Новая данность: что такое data science и зачем она нужна бизнесу
Содержание:
- Как стать Data Scientist с нуля?
- Что попробовать
- Что поможет дата-сайентистам и инженерам данных в карьерном росте
- Оплата труда
- Дата-сайентисты в облаках
- Уровень 1. От стажёра к джуну
- Профессия Data Scientist от Skillbox
- Линейная алгебра
- Что изучает Data Science
- Кто такой аналитик-разработчик?
- Сколько получают дата-инженеры и дата-сайентисты
- Как устроена наука Data Science
- Data Scientist – технические навыки
- Требования к специалисту
- Будущее Data Science
- С чего начать обучение Data Science самостоятельно
- Data Scientist: кто это и что он делает
Как стать Data Scientist с нуля?
Давайте разберемся, с чего начать обучение профессии, и как можно стать специалистом по анализу данных.
- Первый способ – поступить в профильный вуз и параллельно освоить необходимые языки программирования и инструменты визуализации. Есть несколько вузов, выпускники которых особенно ценятся среди работодателей.
- Второй способ – пойти на курсы, где вы изучите математическую базу и получите практические навыки. Если у вас уже есть техническое образование, пусть даже не связанное с Data Scientist, это оптимальный вариант. Если технического образования нет, то найти первую работу будет сложнее. Вам могут помочь курсы, где есть программы помощи с трудоустройством.
-
Часто в профессию переходят аналитики данных и Python-разработчики. Сфера активно растет, поэтому людей привлекают высокие зарплаты и перспективы.
Также освоить профессию Data Scientist можно через интернет. Многие люди, которые ищут, с чего начать карьеру в этой сфере, выбирают данный путь. Есть несколько онлайн-университетов, где можно пройти обучение:
|
Название курса и ссылка на него |
Описание |
|
Профессия Data Scientist в Skillbox |
Курс в университете Skillbox. Подходит новичкам и людям без опыта работы в IT. Вы изучите теорию (анализ данных, Machine Learning, статистика, теория вероятностей, функции, работа с производными и многое другое), научитесь программировать на Python и языке R, изучите библиотеки Pandas, NumPy и Matplotlib, работу с базами данных. Сможете создавать рекомендательные системы, применять нейронные сети для решения задач, визуализировать данные. Включает практические задания. На защите диплома присутствуют работодатели. |
|
Обучение Data Scientist в Нетологии (уровень – с нуля) |
Курс походит людям, которые хотят сменить текущую профессию на Data Scientist. Включает программу помощи с трудоустройством. Изучают математику для анализа данных, построение моделей, управление data-проектами, Python, базы данных, обработку естественного языка (NLP) и многое другое. Объема полученных знаний хватит для старта в карьере. Преподаватели – сотрудники крупных ИТ и финансовых компаний. |
В интернете есть бесплатные курсы по Data Scientist. Если вы думаете, подойдет или нет вам эта профессия, то можете посмотреть данные уроки и получить более полное представление и описание данной работы:
- Анализ данных на Python в задачах и примерах
- Курс по библиотеке Pandas
- Курс по машинному обучению для новичков
- Бесплатный курс по базам данных MySQL
-
Работа с Google Таблицами для начинающих
Что попробовать
Иллюстратор Сэм Лернер создал невероятную визуализацию. Теперь мы можем проследить за движением капли дождя (!) по лужам, каналам, ручьям и рекам США! Для этого необходимо кликнуть на любое место на карте, откуда начнёт свой путь капля, и медитативно наблюдать за её путешествием до самого океана.
Это — сайт, который генерирует фотографии котиков. Как следует из названия, этих животных никогда не существовало: ИИ «показали» множество картинок котиков, после чего он научился генерировать их самостоятельно. Чтобы получить новое изображение, достаточно обновить сайт. Кроме того, существуют сервисы для генерации человеческих лиц и аниме-персонажей.
Что поможет дата-сайентистам и инженерам данных в карьерном росте
Появилось достаточно много новых инструментов по работе с данными. И мало кто одинаково хорошо разбирается во всех.
Многие компании не готовы нанимать сотрудников без опыта работы. Однако кандидаты с минимальной базой и знанием основ популярных инструментов могут получить нужный опыт, если будут обучаться и развиваться самостоятельно.
