Глубины siem: корреляции «из коробки». часть 2. схема данных как отражение модели «мира»
Содержание:
- Создание связей между сущностями
- Правила целостности данных
- Анализ требований: определение цели базы данных
- Структура базы данных: построение блоков
- Нормализация базы данных
- Этапы создания базы данных
- Добавление индексов и представлений
- Зачем в 1С:Предприятии понадобилась ER-модель
- Сценарий 4. Разработка
- Сценарий 2. Разобраться с устройством механизма или подсистемы
- Системы управления базами данных
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:

Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:

Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:

При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:

Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:

Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Правила целостности данных
Также с помощью средств проектирования баз данных необходимо настроить БД с учетом возможности проверки данных на соответствие определенным правилам. Многие СУБД, такие как Microsoft Access, автоматически применяют некоторые из этих правил.
Правило целостности гласит, что первичный ключ никогда не может быть равен NULL. Если ключ состоит из нескольких столбцов, ни один из них не может быть равен NULL. В противном случае он может неоднозначно идентифицировать запись.
Правило целостности ссылок требует, чтобы каждый внешний ключ, указанный в одной таблице, сопоставлялся с одним первичным ключом в таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо реализовать во всех объектах, на которые ссылается этот ключ в базе данных.
Правила целостности бизнес-логики обеспечивают соответствие данных определенным логическим параметрам. Например, время встречи должно быть в пределах стандартных рабочих часов.
Анализ требований: определение цели базы данных
Например, если вы создаете базу данных для публичной библиотеки, нужно продумать, каким образом и читатели, и библиотекари должны получать доступ к БД.
Вот несколько способов сбора информации перед созданием базы данных:
- Опрос людей, которые будут ее использовать;
- Анализ бизнес-форм, таких как счета-фактуры, расписания, опросы;
- Рассмотрение всех существующих систем данных (включая физические и цифровые файлы).
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Клиенты
- Имя;
- Адрес;
- Город, штат, почтовый индекс;
- Адрес электронной почты.
Товары
- Название;
- Цена;
- Количество в наличии;
- Количество под заказ.
Заказы
- Номер заказа;
- Торговый представитель;
- Дата;
- Товар;
- Количество;
- Цена;
- Стоимость.
При проектировании реляционной базы данных эта информация позже станет частью словаря данных, в котором описаны таблицы и поля БД. Разбейте информацию на минимально возможные части. Например, подумайте о том, чтобы разделить поле почтового адреса и штата, чтобы можно было фильтровать людей по штату, в котором они проживают.
После того, как вы определились с тем, какие данные будут включены в базу, откуда эти данные будут поступать, и как они будут использоваться, можно приступить к планированию фактической БД.
Структура базы данных: построение блоков
Следующим шагом будет визуальное представление базы данных. Для этого нужно точно знать, как структурируются реляционные БД. Внутри базы связанные данные группируются в таблицы, каждая из которых состоит из строк и столбцов.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.

Чтобы при проектировании модели базы данных обеспечить согласованность разных записей, назначьте соответствующий тип данных для каждого столбца. К общим типам данных относятся:
- CHAR — конкретная длина текста;
- VARCHAR — текст различной длины;
- TEXT — большой объем текста;
- INT — положительное или отрицательное целое число;
- FLOAT, DOUBLE — числа с плавающей запятой;
- BLOB — двоичные данные.
Некоторые СУБД также предлагают тип данных Autonumber, который автоматически генерирует уникальный номер в каждой строке.
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:

При проектировании информационной базы данных необходимо решить, какие атрибуты будут служить в качестве первичного ключа для каждой таблицы, если таковые будут. Первичный ключ (PK) — это уникальный идентификатор для данного объекта. С его помощью вы можете выбрать данные конкретного клиента, даже если знаете только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL (они не могут быть пустыми). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно (это называется составным ключом).
Когда придет время создавать фактическую БД, вы реализуете как логическую, так и физическую структуру через язык определения данных, поддерживаемый вашей СУБД.
Также необходимо оценить размер БД, чтобы убедиться, что можно получить требуемый уровень производительности и у вас достаточно места для хранения данных.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:

Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:

В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

Этапы создания базы данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее
Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда, написанная на языке SQL (а не иерархическая, сетевая или объектная модели)
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
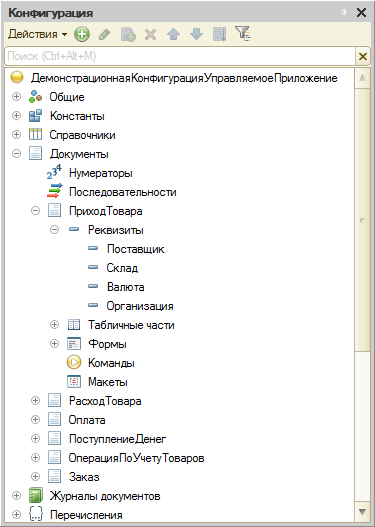
Зачем в 1С:Предприятии понадобилась ER-модель
Необходимость использования этой модели данных в 1С:Предприятии прямо связана с ростом платформы и значительным усложнением прикладных решений. По этой же причине мы реализовали схему данных в составе новой среды разработки EDT, которая ориентирована именно на большие конфигурации.
Если посмотреть на любую базу данных 1С:Предприятия то вы увидите, что она основана на реляционной модели. Грубо говоря, она состоит из таблиц, которые связаны между собой различными способами. Таблицы имеют поля, из этих полей формируются ключи, которые позволяют связывать таблицы друг с другом.
Такая модель удобна для компьютерной обработки, но неудобна для визуального представления разработчику. Особенно неудобна она в случае 1С:Предприятия, где большинство таблиц имеет не абстрактное, а совершенно конкретное прикладное значение.
Поэтому исторически в конфигураторе 1С:Предприятия используется другая концептуальная модель, представляющая базу данных в виде дерева объектов конфигурации. Объекты конфигурации скрывают за собой реляционную модель, они сгруппированы по принадлежности к тому или иному классу прикладных задач. Такое представление удобно для быстрого нахождения нужных объектов, изменения их свойств и т.д. Однако это представление не даёт простого и наглядного понятия о взаимной связи разных объектов между собой.
Современные прикладные решения 1С:Предприятия содержат большое количество объектов конфигурации, 10 тысяч и более. При таком количестве объектов задача нахождения их взаимных связей с помощью имеющихся инструментов становится довольно трудоёмкой. Причём трудоёмкость растёт не только за счёт прямого увеличения времени поиска ссылок среди большого количества объектов. Она растёт и косвенно, за счёт того, что найденные связи необходимо как-то запомнить и визуализировать. И если таких связей много, встаёт вопрос выбора подходящего внешнего инструмента.
Использование ER-модели (Entity-Relationship Model) как раз решает эту проблему. ER-модель представляет любую структуру данных в виде совокупности сущностей, обладающих атрибутами. Эти сущности взаимодействуют между собой при помощи связей.
В наших терминах, в терминах 1С:Предприятия, сущность это объект конфигурации, а атрибут это реквизит объекта конфигурации в широком смысле: реквизит, измерение, ресурс и т.д. Таким образом, ER-модель базы данных 1С:Предприятия это набор (никак не структурированный) объектов конфигурации (с их реквизитами), между которыми существуют некоторые связи. А схема данных это инструмент, позволяющий визуализировать эту модель.
Всё это теоретическое отступление мы написали только ради того, чтобы обратить ваше внимание на две важные вещи.
Во-первых, схема данных это не что-то опциональное, это не «бантик», добавляющий привлекательности среде разработки. Это вполне себе самостоятельный инструмент моделирования предметной области, обладающий своими преимуществами и особенностями.
Во-вторых, схема данных это не аналог и не замена дерева объектов конфигурации. Это ещё один инструмент разработки, но он, можно сказать, имеет свою собственную аудиторию.
Дерево объектов конфигурации в большей степени удобно для разработчиков, глубоко погруженных в прикладное решение, или знакомых с его генезисом. Оно позволяет быстро модифицировать приложение, при этом большую часть информации о взаимной связи объектов разработчик прекрасно знает, и обычно просто держит в голове.
