Как выбрать кодировку и исправить все проблемы с ней
Содержание:
- Таблицы[править]
- Принудительная смена
- Скалярные значения Юникода
- Кодировки в windows / песочница / хабр
- Довідка
- Типы кодировок
- Сайты для перекодировки онлайн
- Смена кодировки прямо в браузере
- Пользуемся стандартным Word
- Кодирование текстовой информации и компьютеры
- Решения проблемы с кодировкой в CMD. 1 Способ.
- Случаи некорректного отображения текста
- Сохранение файлов в другой кодировке
- Общие сведения о кодировке текста
- Кодировки на основе Unicode
- Что представляет собой кодировка и от чего она зависит?
Таблицы[править]
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251 (синоним CP1251)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Њ40A | Ќ40C | Ћ40B | Џ40F |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | њ45A | ќ45C | ћ45B | џ45F | |
| A. | A0 | Ў40E | ў45E | Ј408 | ¤A4 | Ґ490 | ¦A6 | §A7 | Ё401 | A9 | Є404 | AB | ¬AC | AD | AE | Ї407 |
| B. | °B0 | ±B1 | І406 | і456 | ґ491 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | є454 | BB | ј458 | Ѕ405 | ѕ455 | ї457 |
| C. | А410 | Б411 | В412 | Г413 | Д414 | Е415 | Ж416 | З417 | И418 | Й419 | К41A | Л41B | М41C | Н41D | О41E | П41F |
| D. | Р420 | С421 | Т422 | У423 | Ф424 | Х425 | Ц426 | Ч427 | Ш428 | Щ429 | Ъ42A | Ы42B | Ь42C | Э42D | Ю42E | Я42F |
| E. | а430 | б431 | в432 | г433 | д434 | е435 | ж436 | з437 | и438 | й439 | к43A | л43B | м43C | н43D | о43E | п43F |
| F. | р440 | с441 | т442 | у443 | ф444 | х445 | ц446 | ч447 | ш448 | щ449 | ъ44A | ы44B | ь44C | э44D | ю44E | я44F |
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| A. | A0 | ¡A1 | ¢A2 | £A3 | €20AC | ¥A5 | ¦A6 | §A7 | Ё401 | A9 | №2116 | AB | ¬AC | AD | AE | ¯AF |
| B. | °B0 | ±B1 | ²B2 | ³B3 | ´B4 | µB5 | ¶B6 | ·B7 | ё451 | ¹B9 | ºBA | BB | ¼BC | ½BD | ¾BE | ¿BF |
Кодировка CP1251-k (KazWin, казахская кодировка)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ұ4B0 | Ғ492 | ‚201A | ғ493 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Ө4E8 | ‹2039 | Ң4A2 | Қ49A | Һ4BA | Ү4AE |
| 9. | ұ4B1 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | ө4E9 | ›203A | ң4A3 | қ49B | һ4BB | ү4AF | |
| A. | A0 | Ў40E | ў45E | Җ496 | ¤A4 | Ҳ4B2 | ¦A6 | §A7 | Ё401 | A9 | Є404 | AB | ¬AC | AD | AE | Ї407 |
| B. | °B0 | ±B1 | І406 | і456 | ҳ4B3 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | є454 | BB | җ497 | Ә4D8 | ә4D9 | ї457 |
Кодировка Windows-1251 (чувашский вариант)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Ӑ4D0 | Ӗ4D6 | Ҫ4AA | Ӳ4F2 |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | ӑ4D1 | ӗ4D7 | ҫ4AB | ӳ4F3 |
Татарский вариантправить
Эта кодировка была официально принята в Татарстане в г.