Полезные качества для дата-инженера и дата-сайентиста
Желание и умение учиться. Необязательно сразу гнаться за опытом или менять работу ради нового инструмента, но нужно быть готовым переключиться на новую область.
Стремление к автоматизации рутинных процессов
Это важно не только для продуктивности, но и для поддержания высокого качества данных и скорости их доставки до потребителя
Внимательность и понимание «что там под капотом» у процессов. Быстрее решит задачу тот специалист, у которого есть насмотренность и доскональное знание процессов.
Кроме отличного знания алгоритмов, структур данных и пайплайнов, нужно научиться мыслить продуктами — видеть архитектуру и бизнес-решение как единую картину.
Например, полезно взять любой известный сервис и придумать для него базу данных
Затем подумать, как разработать ETL и DW, которые наполнят её данными, какие будут потребители и что им важно знать о данных, а также как покупатели взаимодействуют с приложениями: для поиска работы и знакомств, прокат автомобилей, приложение для подкастов, образовательная платформа
Позиции аналитика, Data Scientist и Data Engineer очень близки, поэтому переходить из одного направления в другое можно быстрее, чем из других сфер.
В любом случае, обладателям любого ИТ-бэкграунда будет проще, чем тем, у кого его нет. В среднем взрослые мотивированные люди переучиваются и меняют работу каждые 1,5‒2 года. Легче это даётся тем, кто учится в группе и с наставником, — по сравнению с теми, кто опирается лишь на открытые источники.
Материал изначально опубликован на habr.
Оплата труда
Зарплата data scientists зависит от ряда факторов, включая опыт, квалификацию, местоположение и сектор, в котором сотрудник работает. Условия бывают разными, в зависимости от организации, но весьма распространены гибкий или удаленный график работы, бонусы по результатам работы и частное медицинское страхование.
Заработная плата сайентистов в России обычно начинается от 70 000 до 85 000 рублей и может возрасти до 100 000 рублей, в зависимости от опыта и навыков. В Москве и Санкт-Петербурге можно рассчитывать на заработок от 100 000 до 160 000 рублей.
Ведущие и главные специалисты по данным способны зарабатывать более 200 000 – 250 000 рублей, а в некоторых случаях – и более.
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Sbercloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах SberCloud.

Футурология
«Я бы вакцинировал троих на миллион». Интервью с нейросетью GPT-3
Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер SberCloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании SberCloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.
Уровень 1. От стажёра к джуну
Главное на этом уровне — научиться работать с датасетами в виде CSV-файлов, обрабатывать и визуализировать данные, понимать, что такое линейная регрессия.
Основы обработки данных
В первую очередь придётся манипулировать данными, чистить, структурировать и приводить их к единой размерности или шкале. От новичка ждут уверенной работы с библиотеками Pandas и NumPy и некоторых специальных навыков:
- импорт и экспорт данных в CSV-формате;
- очистка, предварительная подготовка, систематизация данных для анализа или построения модели;
- работа с пропущенными значениями в датасете;
- понимание принципов замены недостающих данных (импутации) и их реализация — например, замена средними или медианами;
- работа с категориальными признаками;
- разделение датасета на обучающую и тестовую части;
- нормировка данных с помощью нормализации и стандартизации;
- уменьшение объёма данных с помощью техник снижения размерности — например, метода главных компонент.
Визуализация данных
Новичок должен знать основные принципы хорошей визуализации и инструменты — в том числе Python-библиотеки matplotlib и seaborn (для R — ggplot2).
Какие компоненты нужны для правильной визуализации данных:
Данные. Прежде чем решить, как именно визуализировать данные, надо понять, к какому типу они относятся: категориальные, численные, дискретные, непрерывные, временной ряд.
Геометрия. То есть какой график вам подойдёт: диаграмма рассеяния, столбиковая диаграмма, линейный график, гистограмма, диаграмма плотности, «ящик с усами», тепловая карта.
Координаты. Нужно определить, какая из переменных будет отражена на оси x, а какая — на оси y
Это важно, особенно если у вас многомерный датасет с несколькими признаками.
Шкала. Решите, какую шкалу будете использовать: линейную, логарифмическую или другие.
Текст
Всё, что касается подписей, надписей, легенд, размера шрифта и так далее.
