скалярное значение
Начиная с версии .NET Core 3.0, тип System.Text.Rune представляет скалярное значение Юникода. Тип недоступен в .NET Core 2.x или .NET Framework 4.x.
Конструкторы проверяют, является ли полученный экземпляр допустимым скалярным значением Юникода. В противном случае они создают исключение. В следующем примере показан код, который создает экземпляры , так как входные данные представляют допустимые скалярные значения:
В следующем примере создается исключение, так как кодовая точка находится в суррогатном диапазоне и не является частью суррогатной пары:
В следующем примере создается исключение, так как кодовая точка находится за пределами дополнительного диапазона:
Пример использования Rune: изменение регистра букв
API, который принимает и предполагает, что работает с кодовой точкой, которая является скалярным значением, работает неправильно, если принадлежит суррогатной паре. Например, рассмотрим следующий метод, который вызывает Char.ToUpperInvariant для каждого экземпляра char в string:
Если string содержит строчную букву дезерет (), этот код не преобразует ее в прописную букву (). Код вызывает отдельно для каждой суррогатной кодовой точки и . Однако в самой кодовой точке информации недостаточно, чтобы идентифицировать ее как строчную букву. Таким образом оставляет ее как есть. И таким же образом обрабатывает . В результате буква «𐑉» нижнего регистра в string не преобразуется в букву «𐐡» верхнего регистра.
Вот два варианта правильного преобразования string в верхний регистр:
-
Вызовите String.ToUpperInvariant для входного экземпляра string, а не в итерации -by-. Метод имеет доступ к обеим частям каждой суррогатной пары, поэтому он может правильно обрабатывать все кодовые точки Юникода.
-
Выполните итерацию скалярных значений Юникода в качестве экземпляров , а не экземпляров , как показано в следующем примере. Так как экземпляр является допустимым скалярным значением Юникода, его можно передать в API-интерфейсы, которые должны работать со скалярным значением. Например, вызвав Rune.ToUpperInvariant, как показано в следующем примере, вы получите правильные результаты:
Другие API-интерфейсы Rune
Тип предоставляет аналоги многих API-интерфейсов . Например, приведенные ниже методы отражают статические API-интерфейсы для типа :
- Rune.IsLetter
- Rune.IsWhiteSpace
- Rune.IsLetterOrDigit
- Rune.GetUnicodeCategory
Чтобы получить необработанное скалярное значение из экземпляра , используйте свойство Rune.Value.
Чтобы преобразовать экземпляр обратно в последовательность типов , используйте метод Rune.ToString или Rune.EncodeToUtf16.
Так как любое скалярное значение Юникода может быть представлено одним экземпляром или суррогатной парой, любой экземпляр может быть представлен не более чем двумя экземплярами . Используйте Rune.Utf16SequenceLength, чтобы узнать количество экземпляров , требуемых для представления экземпляра .
Дополнительные сведения о типе .NET см. в справочнике по API для .
Расшифровка мира кодировки UTF-8
Это было много слов о словах, поэтому давайте резюмируем то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, как двоичные (единицы и нули).
- ASCII был ранним способом кодирования или отображения символов в двоичный код, чтобы компьютеры могли их хранить. Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
- Юникод был решением этой проблемы. Юникод присваивает уникальный «код» каждому символу на каждом человеческом языке.
- UTF-8 – это метод кодировки символов Unicode. Это означает, что UTF-8 берет кодовую точку для данного символа Юникода и переводит ее в строку двоичного кода. Он также делает обратное, считывая двоичные цифры и преобразуя их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любой символ.
- UTF-16 – еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых неанглийских языках).
Перевод Unicode – это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и именно в этом суть – создать бесшовную систему обработки текста, которая работает для всех языков и веб-браузеров. Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают чрезмерно много места или если ваш текст завален буквами and и, пора применить ваши новые знания о UTF-8.
Источник записи: https://blog.hubspot.com
HTML Tags
<!—><!DOCTYPE><a><abbr><acronym><address><applet><area><article><aside><audio><b><base><basefont><bdi><bdo><big><blockquote><body><br><button><canvas><caption><center><cite><code><col><colgroup><data><datalist><dd><del><details><dfn><dialog><dir><div><dl><dt><em><embed><fieldset><figcaption><figure><font><footer><form><frame><frameset><h1> — <h6><head><header><hr><html><i><iframe><img><input><ins><kbd><label><legend><li><link><main><map><mark><meta><meter><nav><noframes><noscript><object><ol><optgroup><option><output><p><param><picture><pre><progress><q><rp><rt><ruby><s><samp><script><section><select><small><source><span><strike><strong><style><sub><summary><sup><svg><table><tbody><td><template><textarea><tfoot><th><thead><time><title><tr><track><tt><u><ul><var><video>
Другие Места, Где Кодирование Важно
Нам не просто нужно учитывать кодировку символов при программировании. Тексты могут окончательно испортиться во многих других местах.
наиболее распространенной причиной проблем в этих случаях является преобразование текста из одной схемы кодирования в другую , что может привести к потере данных.
Давайте быстро рассмотрим несколько мест, где мы можем столкнуться с проблемами при кодировании или декодировании текста.
7.1. Текстовые Редакторы
В большинстве случаев текстовый редактор-это место, откуда исходят тексты. Существует множество текстовых редакторов в популярном выборе, включая vi, Блокнот и MS Word. Большинство из этих текстовых редакторов позволяют нам выбрать схему кодирования. Следовательно, мы всегда должны быть уверены, что они подходят для текста, с которым мы работаем.
