Регулярные выражения grep, egrep, sed в linux
Содержание:
- Команды Linux, для работы с файлами
- grep — что это и зачем может быть нужно
- Опции
- Примеры использования регулярных выражений
- Примеры команды grep в Linux и Unix
- Назначение операторов find и grep
- Match regular expression in files
- Синтаксис grep
- Поиск по размеру файла
- Character classes and bracket expressions
- Basic Usage
- Использование sed в Linux
- 1.2 Общие параметры и примеры команды find
- Why do we use grep?
- Искать полные слова
- Поиск рекурсивно
- Grep AND
- Синтаксис
Команды Linux, для работы с файлами
Эти команды используются для обработки файлов и каталогов.
33. ls
Очень простая, но мощная команда, используемая для отображения файлов и каталогов. По умолчанию команда ls отобразит содержимое текущего каталога.
34. pwd
Linux pwd — это команда для показывает имя текущего рабочего каталога. Когда мы теряемся в каталогах, мы всегда можем показать, где мы находимся.
Пример ример ниже:
35. mkdir
В Linux мы можем использовать команду mkdir для создания каталога.
По умолчанию, запустив mkdir без какой-либо опции, он создаст каталог в текущем каталоге.
36. cat
Мы используем команду cat в основном для просмотра содержимого, объединения и перенаправления выходных файлов. Самый простой способ использовать cat— это просто ввести » имя_файла cat’.
В следующих примерах команды cat отобразится имя дистрибутива Linux и версия, которая в настоящее время установлена на сервере.
37. rm
Когда файл больше не нужен, мы можем удалить его, чтобы сэкономить место. В системе Linux мы можем использовать для этого команду rm.
38. cp
Команда Cp используется в Linux для создания копий файлов и каталогов.
Следующая команда скопирует файл ‘myfile.txt» из текущего каталога в «/home/linkedin/office«.
39. mv
Когда вы хотите переместить файлы из одного места в другое и не хотите их дублировать, требуется использовать команду mv. Подробнее можно прочитать ЗДЕСЬ.
40.cd
Команда Cd используется для изменения текущего рабочего каталога пользователя в Linux и других Unix-подобных операционных системах.
41. Ln
Символическая ссылка или программная ссылка — это особый тип файла, который содержит ссылку, указывающую на другой файл или каталог. Команда ln используется для создания символических ссылок.
Команда Ln использует следующий синтаксис:
42. touch
Команда Touch используется в Linux для изменения времени доступа к файлам и их модификации. Мы можем использовать команду touch для создания пустого файла.
44. head
Команда head используется для печати первых нескольких строк текстового файла. По умолчанию команда head выводит первые 10 строк каждого файла.
45. tail
Как вы, возможно, знаете, команда cat используется для отображения всего содержимого файла с помощью стандартного ввода. Но в некоторых случаях нам приходится отображать часть файла. По умолчанию команда tail отображает последние десять строк.
46. gpg
GPG — это инструмент, используемый в Linux для безопасной связи. Он использует комбинацию двух ключей (криптография с симметричным ключом и открытым ключом) для шифрования файлов.
50. uniq
Uniq — это инструмент командной строки, используемый для создания отчетов и фильтрации повторяющихся строк из файла.
53. tee
Команда Linux tee используется для связывания и перенаправления задач, вы можете перенаправить вывод и/или ошибки в файл, и он не будет отображаться в терминале.
54. tr
Команда tr (translate) используется в Linux в основном для перевода и удаления символов. Его можно использовать для преобразования прописных букв в строчные, сжатия повторяющихся символов и удаления символов.
grep — что это и зачем может быть нужно
Про «репку» (как я её называю) почему-то в курсе не многие, что печалит. «Унылая» (не в обиду) формулировка из Википедии звучит примерно так:
grep — утилита командной строки, которая находит на вводе строки, отвечающие заданному регулярному выражению, и выводит их, если вывод не отменён специальным ключом.
Не сильно легче, но доступнее, можно сформулировать так:
grep — утилита командной строки, используется для поиска и фильтрации текста в файлах, на основе шаблона, который (шаблон) может быть регулярным выражением.
Если всё еще ничего не понятно, то условно говоря это удобный поиск текста везде и всюду, в особенности в файлах, директория в и тп. Удобно распарсивать логи и их содержимое, не прибегая к софту, как это бывает в Windows.