Этика. Убедитесь, что ваша визуализация излагает данные правдиво. Иными словами, что вы не вводите в заблуждение свою аудиторию, когда очищаете, обобщаете, преобразовываете и визуализируете данные.
Обучение с учителем: предсказание непрерывных переменных
Главное: стажёру придётся изучить методы регрессии, стать почти на ты с библиотеками scikit-learn и caret, чтобы строить модели линейной регрессии
Но чтобы стать полноценным джуниором, стажёр должен знать и уметь ещё кучу всего (осторожно — там сложные слова, но есть подсказки):
- проводить простой регрессионный анализ с помощью NumPy или Pylab;
- использовать библиотеку scikit-learn, чтобы решать задачи с множественной регрессией;
- понимать методы регуляризации: метод LASSO, метод упругой сети, метод регуляризации Тихонова;
- знать непараметрические методы регрессии: метод k-ближайших соседей и метод опорных векторов;
- понимать метрики оценок моделей регрессии: среднеквадратичная ошибка, средняя абсолютная ошибка и коэффициент детерминации R-квадрат;
- сравнивать разные модели регрессии.
Профессия Data Scientist от Skillbox
Для анализа больших и неоднородных массивов данных используется технология Big Data. Машинные технологии научились делать выводы и использовать инфографику для визуализации данных. На услуги Data Scientist предъявляют спрос банки, мобильные операторы, производители программных продуктов. Уровень оплаты в Big Data стабильно высок. Обучиться профессии с нуля могут новички, а опытные программисты прокачают свои навыки. Курс от Skillbox задействует разные инструменты — языки кода, фреймворки, библиотеки и базы данных.
Освоение новых знаний происходит в контакте с наставником. Сообщество профессионалов Skillbox даёт обратную связь при выполнении заданий и помогает выпускникам с трудоустройством.
Линейная алгебра
Большой раздел математики, имеющий дело со скалярами, наборами скаляров (векторами), массивами чисел (матрицами) и наборами матриц (тензорами).
Ключевые понятия линейной алгебры. Источник
Почти любая информация может быть представлена с помощью матрицы. Объясним на примере: МРТ-снимок головного мозга — это набор плоских снимков, слоев мозга. Каждый плоский снимок можно представить как таблицу интенсивности серого цвета, а весь МРТ-снимок — это будет тензор. Затем можно найти спектр матрицы — набор всех собственных чисел векторов. С помощью спектров можно классифицировать данные на норму и патологию и выявить, например, есть ли у человека заболевание мозга.
Теперь возьмем задачу, связанную с бизнесом, — проанализировать и спрогнозировать прибыль сети магазинов. Отдельный магазин можно описать набором чисел, которые показывают размер прибыли, количество товара, количество рабочих часов в неделе, время открытия и закрытия. Набор этих чисел будет вектором. Для всей сети магазинов набор векторов составит таблицу с числами или матрицу.
Частично линейную алгебру используют в крупных компаниях при разработке рекомендательных систем (например, в Facebook, YouTube, Instagram). Знания о матрицах, их свойствах и операциях с ними помогут понять, как устроен механизм работы методов библиотеки NumPy, как считаются важные статистические величины для больших данных.
Что изучает Data Science
Каждый день человечество генерирует примерно 2,5 квинтиллиона байт различных данных. Они создаются буквально при каждом клике и пролистывании страницы, не говоря уже о просмотре видео и фотографий в онлайн-сервисах и соцсетях.
Наука о данных появилась задолго до того, как их объемы превысили все мыслимые прогнозы. Отсчет принято вести с 1966 года, когда в мире появился Комитет по данным для науки и техники — CODATA. Его создали в рамках Международного совета по науке, который ставил своей целью сбор, оценку, хранение и поиск важнейших данных для решения научных и технических задач. В составе комитета работают ученые, профессора крупных университетов и представители академий наук из нескольких стран, включая Россию.
Сам термин Data Science вошел в обиход в середине 1970-х с подачи датского ученого-информатика Петера Наура. Согласно его определению, эта дисциплина изучает жизненный цикл цифровых данных от появления до использования в других областях знаний. Однако со временем это определение стало более широким и гибким.