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ә4D8 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Ө4E8 | ‹2039 | Ү4AE | Җ496 | Ң4A2 | Һ4BA |
| 9. | ә4D9 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | ө4E9 | ›203A | ү4AF | җ497 | ң4A3 | һ4BB |
Принудительная смена
Если вы получили из какого-то источника текстовый файл, но не можете прочитать его содержимое, то нужна операция ручной смены кодировки. Для этого зайдите в раздел «Сведения» во вкладке «Файл». Тут собраны глобальные настройки распознавания и отображения, и если вы будете изменять их в открытом документе, то для него они станут индивидуальными, а для остальных — не изменятся. Воспользуемся этим. В разделе «Дополнительно» появившегося окна находим заголовок «Общие» и ставим галочку «Подтверждать преобразование файлов при открытии». Подтвердите изменения и закройте Word. Теперь откройте документ снова, как бы применяя настройки, и перед вами появится окно преобразования файла. В нём будет список возможных форматов, среди которых находим «Кодированный текст», и получим следующий диалог.

В этом новом окне будет три переключателя. Первый, по умолчанию, — это CP-1251, кодировка Windows. Второй — MS-DOS. Нам нужен третий пункт — ручной выбор, справа от него перечислены разнообразные наборы символов. Но, как правило, пользователь не знает, какими символами был набран текст предыдущим автором, поэтому в нижней части этого окна есть поле под названием «Образец», в котором фрагмент из текста будет в реальном времени отображаться при выборе того или иного комплекта символов. Это очень удобно, потому что не нужно каждый раз закрывать и отрывать документ снова, чтобы подобрать нужную.

Перебирая варианты по одному и глядя на текст в поле образцов, выберите ту кодировку, при которой символы будут русскими
Но обратите внимание, что это ещё ничего не значит, — внимательно смотрите, чтобы они складывались в осмысленные слова. Дело в том, что для русского языка есть не одна кодировка, и текст в одной из них не будет отображаться корректно в другой
Так что будьте внимательны.
Нужно сказать, что с файлами, сделанными на современных текстовых процессорах, крайне редко возникают подобные проблемы. Однако есть ещё и такой бич современного информационного общества, как несовместимость форматов. Дело в том, что существует целый ряд текстовых редакторов, и каждым кто-то пользуется. Возможно, для кого-то не нужна функциональность Ворда, кто-то не считает нужным за него платить и т. п. Причин может быть множество.
Если при сохранении документа автор выбрал формат, совместимый в MS Word, то проблем возникнуть не должно. Но так бывает нечасто. Например, если текст сохранён с расширением.rtf, то диалог выбора кодировки отобразится перед вами сразу же при открытии текста. А вот форматы другого популярного текстового процессора OpenOffice Ворд даже не откроет, поэтому, если им пользуетесь, не забывайте выбирать пункт «Сохранить как», когда отправляете файл пользователю Office.
Скалярные значения Юникода
Термин относится ко всем кодовым точкам, кроме суррогатных. Другими словами, скалярное значение — это любая кодовая точка, которой присвоен символ или которой может быть присвоен символ в будущем. Слово «символ» здесь относится ко всему, что может быть назначено кодовой точке, включая действия, которые определяют способ отображения текста или символов.
На приведенной ниже схеме показаны точки кода скалярного значения.
Тип Rune как скалярное значение
Начиная с версии .NET Core 3.0, тип System.Text.Rune представляет скалярное значение Юникода. Тип недоступен в .NET Core 2.x или .NET Framework 4.x.
Конструкторы проверяют, является ли полученный экземпляр допустимым скалярным значением Юникода. В противном случае они создают исключение. В следующем примере показан код, который создает экземпляры , так как входные данные представляют допустимые скалярные значения:
В следующем примере создается исключение, так как кодовая точка находится в суррогатном диапазоне и не является частью суррогатной пары:
В следующем примере создается исключение, так как кодовая точка находится за пределами дополнительного диапазона:
Пример использования Rune: изменение регистра букв
API, который принимает и предполагает, что работает с кодовой точкой, которая является скалярным значением, работает неправильно, если принадлежит суррогатной паре. Например, рассмотрим следующий метод, который вызывает Char.ToUpperInvariant для каждого экземпляра char в string:
Если string содержит строчную букву дезерет (), этот код не преобразует ее в прописную букву (). Код вызывает отдельно для каждой суррогатной кодовой точки и . Однако в самой кодовой точке информации недостаточно, чтобы идентифицировать ее как строчную букву. Таким образом оставляет ее как есть. И таким же образом обрабатывает . В результате буква «𐑉» нижнего регистра в string не преобразуется в букву «𐐡» верхнего регистра.