7.2. Файловая система
После того, как мы создадим тексты в редакторе, нам нужно сохранить их в какой-то файловой системе. Файловая система зависит от операционной системы, на которой она работает. Большинство операционных систем имеют встроенную поддержку нескольких схем кодирования. Однако все еще могут быть случаи, когда преобразование кодировки приводит к потере данных.
7.3. Сеть
Тексты, передаваемые по сети с использованием протокола, такого как протокол передачи файлов (FTP), также включают преобразование между кодировками символов. Для всего, что закодировано в Юникоде, безопаснее всего передавать в двоичном виде, чтобы свести к минимуму риск потери при преобразовании. Однако передача текста по сети является одной из менее частых причин повреждения данных.
7.4. Базы данных
Большинство популярных баз данных, таких как Oracle и MySQL, поддерживают выбор схемы кодирования символов при установке или создании баз данных. Мы должны выбрать это в соответствии с текстами, которые мы ожидаем сохранить в базе данных. Это одно из наиболее частых мест, где повреждение текстовых данных происходит из-за преобразования кодировки.
7.5. Браузеры
Наконец, в большинстве веб-приложений мы создаем тексты и пропускаем их через различные слои с намерением просмотреть их в пользовательском интерфейсе, например в браузере
Здесь также важно, чтобы мы выбрали правильную кодировку символов, которая может правильно отображать символы. Большинство популярных браузеров, таких как Chrome, Edge, позволяют выбирать кодировку символов в своих настройках
Java 8 для базы 64
Java 8 наконец-то добавила возможности Base64 в стандартный API. Это делается через класс утилиты java.util.Base64 .
Давайте начнем с рассмотрения базового процесса кодирования.
2.1. Java 8 Basic Base64
Базовый кодер упрощает работу и кодирует вход как есть, без какого-либо разделения строк.
Выходные данные отображаются на набор символов в A-Za-z0-9+/ набор символов, и декодер отклоняет любой символ за пределами этого набора.
Давайте сначала закодируем простую строку :
String originalInput = "test input"; String encodedString = Base64.getEncoder().encodeToString(originalInput.getBytes());
Обратите внимание, как мы получаем полный API кодировщика с помощью простого метода GetEncoder() utility. Теперь давайте расшифруем эту строку обратно в исходную форму:
Теперь давайте расшифруем эту строку обратно в исходную форму:
byte[] decodedBytes = Base64.getDecoder().decode(encodedString); String decodedString = new String(decodedBytes);
2.2. Кодировка Java 8 Base64 Без Заполнения
В кодировке Base64 длина выходной кодированной строки должна быть кратна трем. Если нет, то вывод будет дополнен дополнительными символами pad ( = ).
После декодирования эти дополнительные символы заполнения будут отброшены. Чтобы углубиться в заполнение в Base64, ознакомьтесь с этим подробным ответом на Переполнение стека .
Если нам нужно пропустить заполнение вывода — возможно, потому, что результирующая строка никогда не будет декодирована обратно — мы можем просто выбрать кодирование без заполнения :
String encodedString = Base64.getEncoder().withoutPadding().encodeToString(originalInput.getBytes());
2.3. Кодировка URL-адресов Java 8
Кодировка URL-адресов очень похожа на базовый кодер, который мы рассмотрели выше. Он использует безопасный алфавит Base64 URL и имени файла и не добавляет никакого разделения строк:
String originalUrl = "https://www.google.co.nz/?gfe_rd=cr&ei=dzbFV&gws_rd=ssl#q=java"; String encodedUrl = Base64.getUrlEncoder().encodeToString(originalURL.getBytes());
Декодирование происходит во многом таким же образом. Метод утилиты getUrlDecoder() возвращает java.util.Base64.Decoder , который затем используется для декодирования URL-адреса:
byte[] decodedBytes = Base64.getUrlDecoder().decode(encodedUrl); String decodedUrl = new String(decodedBytes);
2.4. Кодировка MIME Java 8
Давайте начнем с создания некоторого базового ввода MIME для кодирования:
private static StringBuilder getMimeBuffer() {
StringBuilder buffer = new StringBuilder();
for (int count = 0; count < 10; ++count) {
buffer.append(UUID.randomUUID().toString());
}
return buffer;
}
Кодер MIME генерирует выходные данные в кодировке Base64, используя базовый алфавит, но в удобном для MIME формате.
Каждая строка вывода содержит не более 76 символов и заканчивается возвратом каретки, за которым следует перевод строки ( \r\n ):
StringBuilder buffer = getMimeBuffer(); byte[] encodedAsBytes = buffer.toString().getBytes(); String encodedMime = Base64.getMimeEncoder().encodeToString(encodedAsBytes);
Метод утилиты getMimeDecoder() возвращает java.util.Base64.Decoder , который затем используется в процессе декодирования:
byte[] decodedBytes = Base64.getMimeDecoder().decode(encodedMime); String decodedMime = new String(decodedBytes);
Is it a ranking factor for SEO?
The character set is not a ranking factor for search engine optimization. Most search engines focus on the important goal of delivering relevant, useful content to those who seek it and as such does not consider other outside factors that do not contribute to that goal.
So your character set matters because of how you transmit information but search engines are not interested in it. Using other charsets apart from Utf-8 will not decrease your SEO ranking because to a large extent it doesn’t matter what character encoding you use as long as the search engine is able to get information to the end users.