Data Science (DS) — междисциплинарная область на стыке статистики, математики, системного анализа и машинного обучения, которая охватывает все этапы работы с данными. Она предполагает исследование и анализ сверхбольших массивов информации и ориентирована в первую очередь на получение практических результатов.
В 2010-х годах объемы данных по экспоненте. Свою роль сыграл целый ряд факторов — от повсеместного распространения мобильного интернета и популярности соцсетей до всеобщей оцифровки сервисов и процессов. В итоге профессия дата-сайентиста быстро превратилась в одну из самых популярных и востребованных. Еще в 2012 году позицию дата-сайентиста журналисты назвали самой привлекательной работой XXI века (The Sexiest Job of the XXI Century).
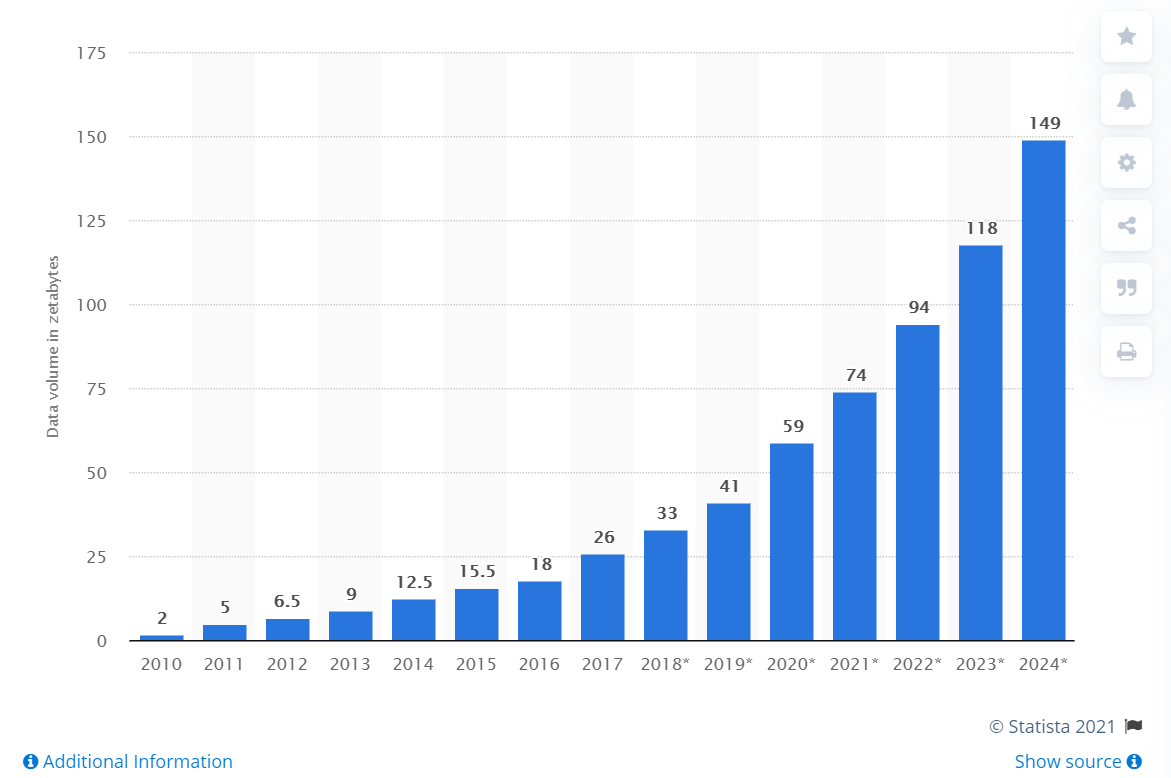
Объем данных, созданных, собранных и потребленных во всем мире с 2010 по 2024 год (в зеттабайтах)
(Фото: Statista)
Развитие Data Science шло вместе с внедрением технологий Big Data и анализа данных. И хотя эти области часто пересекаются, их не следует путать между собой. Все они предполагают понимание больших массивов информации. Но если аналитика данных отвечает на вопросы о прошлом (например, об изменениях в поведениях клиентов какого-либо интернет-сервиса за последние несколько лет), то Data Science в буквальном смысле смотрит в будущее. Специалисты по DS на основе больших данных могут создавать модели, которые предсказывают, что случится завтра. В том числе и предсказывать спрос на те или иные товары и услуги.