Справку можно вычленить так же как по find, т.е методом pgrep, fgrep, egrep и черт знает что еще:
Или:
Расписывать все ключи и даже основные тут (вы еще помните, что это блоговая часть сайта?) не буду, так как в отличии от find’а, последних тут вообще страшное подмножество, особенно учитывая, что существуют pgrep, fgrep, egrep и черт знает что еще, которые, в некотором смысле тоже самое, но для определенных целей.
Потрясающе удобная штука, которая жизненно необходима, особенно, если Вы что-то когда-то где-то зачем-то администрировали. Взглянем на примеры.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -b — показывать номер блока перед строкой;
- -c — подсчитать количество вхождений шаблона;
- -h — не выводить имя файла в результатах поиска внутри файлов Linux;
- -i — не учитывать регистр;
- — l — отобразить только имена файлов, в которых найден шаблон;
- -n — показывать номер строки в файле;
- -s — не показывать сообщения об ошибках;
- -v — инвертировать поиск, выдавать все строки кроме тех, что содержат шаблон;
- -w — искать шаблон как слово, окружённое пробелами;
- -e — использовать регулярные выражения при поиске;
- -An — показать вхождение и n строк до него;
- -Bn — показать вхождение и n строк после него;
- -Cn — показать n строк до и после вхождения;
Все самые основные опции рассмотрели и даже больше, теперь перейдём к примерам работы команды grep Linux.
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать команду egrep:
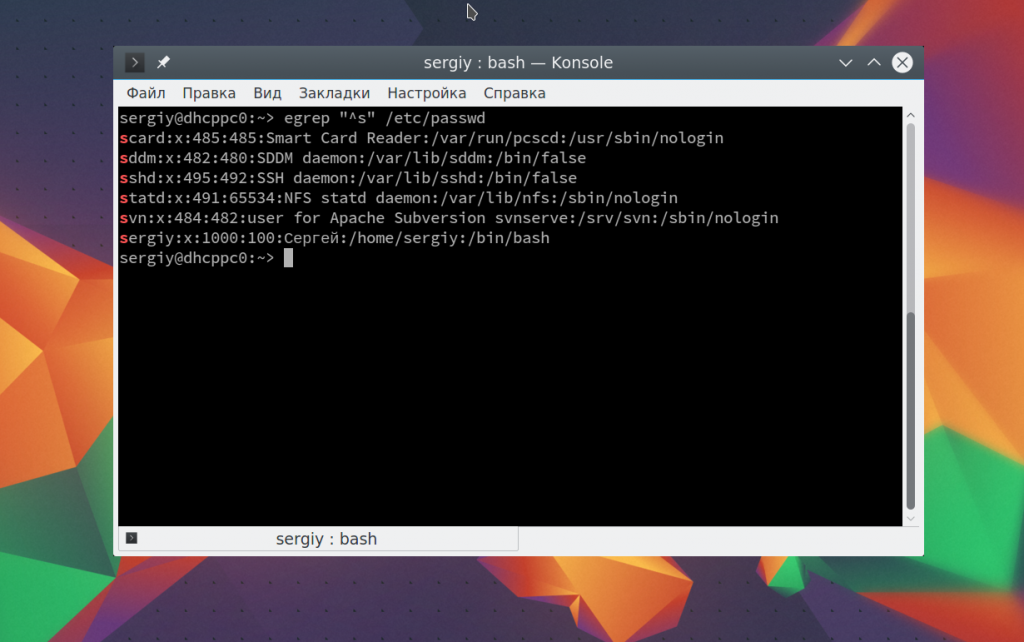
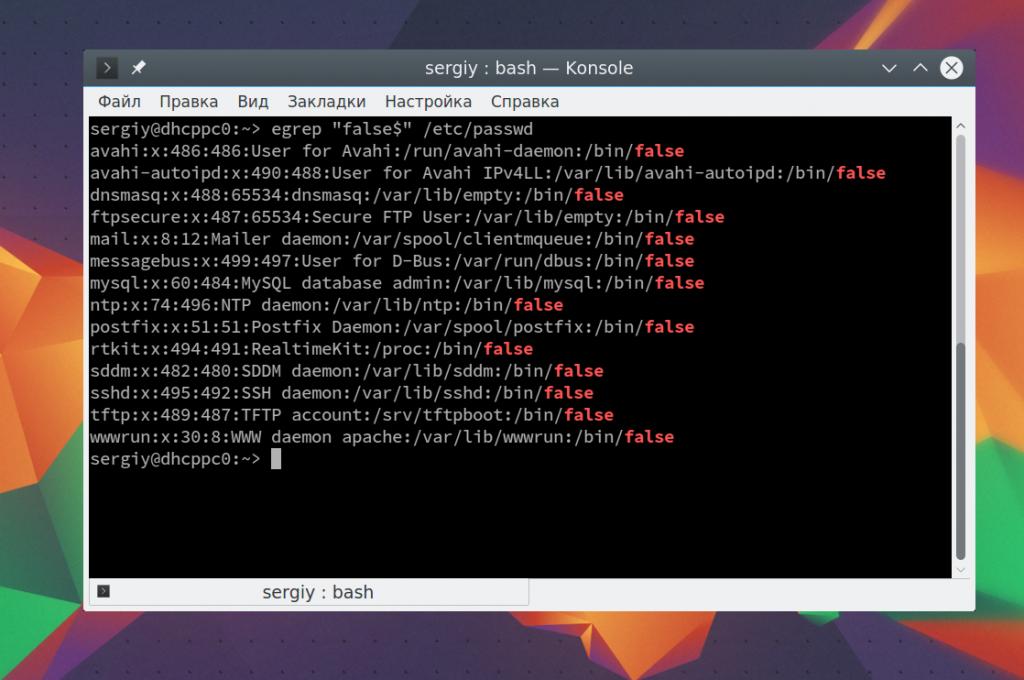
Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:
Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
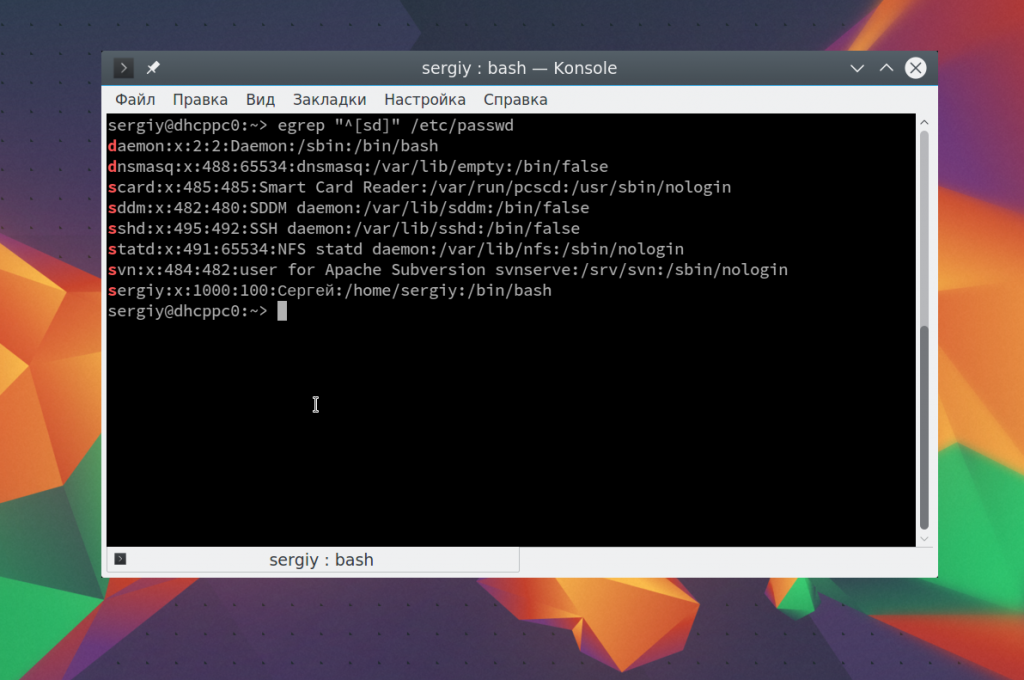 Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
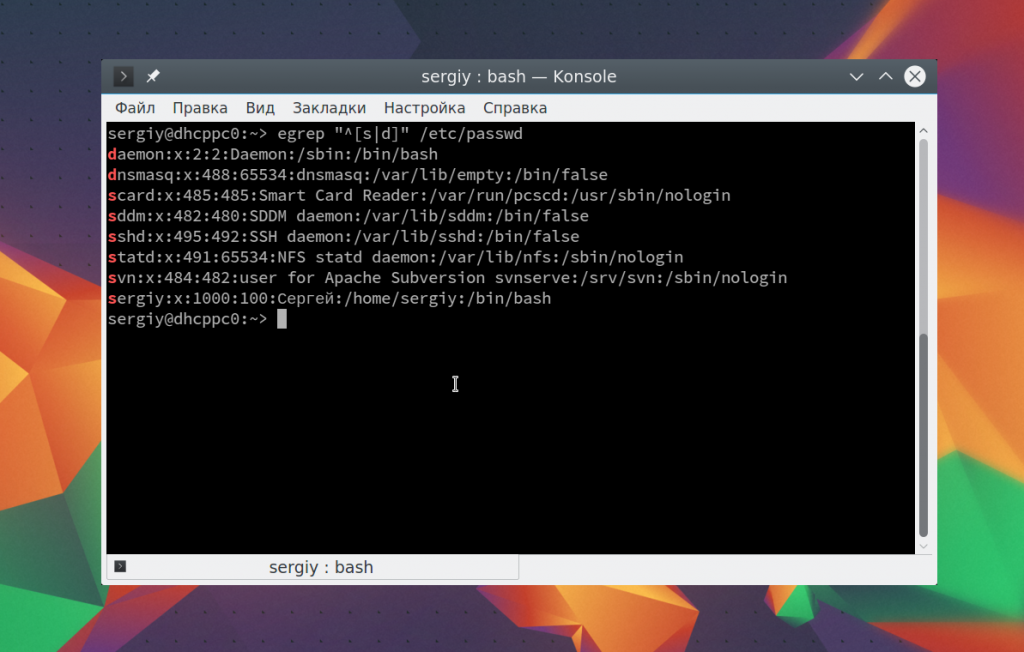
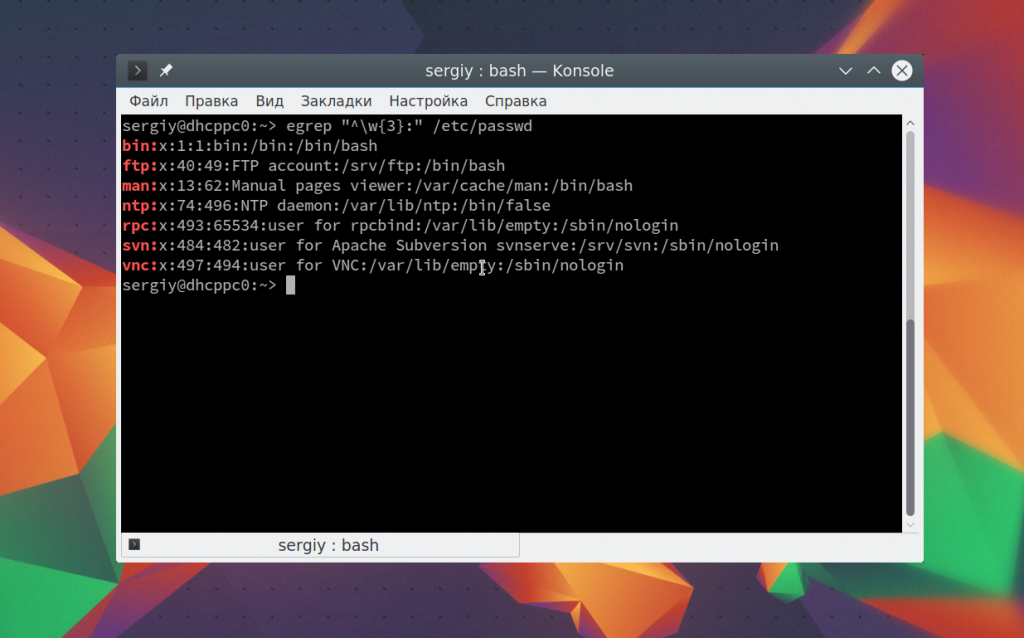
Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием:
Примеры команды grep в Linux и Unix
Ниже приведены некоторые стандартные команды grep, объясненные с примерами, которые помогут вам начать работу с grep в Linux, macOS и Unix:
- Найдите любую строку, которая содержит слово в имени файла в Linux: grep 'word' filename
- Выполните поиск слова ‘bar’ без учета регистра в Linux и Unix: grep -i 'bar' file1
- Найдите все файлы в текущем каталоге и во всех его подкаталогах в Linux по слову httpd: grep -R 'httpd' .