В отличие от дерева объектов схема данных ориентирована скорее на тех разработчиков, которые не знакомы с прикладным решением глубоко, но которым необходимо быстро разобраться в устройстве какой-то его части. Также схема данных удобна для документирования разрабатываемых механизмов (в том числе и самими разработчиками), поскольку в понятном виде показывает связи между объектами или группами объектов.
Дальше, без общих рассуждений, мы просто хотим показать вам несколько практических сценариев использования схемы данных. Они помогут вам не только понять её назначение, но и узнать её возможности.
Сценарий 4. Разработка
Как вы видите из третьего примера, схема данных может быть довольно удобным инструментом для документирования некоторого механизма. Но пользоваться ей можно не только после того, как механизм разработан, но и в процессе его разработки.
Прямо сейчас мы реализовали только одну функцию – это переход из схемы данных в редактор объекта конфигурации.
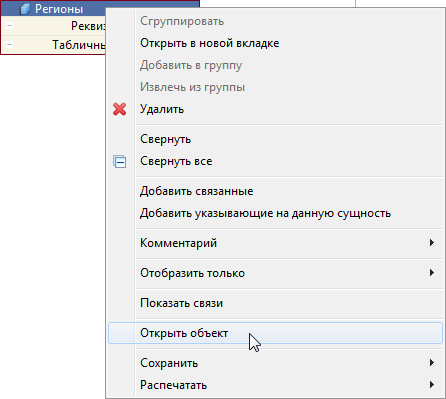
Но теоретически ничто не мешает реализовать и другие функции разработки. Например, создание новых реквизитов объекта не путём их добавления в дерево объектов конфигурации, а путём «протягивания» связи от одного объекта к другому в схеме данных.
Как мы говорили в начале, схема данных это не только новый, но и в некоторой степени экспериментальный инструмент. Мы, конечно, имеем собственные планы по его дальнейшему развитию, но вместе с этим нас интересуют и ваши мысли по этому поводу. Также нам было бы интересно узнать ваше мнение в том случае, если раньше вам уже приходилось (применительно к 1С:Предприятию) решать подобные задачи сторонними средствами.
Ну и конечно, после выпуска этого функционала мы с интересом познакомимся с примерами его реального использования и будем готовы рассматривать и обсуждать ваши пожелания и замечания к этому механизму.
Сценарий 2. Разобраться с устройством механизма или подсистемы
Второй сценарий заключается в том, что вам нужно разобраться с устройством незнакомого механизма или подсистемы. Например, нужно понять, как устроена подсистема ТоварныеЗапасы. Какие объекты в ней задействованы и как они связаны друг с другом.
В этом случае, как и в первом сценарии, вы можете открыть редактор этой подсистемы и перейти на закладку Схема данных. Здесь вы увидите более интересную картину, потому что кроме объектов на этой схеме будут показаны и подчинённые подсистемы.
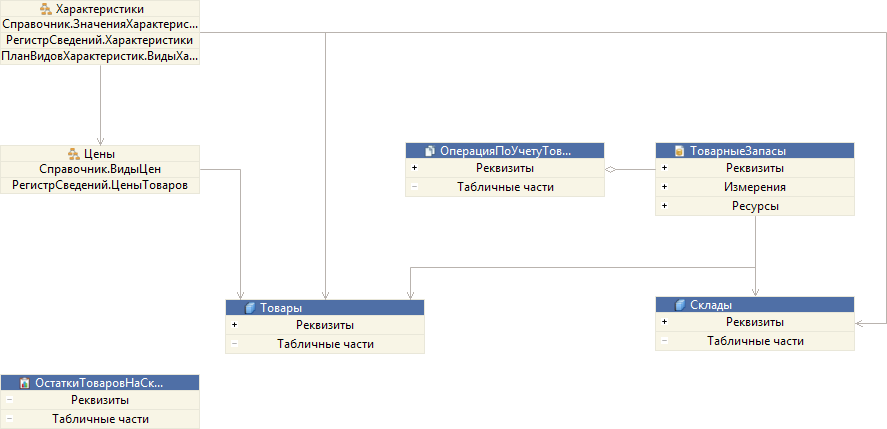
Подсистемы являются группами объектов. Содержащиеся в них объекты имеют связи с объектами, которые находятся «снаружи». Чтобы посмотреть, как устроена любая из этих подсистем, например подсистема Характеристики, вы можете кликнуть на ней прямо в схеме, и увидите её устройство.
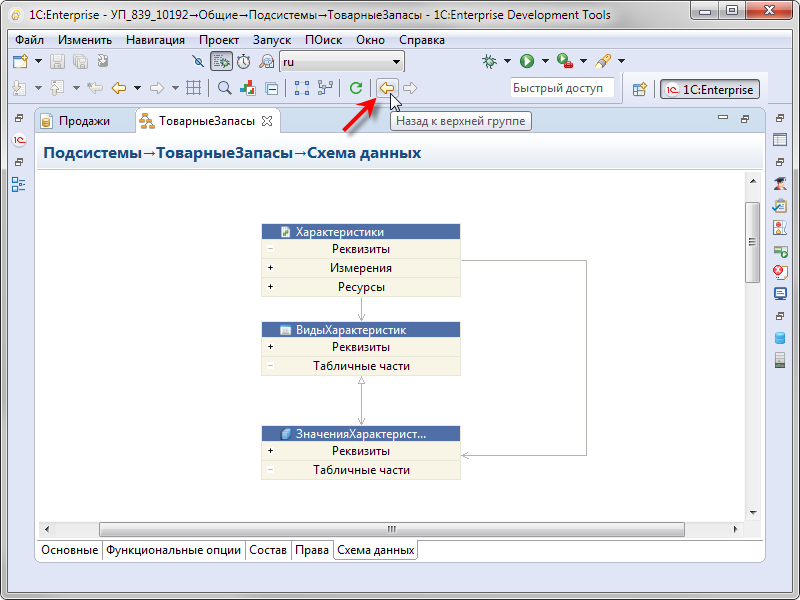
Интересным моментом является то, что схема данных поддерживает переходы Вперед / Назад по аналогии с браузерами. Поэтому, разобравшись с устройством этой подчинённой подсистемы, вы можете просто нажать кнопку Назад, и вернуться к предыдущей схеме.
Системы управления базами данных
Проектируемая структура базы данных зависит от того, какую СУБД вы используете. Некоторые из наиболее распространенных:
- Oracle DB;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- IBM DB2.
Подходящую систему управления базами данных можно выбирать исходя из стоимости, установленной операционной системы, наличия различных функций и т. д.
Пожалуйста, опубликуйте свои мнения по текущей теме материала. За комментарии, дизлайки, подписки, лайки, отклики низкий вам поклон!
Пожалуйста, оставляйте свои мнения по текущей теме материала. За комментарии, подписки, отклики, лайки, дизлайки низкий вам поклон!
Вадим Дворниковавтор-переводчик статьи «Database Structure and Design Tutorial»