Кто такой аналитик-разработчик?
Я работаю аналитиком-разработчиком, занимаюсь системой автоматического мониторинга данных компании «Тинькофф» с помощью машинного обучения. Банковские продукты компании генерируют много данных: они помогают отслеживать эффективность бизнес-процессов, например изменения доходности по вкладам или продаж страховок. Обычно за каждым из процессов следят аналитики. Моя задача — помочь им автоматизировать этот процесс, чтобы они могли получать своевременные оповещения, если в их данных что-то пошло не так. Так аналитики могут увидеть нестандартное поведение своих параметров и изменить свои процессы.
Моя специализация — временные ряды. По сути, это зависимости разных величин во времени. Эти данные можно анализировать с помощью математических моделей, чтобы спрогнозировать будущие значения. Например, так прогнозируют спрос на товары в супермаркетах. Если знать статистику продаж творога в прошлые годы, этой весной можно выложить на полки нужное покупателям количество пачек с высокой точностью. В «Тинькофф» по тому же принципу мы предсказываем продажи продуктов экосистемы.
Сколько получают дата-инженеры и дата-сайентисты
Доход инженеров по обработке данных
В международной практике начальная зарплата обычно составляет $100 000 в год и значительно увеличивается с опытом, по данным Glassdoor. Кроме того, компании часто предоставляют опционы на акции и 5‒15% годовых бонусов.В России в начале карьеры зарплата обычно не меньше 50 тыс. рублей в регионах и 80 тыс. в Москве. На этом этапе не требуется опыт, кроме пройденного обучения.Через 1‒2 года работы — вилка 90‒100 тыс. рублей.Вилка увеличивается до 120‒160 тыс. через 2‒5 лет. Добавляются такие факторы, как специализация прошлых компаний, размер проектов, работа с big data и прочее.После 5 лет работы легче искать вакансии в смежных отделах или откликаться на такие узкоспециализированные позиции, как:
Архитектор или ведущий разработчик в банке или телеком — около 250 тыс.
Pre-Sales у вендора, с технологиями которого вы работали плотнее всего, — 200 тыс. плюс возможен бонус (1‒1,5 млн рублей).
Эксперты по внедрению Enterprise business application, таких как SAP, — до 350 тыс. рублей.
Доход дата-сайентистов
Исследование рынка аналитиков компании «Нормальные исследования» и рекрутингового агентства New.HR показывает, что специалисты по Data Science получают в среднем большую зарплату, чем аналитики других специальностей.
В России начальная зарплата дата-сайентиста с опытом работы до года — от 113 тыс. рублей.
В качестве опыта работы сейчас также учитывается прохождение обучающих программ.
Через 1‒2 года такой специалист уже может получать до 160 тыс. рублей.
Как устроена наука Data Science
Стандартный рабочий день для Data Science-специалиста обычно включает в себя один из этапов сбора или обработки данных. Весь рабочий процесс состоит из 5 стадий:
-
Сбор информации. Включает в себя процессы по сбору структурированных и неструктурированных данных из всех релевантных источников. Используются все подручные инструменты – от ручного ввода и скрапинга веб-страниц до сбора показателей из проприетарных систем.
-
Хранение информации. Поиск методов и средств для сохранения полученных данных в таком виде, в котором их впоследствии можно будет обработать, используя заранее предусмотренные для этого механизмы. Дата-сайентист так же должен удалить дубликаты, отфильтровать лишнее и т.п.
-
Предобработка. На этом этапе специалист должен проанализировать связи между разными кусками добытых данных, проследить паттерны и соответствие полученной информации.
-
Обработка. В этот момент специалист подключает все свои «волшебные» инструменты: искусственный интеллект, модели машинного обучения, аналитические алгоритмы и т.п.
-
Коммуникация. По итогу специалист должен оформить найденные данные в виде таблиц, графиков, списков или в любой другой форме, предпочтительной для демонстрации разным категориям потребителей этой самой информации.