- Найдите и отобразите общее количество раз, когда строка ‘nixcraft’ появляется в файле с именем frontpage.md:: grep -c 'nixcraft' frontpage.md
Давайте подробно рассмотрим все команды и параметры.
Синтаксис
Синтаксис grep следующий:
grep 'word' filename fgrep 'word-to-search' file.txt grep 'word' file1 file2 file3 grep 'string1 string2' filename cat otherfile | grep 'something' command | grep 'something' command option1 | grep 'data' grep --color 'data' fileName grep -options pattern filename fgrep -options words file |
grep ‘word’ filename
fgrep ‘word-to-search’ file.txt
grep ‘word’ file1 file2 file3
grep ‘string1 string2’ filename
cat otherfile | grep ‘something’
command | grep ‘something’
command option1 | grep ‘data’
grep —color ‘data’ fileName
grep pattern filename
fgrep words file
Назначение операторов find и grep
Команда find в Linux является оператором командной строки для работы с файлами в обход существующей иерархии. Она позволяет производить поиск файлов с использованием множества фильтров, а также выполнять некие действия над файлами после их успешного поиска. Среди критериев поиска файлов – практически все доступные атрибуты, от даты создания до разрешения.
Команда grep в Linux также относится к поисковым, но внутри файлов. Буквальный перевод команды – «глобальная печать регулярных выражений», но под печатью здесь понимается вывод результатов работы на устройство по умолчанию, каковым обычно является монитор. Обладая огромным потенциалом, оператор используется достаточно часто и позволяет производить поиск внутри одного или нескольких файлов по заданным фрагментам (шаблонам). Поскольку терминология в Linuxе существенно отличается от таковой в среде Windows, очень многие пользователи испытывают значительные трудности с использованием этих команд. Постараемся устранить этот недостаток.
Match regular expression in files
Syntax: grep "REGEX" filename
This is a very powerful feature, if you can use use regular expression effectively. In the following example, it searches for all the pattern that starts with «lines» and ends with «empty» with anything in-between. i.e To search «linesempty» in the demo_file.
$ grep "lines.*empty" demo_file Two lines above this line is empty.
From documentation of grep: A regular expression may be followed by one of several repetition operators:
- ? The preceding item is optional and matched at most once.
- * The preceding item will be matched zero or more times.
- + The preceding item will be matched one or more times.
- {n} The preceding item is matched exactly n times.
- {n,} The preceding item is matched n or more times.
- {,m} The preceding item is matched at most m times.
- {n,m} The preceding item is matched at least n times, but not more than m times.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep шаблон
Или:
$ команда | grep шаблон
- Опции — это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон — это любая строка или регулярное выражение, по которому будет вестись поиск
- Файл и команда — это то место, где будет вестись поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится,например, когда нужно выбрать только ошибки из логов или найти PID процесса в многочисленном отчёте утилиты ps.
Поиск по размеру файла
df -h /boot
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 1014M 194M 821M 20% /boot
Найти обычные файлы определённого размера
Чтобы найти обычные файлы нужно использовать
-type f
find /boot -size +20000k -type f
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
/boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
/boot/initramfs-3.10.0-1160.el7.x86_64.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
Файлы бывают следующих типов:
— : regular file
d : directory
c : character device file
b : block device file
s : local socket file
p : named pipe
l : symbolic link
Подробности в статье —
«Файлы в Linux»
find /boot -size +10000k -type f
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
/boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
/boot/initramfs-3.10.0-1160.el7.x86_64.img
/boot/initramfs-3.10.0-1160.el7.x86_64kdump.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
/boot/initramfs-3.10.0-1160.2.2.el7.x86_64kdump.img
То же самое плюс показать размер файлов
find /boot -size +10000k -type f -exec du -h {} \;
find: ‘/boot/efi/EFI/centos’: Permission denied
find: ‘/boot/grub2’: Permission denied
60M /boot/initramfs-0-rescue-389ee10be1b38d4281b9720fabd80a37.img
21M /boot/initramfs-3.10.0-1160.el7.x86_64.img
13M /boot/initramfs-3.10.0-1160.el7.x86_64kdump.img
21M /boot/initramfs-3.10.0-1160.2.2.el7.x86_64.img
14M /boot/initramfs-3.10.0-1160.2.2.el7.x86_64kdump.img
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is often not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
Basic Usage
In this tutorial, you’ll use to search the GNU General Public License version 3 for various words and phrases.