Вот два варианта правильного преобразования string в верхний регистр:
-
Вызовите String.ToUpperInvariant для входного экземпляра string, а не в итерации -by-. Метод имеет доступ к обеим частям каждой суррогатной пары, поэтому он может правильно обрабатывать все кодовые точки Юникода.
-
Выполните итерацию скалярных значений Юникода в качестве экземпляров , а не экземпляров , как показано в следующем примере. Так как экземпляр является допустимым скалярным значением Юникода, его можно передать в API-интерфейсы, которые должны работать со скалярным значением. Например, вызвав Rune.ToUpperInvariant, как показано в следующем примере, вы получите правильные результаты:
Другие API-интерфейсы Rune
Тип предоставляет аналоги многих API-интерфейсов . Например, приведенные ниже методы отражают статические API-интерфейсы для типа :
- Rune.IsLetter
- Rune.IsWhiteSpace
- Rune.IsLetterOrDigit
- Rune.GetUnicodeCategory
Чтобы получить необработанное скалярное значение из экземпляра , используйте свойство Rune.Value.
Чтобы преобразовать экземпляр обратно в последовательность типов , используйте метод Rune.ToString или Rune.EncodeToUtf16.
Так как любое скалярное значение Юникода может быть представлено одним экземпляром или суррогатной парой, любой экземпляр может быть представлен не более чем двумя экземплярами . Используйте Rune.Utf16SequenceLength, чтобы узнать количество экземпляров , требуемых для представления экземпляра .
Дополнительные сведения о типе .NET см. в справочнике по API для .
Кодировки в windows / песочница / хабр
В данной статье пойдёт речь о кодировках в Windows. Все в жизни хоть раз использовали и писали консольные приложения как таковые. Нету разницы для какой причины. Будь-то выбивание процесса или же просто написать «Привет!!! Я не могу сделать кодировку нормальной, поэтому я смотрю эту статью!».
Тем, кто ещё не понимает, о чём проблема, то вот Вам:
А тут было написано:
Но никто ничего не понял.
В любом случае в Windows до 10 кодировка BAT и других языков, не использует кодировку поддерживающую Ваш язык, поэтому все русские символы будут писаться неправильно.
1. Настройка консоли в батнике
Сразу для тех, кто пишет chcp 1251 лучше написать это:
Первый способ устранения проблемы, это
Notepad
. Для этого Вам нужно открыть Ваш батник таким способом:
Не бойтесь, у Вас откроется код Вашего батника, а затем Вам нужно будет сделать следующие действия:
Если Вам ничего не помогло, то преобразуйте в UTF-8 без BOM.
2. Написание консольных программНередко люди пишут консольные программы(потому что на некоторых десктопные писать невозможно), а кодировка частая проблема.
Первый способ непосредственно Notepad , но а если нужно сначала одну кодировку, а потом другую?
Сразу для использующих chcp 1251 пишите это:
Второй способ это написать десктопную программу, или же использовать Visual Studio. Если же не помогает, то есть первое: изменение кодировки вывода(Пример на C ).
Если же не сработает:
3. Изменение chcp 1251
Если же у Вас батник, то напишите в начало:
Теперь у Нас будет нормальный вывод в консоль. На других языках (С ):
4. Сделать жизнь мёдом
При использовании данного способа Вы не сможете:
- Разрабатывать приложения на Windows ниже 10
- Спасти мир от данной проблемы
- Думать о других людях
- Разрабатывать десктопные приложения, так как Вам жизнь покажется мёдом
- Сменить Windows на версию ниже 10
- Ну и понимать людей, у которых Windows ниже 10
Установить Windows 10. Там кодировка консоли специально подходит для языка страны, и Вам больше не нужно будет беспокоиться об этой проблеме. Но у Вас появится ещё 6 проблем, и вернуться к предыдущей лицензионной версии Windows Вы не сможете.
Довідка
Як користуватися програмою
- Скопіюйте текст для розкодування у велике поле для тексту. Програма спробуе розшифрувати перших кілька слів, тому вони мусять бути текстом в кирилиці (не латинка, не дата і не число).
- Зі списку «Виберіть найкращий зразок» виберіть пункт, що найближче подібний до вашого тексту. Варіанти у списку — це найчастіше вживані не правильні кодування.
- Якщо жоден із запропонованих варіантів вам не підійшов, то натисніть кнопку «Перевірити всі можливі комбінації».
- Програма спробує прочитати ваш текст і покаже результат нижче.
- Якщо текст вдалося розкодувати, ви побачите результат в Кирилиці і зможете його скопіювати щоб зберегти.
- Якщо текст не вдалося правильно розкодувати (результат не в Кирилиці, а й надалі написаний незрозумілими символами), ви можете вибрати у ново-створеному списку варіант в кирилиці (виберіть найдовший, якщо їх кілька) і натисніть кнопку ОК, текст буде показано у правильному кодуванні.
- Якщо текст розкодовано не повністю, то спробуйте вибрати інші варіанти написані Кирилицею зі списку.
Обмеження
- Якщо ваш текст містить одні лише знаки запитання «???? ?? ??????», то проблема виникла під час пересилання і розкодувати такий текст неможливо. Попрохайте відправника послати вам текст ще раз, найкраще у вигляді звичайного текстового файлу.
- Автор не береться стверджувати, що його програма може правильно перекодувати будь-який текст, навіть якщо ви певні, що текст був в Кирилиці. Але програма докладе максимальних зусиль.
- Розмір тексту, що може бути проаналізованим та перекодованим, не повинен перевищувати 100 кілобайтів.
- Іноді не можливо досягнути 100% точності перекодування при перетворенні тексту з однієї кодової сторінки о іншої, деякі символи можуть бути втрачені, наприклад Болгарські лапки, чи інші літери. Частково це може бути спричинено не правильною роботою Windows Clipboard’у.
-
Програма спробує підібрати аж до 7245 варіантів дво- чи три- рівневого перекодування: у випадку, коли текст пройшов через більше ніж три зміни кодової сторінки, наприклад koi8(utf(cp1251(utf))), він не зможе бути правильно перекодованим. Зазвичай, кількість можливих та показаних правильних варіантів складає від 32 до 255.
- Якщо частина тексту закодована однією кодовою таблицею, а інша частина іншою, то програма зможе правильно розкодувати лише одну частину. Спробуйте розділити такий текст відповідно до кількості частин з різними кодуваннями і обробляйте їх послідовно.
Умови використання
Увага. Ця безкоштовна програма створена з надією бути корисною, але автор не датє жодних гарантій, прямих чи не прямих, що програма взагалі буде працювати. Будь-ласка, користуйтеся нею на власний розсуд.
Якщо ви хочете розкодувати дуже довгий чи важливий текст, зробіть спочатку копію, щоб не було прикро через його випадкову втрату.
Перекладачі
Подяка за переклад на різні мови належиться:
- Українська (Ukrainian): Тарас Багнюк (barmalini)(http://barmalini.blogspot.com)
- Русский (Russian) : chAlx, Petr Vasilyev (http://yonyonson.livejournal.com/)
- Slovensky (Slovak) : Martin (KPR Slovakia)
-
O’zbek (Uzbek) : Abdulla
Other translations are in preparation at this page.
Типы кодировок
Существует несколько типов кодировок:
- ASCII – первая кодировка, которая была признана Американским национальным институтом мировых стандартов. Для ее использования задействуется 7 бит, где первые 128 значений включают в себя весь английский алфавит, числа, знаки и символы. Такая кодировка ранее использовалась на англоязычных ресурсах.
- Кириллица – вариант российской кодировки, используемый на русскоязычных сайтах и блогах.
- КОИ8 (код обмена информацией 8-битный) – была разработана для кодирования букв кириллических алфавитов. Распространена в Unix-подобных ОС и электронной почте. Постепенно исчезает в связи с приходом Юникода.
- Windows 1250-1258 – 8-битные кодировки, зародившиеся после появления операционной системы Windows. Например, 1250 – все языки центральной Европы, 1251 – кириллица. В ней присутствуют все буквы русского алфавита, а также символы (за исключением знака ударения).
- UTF-8 – наиболее используемый тип кодировок, работающий практически со всеми языками мира. Символы занимают от 1 до 4 байт, что дает возможность создавать мультиязычные веб-сайты. Помимо UTF-8, есть такие варианты, как UTF-16 и UTF-32, однако предпочтение отдается первому типу.
Существуют и другие типы кодировок, но они используются в меньшей степени либо не используются вообще.
Сайты для перекодировки онлайн
Сегодня мы расскажем о самых популярных и действенных сайтах, которые помогут угадать кодировку и изменить ее на более понятную для вашего ПК. Чаще всего на таких сайтах работает автоматический алгоритм распознавания, однако в случае необходимости пользователь всегда может выбрать подходящую кодировку в ручном режиме.
Способ 1: Универсальный декодер
Декодер предлагает пользователям просто скопировать непонятный отрывок текста на сайт и в автоматическом режиме переводит кодировку на более понятную. К преимуществам можно отнести простоту ресурса, а также наличие дополнительных ручных настроек, которые предлагают самостоятельно выбрать нужный формат.
Работать можно только с текстом, размер которого не превышает 100 килобайт, кроме того, создатели ресурса не гарантируют, что перекодировка будет в 100% случаев успешной. Если ресурс не помог – просто попробуйте распознать текст с помощью других способов.
- Копируем текст, который нужно декодировать, в верхнее поле. Желательно, чтобы в первых словах уже содержались непонятные символы, особенно в случаях, когда выбрано автоматическое распознавание.
- Указываем дополнительные параметры. Если необходимо, чтобы кодировка была распознана и преобразована без вмешательства пользователя, в поле «Выберите кодировку» щелкаем на «Автоматически». В расширенном режиме можно выбрать начальную кодировку и формат, в который нужно преобразовать текст. После завершения настройки щелкаем на кнопку «ОК».
- Преобразованный текст отобразится в поле «Результат», оттуда его можно скопировать и вставить в документ для последующего редактирования.
Способ 2: Студия Артемия Лебедева
Еще один сайт для работы с кодировкой, в отличие от предыдущего ресурса имеет более приятный дизайн. Предлагает пользователям два режима работы, простой и расширенный, в первом случае после декодировки пользователь видит результат, во втором случае видна начальная и конечная кодировка.
- Выбираем режим декодировки на верхней панели. Мы будем работать с режимом «Сложно», чтобы сделать процесс более наглядным.
- Вставляем нужный для расшифровки текст в левое поле. Выбираем предполагаемую кодировку, желательно оставить автоматические настройки — так вероятность успешной дешифровки возрастет.
- Щелкаем на кнопку «Расшифровать».
- Результат появится в правом поле. Пользователь может самостоятельно выбрать конечную кодировку из ниспадающего списка.
С сайтом любая непонятная каша из символов быстро превращается в понятный русский текст. На данный момент работает ресурс со всеми известными кодировками.
Способ 3: Fox Tools
Fox Tools предназначен для универсальной декодировки непонятных символов в обычный русский текст. Пользователь может самостоятельно выбрать начальную и конечную кодировку, есть на сайте и автоматический режим.
Дизайн простой, без лишних наворотов и рекламы, которая мешает нормальной работе с ресурсом.
- Вводим исходный текст в верхнее поле.
- Выбираем начальную и конечную кодировку. Если данные параметры неизвестны, оставляем настройки по умолчанию.
- После завершения настроек нажимаем на кнопку «Отправить».
- Из списка под начальным текстом выбираем читабельный вариант и щелкаем на него.
- Вновь нажимаем на кнопку «Отправить».
- Преобразованный текст будет отображаться в поле «Результат».
Несмотря на то, что сайт якобы распознает кодировку в автоматическом режиме, пользователю все равно приходится выбирать понятный результат в ручном режиме. Из-за данной особенности куда проще воспользоваться описанными выше способами.
Рассмотренный сайты позволяют всего в несколько кликов преобразовать непонятный набор символов в читаемый текст. Самым практичным оказался ресурс Универсальный декодер — он безошибочно перевел большинство зашифрованных текстов.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Смена кодировки прямо в браузере
В любом браузере есть специальная опция для перекодировки отдельной страницы. Так, в Гугл Хром нужно зайти в меню «Инструменты» и указать необходимую кодировку. Стандартными в рунете считается CP1251 (иногда с приставкой «Windows», «Microsoft») и UTF8. Последняя наиболее распространенная, она применяется на сайтах по умолчанию. В Опере, Мозилле и других браузерах также присутствует подобная функция. Обычно найти опцию несложно. Приводить подробные инструкции для каждого браузера нет смысла, потому как в них довольно часто выпускаются обновления, и расположение функциональных значков может меняться. А в Гугл Хром интерфейс уже давно остается примерно одинаковым.
Возможность смены кодировки при помощи Word или других приложений – очень полезная функция. Благодаря ей, даже оказавшись в чужеродной среде (в документе с непонятыми письменами), вы быстро наладите взаимопонимание с текстом. Вот бы так было за границей: захотел блеснуть на иностранном языке – переключил что-то в голове – и уже оперируешь чужестранными словами.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
Пользуемся стандартным Word
Этот редактор очень популярен, именно с ним работает большая часть пользователей. Так что они регулярно сталкиваются с некорректным отображением букв или невозможностью открыть участок с неподходящей кодировкой. Если документ Ворд открылся в режиме ограниченной функциональности, следует ее убрать. Если все еще отображаются непонятные знаки, укажите верную кодировку в программных настройках. Для этого идете по такому пути:
Файл (Office)/Параметры/Дополнительно.
В разделе «Общие» установите галочку в спецнастройке «Подтверждать преобразование формата». Соглашаетесь с изменениями, закрываете прогу, а потом опять открываете файл. В окошке «Преобразование» выбираете «Кодированный текст». Ищите свой вариант.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++
» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++
После запуска «Notepad++
» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки
>Кодировки >Кириллица >OEM-866 »

и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.

Как видим, текст на Русском в CMD отобразился, как положено.
Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, «перевести» которые невозможно.
Эти случаи чаще всего связаны лишь с одним — с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой. Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона. Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных «неисправностей», но и, наоборот, для намеренного неправильного кодирования документа.
Сохранение файлов в другой кодировке
Вы не можете изменить кодировку файла, который вы сохраняете как файл .docx. Word назначит кодировку символов по умолчанию на основе вашей региональной языковой установки или UTF-8. Однако вы можете изменить кодировку, изменив файл в текстовом формате.
- Перейдите в меню «Файл» и выберите «Сохранить как».
- Щелкните раскрывающийся список «Сохранить как тип» и выберите вариант «Обычный текст».
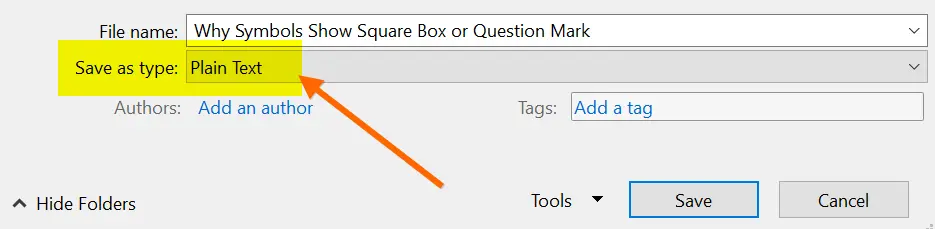
Сохранить документ Word в виде обычного текста
Нажмите кнопку «Сохранить», и Word откроет диалоговое окно «Преобразование файла», как описано выше. Оттуда вы можете изменить кодировку и сохранить документ.
Общие сведения о кодировке текста
Информация, которая выводится на экран в виде текста, на самом деле хранится в текстовом файле в виде числовых значений. Компьютер преобразует эти значения в отображаемые знаки, используя кодировку.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.
При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.
Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.