Data Scientist – технические навыки
Советую начинать именно с них, чтобы вы сразу ориентировались на практику, а не уходили в математическую теорию. Самый популярный язык программирования в DS — Python. По опросу Kaggle, который площадка проводила внутри своего сообщества специалистов по обработке данных и машинному обучению в 2018 году, 83% респондентов используют Python ежедневно. Поэтому в первую очередь изучите его, но немного внимания нужно будет уделить кое-каким другим языкам. Например, R.
Драйверы профессии
- автоматизация производственных и управленческих процессов
- рост объёмов данных, доступных для анализа
- развитие концепции открытых данных
Какие задачи будет решать Data Scientist
- сбор больших массивов структурированных и неструктурированных данных (количественных, текстовых, графических и др.) и их преобразование в удобный формат
- анализ данных с помощью методов математической статистики, моделирования и других аналитических методов (машинное обучение, текстовая аналитика и др.) в целях повышения эффективности управленческих решений
- превращение инсайтов (выявленных неочевидных закономерностей) в конкретные решения для бизнеса/науки/общества
- сотрудничество с ИТ-подразделениями и управленцами
- визуализация данных
Какие знания и навыки у него будут
- умение структурировать и интегрировать разнородные источники данных
- умение применять методы системного анализа при постановке задач
- продвинутый уровень цифровых навыков
- навыки программирования и работы с базами данных
- знание методов дискретной математики, математической статистики, машинного обучения и компьютерной лингвистики
- способность разрабатывать математические модели выявления зависимостей, распознавания образов, прогнозирования и принятия решений
- презентационные навыки
Программирование
Наиболее востребованный и распространенный язык в Data Science сегодня — это Python. До него самым популярным языком был R, который продолжают использовать, например, для анализа данных, научного статистического анализа и в социологии.
По данным Towardsdatascience
Среди прочего Python хорош тем, что на его базе можно разработать практически любую библиотеку, заточенную под выполнение самых разнообразных задач. Базовый дистрибутив Python небольшой, удобен для установки и обновления. Любые дополнительные возможности можно «прикрутить» через специальные библиотеки.
У каждой библиотеки есть обширная документация, поэтому в них легко разобраться. Вокруг самых востребованных и популярных формируются сообщества, которые поддерживают библиотеку, разрабатывают для неё новые модули и функции.
Требования к специалисту
Специалист по данным неразрывно связан с Data Science – наукой о данных. Она находится на пересечении нескольких направлений: математики, статистики, информатики и экономики. Следовательно, специалисты должны понимать и интересоваться каждой из этих наук.
Кроме этого, Data Scientist должен знать:
- Языки программирования для того, чтобы писать на них код. Самые распространенные – это SAS, R, Java, C++ и Python.
- Базы данных MySQL и PostgreSQL.
- Технологии и инструменты для представления отчетов в графическом формате.
- Алгоритмы машинного и глубокого обучения, которые созданы для автоматизации повторяющихся процессов с помощью искусственного интеллекта.
- Как подготовить данные и сделать их перевод в удобный формат.
- Инструменты для работы с Big Data: Hadoop, MapReduce, Apache Hive, Apache Kafka, Apache Spark.
- Как установить закономерности и видеть логические связи в системе полученных сведений.
- Как разработать действенные бизнес-решения.
- Как извлекать нужную информацию из разных источников.
- Английский язык для чтения профессиональной литературы и общения с зарубежными клиентами.
- Как успешно внедрить программу.
- Область деятельности организации, на которую работает.
Помимо того, что специалист по данным должен обладать аналитическим и математическим складом ума, он также должен быть:
- трудолюбивым,
- настойчивым,
- скрупулезным,
- внимательным,
- усидчивым,
- целеустремленным,
- коммуникабельным.
Хочу отметить, что гуманитариям достичь высот в этой профессии будет крайне тяжело. Только при большом желании можно пробовать осваивать данную стезю.
Будущее Data Science
У Data Science большие перспективы, и вот почему:
Экспоненциальный рост объема данных в мире
Люди проводят все больше времени в интернете, бизнес диджитализируется, начинает развиваться интернет вещей (IoT). К 2025 году объем данных в мире увеличится почти в 3 раза, до 181 Зеттабайта (секстилиона байтов). Еще в 2010 году в мире было всего 2 Зб.