If you’re on an Ubuntu system, you can find the file in the folder. Copy it to your home directory:
If you’re on another system, use the command to download a copy:
You’ll also use the BSD license file in this tutorial. On Linux, you can copy that to your home directory with the following command:
If you’re on another system, create the file with the following command:
Now that you have the files, you can start working with .
In the most basic form, you use to match literal patterns within a text file. This means that if you pass a word to search for, it will print out every line in the file containing that word.
Execute the following command to use to search for every line that contains the word :
The first argument, , is the pattern you’re searching for, while the second argument, , is the input file you wish to search.
The resulting output will be every line containing the pattern text:
On some systems, the pattern you searched for will be highlighted in the output.
Common Options
By default, will search for the exact specified pattern within the input file and return the lines it finds. You can make this behavior more useful though by adding some optional flags to .
If you want to ignore the “case” of your search parameter and search for both upper- and lower-case variations, you can specify the or option.
Search for each instance of the word (with upper, lower, or mixed cases) in the same file as before with the following command:
The results contain: , , and :
If there was an instance with , that would have been returned as well.
If you want to find all lines that do not contain a specified pattern, you can use the or option.
Search for every line that does not contain the word in the BSD license with the following command:
You’ll receive this output:
Since you did not specify the “ignore case” option, the last two items were returned as not having the word .
It is often useful to know the line number that the matches occur on. You can do this by using the or option. Re-run the previous example with this flag added:
This will return the following text:
Now you can reference the line number if you want to make changes to every line that does not contain . This is especially handy when working with source code.
Использование sed в Linux
sed (от англ. Stream EDitor) — потоковый текстовый редактор (а также язычок программирования), использующий различные предопределённые текстовые преобразования к последовательному потоку текстовых этих. Sed можно утилизировать как grep, выводя строки по шаблону базового регулярного выражения:
Может быть использовать его для удаления строк (удаление всех пустых строк):
Основным инструментом работы с sed является выражение типа:
Так, образчик, если выполнить команду:
Выше рассмотрены различия меж «grep», «egrep» и «fgrep». Невзирая на различия в наборе используемых регулярных представлений и скорости выполнения, параметры командной строчки остаются одинаковыми для всех трех версий grep.
1.2 Общие параметры и примеры команды find
-perm: Найти файлы в соответствии с правами доступа.
-prune: Используйте эту опцию, чтобы команда поиска не выполняла поиск в указанном каталоге. Если вы также используете опцию -depth, то команда -prune будет игнорироваться командой поиска.
-user: Найти файл в соответствии с владельцем файла.
-group: Найти файлы в соответствии с группой, к которой они принадлежат.
-mtime -n +n: Найти файл в соответствии со временем изменения файла, -n означает, что время изменения файла находится в течение n дней, + n означает, что время изменения файла составляет n дней назад.
-nogroupНайти файл без допустимой группы, то есть группа, к которой принадлежит файл, не существует в / etc / groups.
-nouser: Найти файл без действительного владельца, то есть владелец файла не существует в / etc / passwd.
- -newer file1 ! file2: Найти файлы, время изменения которых новее, чем file1, но старше, чем file2.
- -typeНайдите файл определенного типа, например:
-size n: Найдите файл, длина файла которого составляет n блоков, с c означает, что длина файла в байтах.
-depth: При поиске файла сначала найдите файл в текущем каталоге, а затем выполните поиск в его подкаталогах.
-mount: Не пересекать точки монтирования файловой системы при поиске файлов.
-follow: если команда find встречает файл символьной ссылки, она будет следовать за файлом, на который указывает ссылка.
Why do we use grep?
Grep is a command-line tool that Linux users use to search for strings of text. You can use it to search a file for a certain word or combination of words, or you can pipe the output of other Linux commands to grep, so grep can show you only the output that you need to see.
Let’s look at some really common examples. Say that you need to check the contents of a directory to see if a certain file exists there. That’s something you would use the “ls” command for.