Рост рынка Data Science
Гигантские объемы данных ведут к росту количества Data Science-стартапов и вакансий специалистов по анализу данных. По прогнозам, до 2027 года рынок будет в среднем расти на 27% в год. Больше всего решений требуется в маркетинге и рекламе, логистике, финансах и поддержке пользователей.
Развитие технологий искусственного интеллекта
Эксперты утверждают, что в ближайшем будущем на улицах городов массово появятся беспилотные автомобили, а домашняя техника будет подключена к интернету вещей (IoT). Автономные автомобили используют машинное обучение для анализа дорожной ситуации и безопасного передвижения. IoT позволит получать данные миллиардов новых устройств и использовать искусственный интеллект в системах «умного дома».
Все это ведет к повышению спроса на дата-сайентистов. Так, количество вакансий в этой сфере в России за три года выросло на 433%. Спрос на специалистов превышает предложение, а это увеличивает их зарплату: junior data scientist после года обучения в среднем получает от 120 тыс. рублей, а после трех лет опыта — от 250 тыс. рублей.
Курс
Data Scientist
Специалисты Data Science нужны во всех сферах бизнеса — получите востребованную профессию и станьте одним из них. Дополнительная скидка 5% по промокоду BLOG.
Узнать больше
С чего начать обучение Data Science самостоятельно
Научиться основам Data Science с нуля можно примерно за год. Для этого нужно освоить несколько направлений.
Python. Из-за простого синтаксиса этот язык идеально подходит для новичков. Со знанием Python можно работать и в других IT-областях, например веб-разработке и даже гейм-дизайне. Для работы нужно также освоить инструменты Data Science, например Scikit-Learn, которые упрощают написание кода на Python.
Математика. Со знанием Python уже можно работать ML-инженером. Но для полного цикла Data Science нужно уметь работать с математическими моделями, чтобы анализировать данные. Для этого изучают линейную алгебру, матанализ, статистику и теорию вероятностей. Также математика нужна, чтобы понимать, как устроен алгоритм, и уметь подобрать правильные параметры для задачи.
Машинное обучение. Используйте знания Python и математики для создания и тренировки ML-моделей. Код для моделей и наборы данных для обучения (датасеты) можно найти, например, на сайте Kaggle. Подробнее о том, зачем дата-сайентисту Kaggle, читайте в статье.
Визуальный анализ данных (EDA) отвечает на вопросы о том, что происходит внутри данных, позволяет найти выбросы в них и получить инсайты про создание уникальных фичей для будущего алгоритма.
Вот несколько полезных ссылок для новичков:
Книги:
«Изучаем Python», Марк Лутц.
«Python и машинное обучение. Машинное и глубокое обучение с использованием Python, scikit-learn и TensorFlow», Себастьян Рашка, Вахид Мирджалили.
«Теория вероятностей и математическая статистика», Н. Ш. Кремер.
«Курс математического анализа» Л. Д. Кудрявцев.
«Линейная алгебра», В. А. Ильин, Э. Г. Позняк.
Курсы:
Питонтьютор — бесплатный практический курс Python в браузере.
Бесплатный курс по Python от Mail.ru и МФТИ на Coursera.
Модуль по визуализации данных из курса Mail.ru и МФТИ.
Фреймворки, модели и датасеты
Основные библиотеки: NumPy, Scipy, Pandas.
Библиотеки для машинного и глубокого обучения: Scikit-Learn, TensorFlow, Theano, Keras.
Инструменты визуализации: Matplotlib и Seaborn.
Статья на хабре со ссылками на модели из разных сфер бизнеса на GitHub.
Список нужных фреймворков, библиотек, книг и курсов по машинному обучению на GitHub.
Kaggle — база моделей и датасетов, открытые соревнования дата-сайентистов и курсы по машинному обучению.
Дата-сайентистом можно стать и без опыта в этой сфере. За 13 месяцев на курсе по Data Science вы изучите основы программирования и анализа данных на Python, научитесь выгружать нужные данные с помощью SQL и делать анализ данных с помощью библиотек Pandas и NumPy, разберетесь в основах машинного обучения. После обучения у вас будет 8 проектов для портфолио.
Курс
Data Science с нуля
Станьте востребованным специалистом на рынке IT! За 13 месяцев вы получите набор компетенций, необходимый для уровня Junior.
- структуры данных Python для проектирования алгоритмов;
- как получать данные из веб-источников или по API;
- методы матанализа, линейной алгебры, статистики и теории вероятности для обработки данных;
- и многое другое.
Узнать больше
Промокод “BLOG10” +5% скидки
Data Scientist: кто это и что он делает
В переводе с английского Data Scientist – это специалист по данным. Он работает с Big Data или большими массивами данных.
Источники этих сведений зависят от сферы деятельности. Например, в промышленности ими могут быть датчики или измерительные приборы, которые показывают температуру, давление и т. д. В интернет-среде – запросы пользователей, время, проведенное на определенном сайте, количество кликов на иконку с товаром и т. п.
Данные могут быть любыми: как текстовыми документами и таблицами, так и аудио и видеороликами.
От области деятельности зависят и результаты работы Data Scientist. После извлечения нужной информации специалист устанавливает закономерности, подвергает их анализу, делает прогнозы и принимает бизнес-решения.
Человек этой профессии выполняет следующие задачи: оценивает эффективность и работоспособность предприятия, предлагает стратегию и инструменты для улучшения, показывает пути для развития, автоматизирует нудные задачи, помогает сэкономить на расходах и увеличить доход.
Его труд заканчивается созданием модели кода программы, сформировавшейся на основе работы с данными, которая предсказывает самый вероятный результат.
Профессия появилась относительно недавно. Лишь десятилетие назад она была официально зафиксирована. Но уже за такой короткий промежуток времени стала актуальной и очень перспективной.
Каждый год количество информации и данных увеличивается с геометрической прогрессией. В связи с этим информационные массивы уже не получается обрабатывать старыми стандартными средствами статистики. К тому же сведения быстро обновляются и собираются в неоднородном виде, что затрудняет их обработку и анализ.
Вот тут на сцене и появляется Data Scientist. Он является междисциплинарным специалистом, у которого есть знания статистики, системного и бизнес-анализа, математики, экономики и компьютерных систем.
Знать все на уровне профессора не обязательно, а достаточно лишь немного понимать суть этих дисциплин. К тому же в крупных компаниях работают группы таких специалистов, каждый из которых лучше других разбирается в своей области.
Более 100 крутых уроков, тестов и тренажеров для развития мозга
Начать развиваться
Эти знания помогают ему выполнять свои должностные обязанности:
- взаимодействовать с заказчиком: выяснять, что ему нужно, подбирать для него подходящий вариант решения проблемы;
- собирать, обрабатывать, анализировать, изучать, видоизменять Big Data;
- анализировать поведение потребителей;
- составлять отчеты и делать презентации по выполненной работе;
- решать бизнес-задачи и увеличивать прибыль за счет использования данных;
- работать с популярными языками программирования;
- моделировать клиентскую базу;
- заниматься персонализацией продуктов;
- анализировать эффективность деятельности внутренних процессов компании;
- выявлять и предотвращать риски;
- работать со статистическими данными;
- заниматься аналитикой и методами интеллектуального анализа;
- выявлять закономерности, которые помогают организации достигнуть конечной цели;
- программировать и тренировать модели машинного обучения;
внедрять разработанную модель в производство.
Четких границ требований к Data Scientist нет, поэтому работодатели часто ищут сказочное создание, которое может все и на превосходном уровне. Да, есть люди, которые отлично понимают статистику, математику, аналитику, машинное обучение, экономику, программирование. Но таких специалистов крайне мало.
Еще часто Data Scientist путают с аналитиком. Но их задачи несколько разные. Поясню, что такое аналитика и как она отличается от деятельности Data Scientist, на примере и простыми словами.
В банк пришел клиент, чтобы оформить кредит. Программа начинает обрабатывать данные этого человека, выясняет его кредитную историю и анализирует платежеспособность заемщика. А алгоритм, который решает выдавать кредит или нет, – продукт работы Data Scientist.
Аналитик же, который работает в этом банке, не интересуется отдельными клиентами и не создает технические коды и программы. Вместо этого он собирает и изучает сведения обо всех кредитах, что выдал банк за определенный период, например, квартал. И на основе этой статистики решает, увеличить ли объемы выдачи кредитов или, наоборот, сократить.
Аналитик предлагает действия для решения задачи, а Data Scientist создает инструменты.