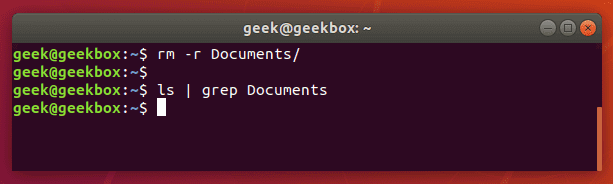
But, to make this whole process of checking the directory’s contents even faster, you can pipe the output of the ls command to the grep command. Let’s look in our home directory for a folder called Documents.
And now, let’s try checking the directory again, but this time using grep to check specifically for the Documents folder.
$ ls | grep Documents
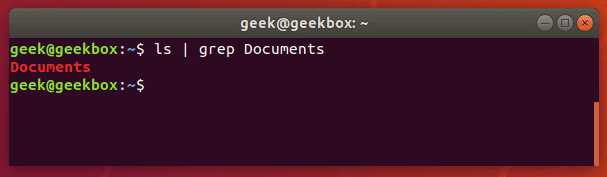
As you can see in the screenshot above, using the grep command saved us time by quickly isolating the word we searched for from the rest of the unnecessary output that the ls command produced.
If the Documents folder didn’t exist, grep wouldn’t return any output. So if grep returns nothing, that means that it couldn’t find the word you are searching for.
Искать полные слова
При поиске строки отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр (или ).
Символы слова включают буквенно-цифровые символы ( , и ) и символы подчеркивания ( ). Все остальные символы считаются несловесными символами.
Если вы запустите ту же команду, что и выше, включая параметр , команда вернет только те строки, где включен как отдельное слово.
Поиск рекурсивно
Вы можете использовать ключ -r с grep для рекурсивного поиска по всем файлам в каталоге и его подкаталогах по указанному шаблону.
$ grep -r pattern /directory/to/search
Если вы не укажете каталог, grep будет просто искать ваш текущий рабочий каталог. На приведенном ниже снимке экрана grep обнаружил два файла, соответствующих нашему шаблону, и возвращает их имена файлов и каталог, в котором они находятся.
Найти вкладку
Как мы упоминали ранее в объяснении того, как искать строку, вы можете заключить текст в кавычки, если он содержит пробелы. Тот же метод будет работать для вкладок, но мы сейчас объясним, как поместить вкладку в вашу команду grep.
Поставьте пробел или несколько пробелов внутри кавычек, чтобы grep искал этот символ.
$ grep " " sample.txt
Существует несколько различных способов поиска вкладки с помощью grep, но большинство методов являются экспериментальными или могут быть несовместимыми в разных дистрибутивах.
Самый простой способ — просто найти сам символ табуляции, который вы можете создать, нажав Ctrl + V на клавиатуре, после чего нажмите Tab.
Обычно нажатие клавиши tab в окне терминала говорит терминалу, что вы хотите автоматически завершить команду, но предварительное нажатие комбинации ctrl + v приведет к тому, что символ табуляции будет записан так, как вы обычно ожидаете в текстовом редакторе. ,
$ grep " " sample.txt
Grep AND
5. Grep AND using -E ‘pattern1.*pattern2’
There is no AND operator in grep. But, you can simulate AND using grep -E option.
grep -E 'pattern1.*pattern2' filename grep -E 'pattern1.*pattern2|pattern2.*pattern1' filename
The following example will grep all the lines that contain both “Dev” and “Tech” in it (in the same order).
$ grep -E 'Dev.*Tech' employee.txt 200 Jason Developer Technology $5,500
The following example will grep all the lines that contain both “Manager” and “Sales” in it (in any order).
$ grep -E 'Manager.*Sales|Sales.*Manager' employee.txt
Note: Using regular expressions in grep is very powerful if you know how to use it effectively.
6. Grep AND using Multiple grep command
You can also use multiple grep command separated by pipe to simulate AND scenario.
grep -E 'pattern1' filename | grep -E 'pattern2'
The following example will grep all the lines that contain both “Manager” and “Sales” in the same line.
$ grep Manager employee.txt | grep Sales 100 Thomas Manager Sales $5,000 500 Randy Manager Sales $6,000
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*

Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*

Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test

Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root

Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»

Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file

Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file

Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:




