Запросы в postgresql: 2. статистика
Содержание:
- Установка MS SQL и PostgreSQL
- Разработка
- Compatibility
- Архитектура PostgreSQL
- Бесплатный MS SQL vs бесплатный PostgreSQL
- Часто встречающиеся ошибки 1С и общие способы их решения Промо
- Установка и настройка
- Преимущества и особенности СУБД PostgreSQL
- Управление таблицами
- Устройство буферного кэша
- Загрузка и установка PostgreSQL
- Специальные схемы, временные объекты
- Формат выводимой информации
Установка MS SQL и PostgreSQL
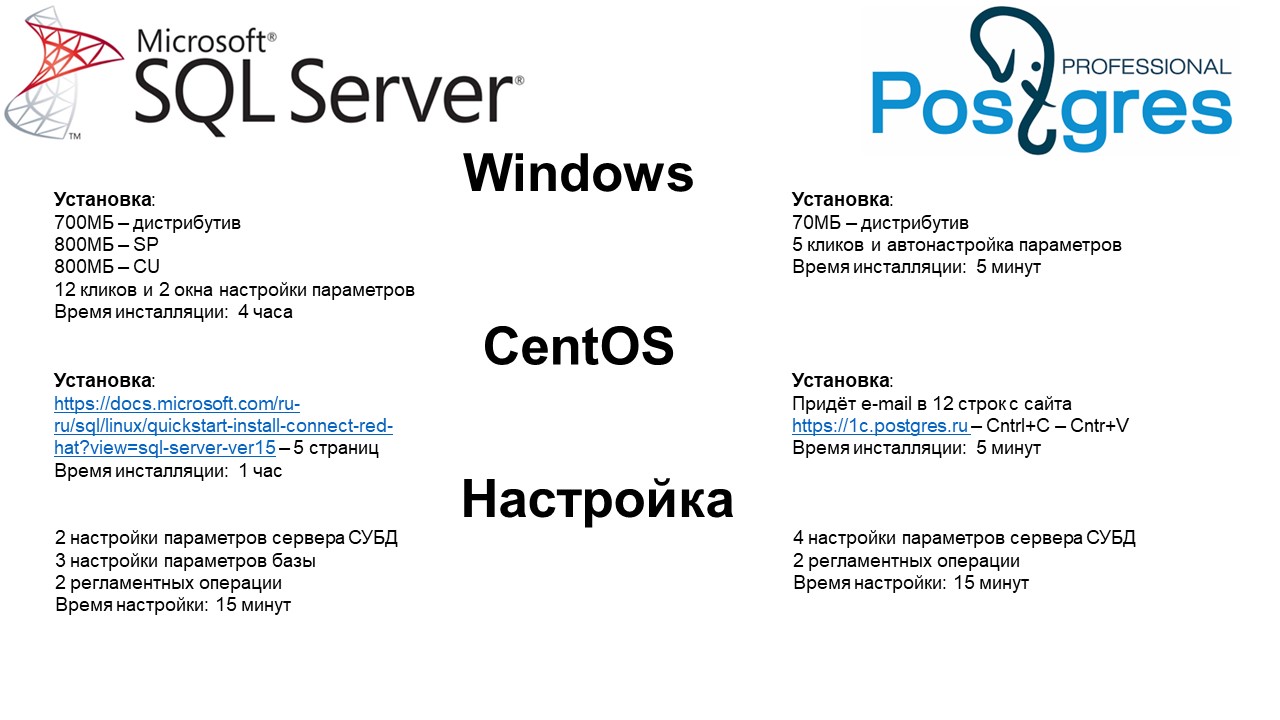
Давайте сравним установку PostgreSQL и MS SQL Server на Windows.
-
Чтобы поставить MS SQL-сервер, надо скачать 2,5 Гб с интернета.
-
При этом дистрибутив Postgres для Windows – 70 Мб.
-
В процессе инсталляции для MS SQL Server, нам надо сделать 12 кликов и пройти два окна настройки параметров, где мы сразу можем настроить: количество и расположение файлов для tempDB, а также расположение базы данных и лога транзакций. Время инсталляции SQL-сервера с учетом скачивания дистрибутивов – 4 часа.
-
«Виндовый» Postgres настраивается в 5 кликов (там всего одно окно настройки), почти все параметры проходят автонастройку, опираясь на параметры вашего компьютера. Я сейчас говорю про дистрибутив от компании Postgres Pro (и платный, и бесплатный настраиваются одинаково). Время инсталляции – 5 минут. Если надо разнести файлы базы, WAL и временных файлов то тогда ещё три строчки в конфигурационном файле.
Дальше давайте теперь сравним установку на Linux. В данном случае будут рассматривать CentOS.
-
Установка MS SQL-сервера на CentOS представляет собой 5 страниц инструкций с сайта Microsoft. Время инсталляции – час. В этот час будет скачиваться неслабый дистрибутив, и потом его нужно будет установить и настроить в командной строке. Время настройки – 15 минут.
-
Для самого MS SQL Server в CentOS нужно будет настроить хотя бы два параметра: это параллелизм и количество потребляемой оперативной памяти.
-
Нужно будет настроить хотя бы три параметра самой базы: как у вас база будет прирастать, какой у вас будет изначальный объем файлов базы данных и журналов транзакций, установить уровень журналирования.
-
Плюс к этому нужно будет настроить минимум две регламентных операций ухаживания за базой – реиндексация и апдейт статистики.
-
-
Устанавливая на CentOS Postgres вам придет письмо с кодом в 12 строчек. Копируете, вставляете, и через 5 минут у вас есть запущенный и готовый Postgres. Для настройки Postgres в Windows и в CentOS вам нужно провести всего четыре настройки параметров сервера СУБД и задать две регламентные операции в cron. На это уйдет максимум 15 минут.
Все эти цифры по поводу настройки и установки пока не в пользу MS SQL.
Я свято уверен, что после настройки и установки в СУБД потом постоянно что-то крутить в настройках СУБД не нужно. Анализ проблем лучше делать в технологическом журнале 1С. Техжурнал 1С покажет более полную комплексную информацию, которая будет содержать не только «тормоза» СУБД, но и «тормоза» самого движка платформы, что часто занимает гораздо более длительное время в исполнении запросов чем время, которое тратит на этот запрос СУБД. И только когда вы нашли проблему, код 1С кажется идеальным а СУБД ведёт себя странно, вот тогда уже нужно идти и смотреть планы запросов, делать выводы и может быть менять настройки, хотя лучше всё таки поменять код 1С, так как улучшив одну операцию изменением настроек СУБД можно очень легко “положить” всю систему.
Разработка
PostgreSQL развивается силами международной группы разработчиков (PGDG), в которую входят как непосредственно программисты, так и те, кто отвечают за продвижение PostgreSQL (Public Relation), за поддержание серверов и сервисов, написание и перевод документации, всего на 2005 год насчитывается около 200 человек. Другими словами, PGDG — это сложившийся коллектив, который полностью самодостаточен и устойчив. Проект развивается по общепринятой среди открытых проектов схеме, когда приоритеты определяются реальными нуждами и возможностями. При этом, практикуется публичное обсуждение всех вопросов в списке рассылке, что практически исключает возможность неправильных и несогласованных решений.
Это относится и к тем предложениям, которые уже имеют или рассчитывают на финансовую поддержку коммерческих компаний.
Цикл работой над новой версией обычно длится 10-12 месяцев (сейчас ведется дискуссия о более коротком цикле 2-3 месяца) и состоит из нескольких этапов.
Compatibility
This command conforms to the SQL standard, except that the FROM and RETURNING
clauses are PostgreSQL
extensions, as is the ability to use WITH with UPDATE.
According to the standard, the column-list syntax should allow
a list of columns to be assigned from a single row-valued
expression, such as a sub-select:
UPDATE accounts SET (contact_last_name, contact_first_name) =
(SELECT last_name, first_name FROM salesmen
WHERE salesmen.id = accounts.sales_id);
This is not currently implemented — the source must be a list
of independent expressions.
Some other database systems offer a FROM option in which the target table is supposed
to be listed again within FROM. That is
not how PostgreSQL interprets
FROM. Be careful when porting
applications that use this extension.
Архитектура PostgreSQL
Одной из наиболее сильных сторон СУБД PostgreSQL является архитектура. Как и в случаях со многими коммерческими СУБД, PostgreSQL можно применять в среде клиент-сервер — это предоставляет множество преимуществ и пользователям, и разработчикам.
В основе PostgreSQL — серверный процесс базы данных, выполняемый на одном сервере. Также стоит сказать, что в Postgres пока не реализована технология высокой готовности, как это сделано в ряде других коммерческих систем управления базами данных уровня предприятия (они способны распределять нагрузку между некоторым количеством серверов, достигая дополнительной масштабируемости и повышенной устойчивости к внешним воздействиям).
Доступ из приложений к данным базы PostgreSQL производится с помощью специального процесса базы данных. То есть клиентские программы не могут получать самостоятельный доступ к данным даже в том случае, если они функционируют на том же ПК, на котором осуществляется серверный процесс.
Таким образом мы получаем разделение клиентов и сервера, что даёт возможность создавать распределённые системы. К примеру, мы можем отделить клиентов от сервера с помощью сети, разрабатывая клиентские приложения в среде, которая удобна для пользователя. Допустим, появляется возможность реализовать базу данных под UNIX, создав клиентские приложения, которые станут работать в ОС Microsoft Windows.
Давайте посмотрим на типичную модель распределенного приложения СУБД PostgreSQL:
Мы видим, что несколько клиентов подсоединены к серверу по сети. СУБД PostgreSQL ориентирована на протокол TCP/IP (локальная сеть либо Интернет), при этом каждый клиент соединён с главным серверным процессом БД (на схеме этот процесс называют Postmaster). Именно Postmaster создаёт новый серверный процесс специально в целях обслуживания запросов на доступ к данным определённого клиента.
Так как манипулирование с данными сосредотачивается на сервере, СУБД PostgreSQL не приходится контролировать многочисленных клиентов, которые получают доступ в совместно используемый серверный каталог. В результате база данных PostgreSQL способна поддерживать целостность данных даже в случае одновременного доступа большого числа пользователей.
Соединение с базой данных клиентских приложений осуществляется по специальному протоколу СУБД PostgreSQL. В принципе, никто не мешает инсталлировать на стороне клиента ПО, предоставляющее стандартный интерфейс, обеспечивающий работу с нужным приложением, допустим, по стандарту ODBC/JDBC. И это хорошо, ведь доступность ODBC-драйвера даёт возможность использовать СУБД PostgreSQL в качестве базы данных для множества уже существующих приложений, включая продукты Microsoft Office — Excel и Access.
Идём дальше. Клиент-серверная архитектура, реализованная в СУБД PostgreSQL, делает возможным разделение труда. То есть машина-сервер прекрасно подходит для хранения и управления доступом к огромным объёмам данных, то есть её можно использовать в качестве надёжного репозитория. При этом для клиентов возможна разработка сложных графических приложений. Также можно создать внешний онлайн-интерфейс, предоставляющий доступ к данным и возвращающий результат в виде web-страниц в стандартный web-браузер, не требуя при этом никакого дополнительного клиентского ПО.
Бесплатный MS SQL vs бесплатный PostgreSQL

Нельзя сравнивать платный MS SQL – Standard и Enterprise – с бесплатным PostgreSQL, это не совсем корректное сравнение. Нельзя ожидать от бесплатного ПО такой же скорости, как и от платного, причем неслабо платного.
Давайте сравним бесплатную версию MS SQL Express и бесплатные версии PostgreSQL.
Бесплатные версии Postgres – это:
-
Самосборки, когда вы с сайта postgresql.org скачали исходники, добавили туда патчи для 1С и собрали свою сборку. Она бесплатна, пожалуйста, пользуйтесь.
-
То же самое можно сделать, скачав сборку, которую собрали специалисты фирмы «1С» с сайта – releases.1с.ru. Эта сборка будет отличаться от вашей самосборки тем, что она после сборки протестирована фирмой 1С.
-
Есть еще третий вариант – сайт 1с.postgres.ru. Это сборка от компании Postgres Professional – эта команда работает со своими серверами сборки, и они делают бесплатную версию для 1С. где в ванильную сборку добавляют несколько своих патчей, которые считают нужным. На то какие патчи они добавят, а какие – нет, мы с вами повлиять не можем. Но на моей практике сборка с 1с.postgres.ru работает намного стабильнее. Кто имеет доступ на партнерские форумы 1С, там есть несколько обращений, когда у людей сбоили самосборки или сборки с releases, при этом ставим сборки с 1с.postgres.ru с той же версией Postgres, и все отлично работает. Поэтому я бы советовал ставить отсюда.
Теперь давайте сравним бесплатные версии MS SQL Express и Postgres. Какие ограничения они накладывают:
-
На количество ядер.
-
MS SQL Express в последней поддерживаемой 1С 17 версии, позволяет использовать только 4 ядра.
-
бесплатный Postgres – безлимитное количество ядер.
-
-
То же самое по памяти.
-
MS SQL Express может использовать 1,5 Гб памяти и все.
-
Postgres – безлимитно.
-
-
Объем базы:
-
MS SQL Express – 10 Гб,
-
у Postgres – безлимитно.
-
-
Отказоустойчивость:
-
в MS SQL Express не поддерживается вообще.
-
В Postgres доступны логические и физические репликации любого уровня каскадирования. Вы можете одновременно делать с мастера десятки реплик. Или сделать реплику с мастера, а с реплики – еще одну (иногда это имеет смысл). Бесплатный Postgres позволит снимать бэкапы с реплики, не трогая этими задачами мастер.
-
Есть несколько важных моментов:
-
бэкап у MS SQL консистентен на момент окончания бэкапа, а бэкап Postgres’a (dump) консистентен на момент начала бэкапа.
-
Если вы сливаете этот dumpс мастера Postgres (с главного сервера), то в момент этого бэкапа вы не сможете произвести структурные изменения в 1С, так как они содержат в себе команды drop для таблиц либо удаления столбцов. Postgres не позволит изменить структуру данных в части удаления, пока он снимает dump. Этот момент нужно учитывать при проектировании системы.
-
-
-
Регламентные операции плюс бэкапы
-
На MS SQL Express регламенты можно делать только скриптами и cron. Нет там планировщика (агента SQL Server), его там не существует. Вы не сможете внутри SQL создать никаких расписаний или операций. Надо будет батнички нарисовать, засунуть это либо в cron, либо в планировщик Windows.
-
То же самое на Postgres, все регламентные операции, бэкапы и восстановления из бэкапов – это скрипты, cron или планировщик Windows, смотря в какой системе вы это делаете.
-
-
Ещё момент – бесплатные версии обоих продуктов не входят в список импортозамещающих продуктов. Компаниям госсектора эти базы данных запрещены в использовании вообще, не только в 1С.
-
Также на бесплатном Postgres и бесплатном MS SQL нет ФСТЭКа. Никто не получает сертификаты ФСТЭК на эти продукты. Забегая вперед, скажу, что и в платном MS SQL ФСТЭКа нет.
С бесплатными версиями все более менее понятно, поехали в платные версии.
Часто встречающиеся ошибки 1С и общие способы их решения Промо
Статья рассчитана в первую очередь на тех, кто недостаточно много работал с 1С и не успел набить шишек при встрече с часто встречающимися ошибками. Обычно можно определить для себя несколько действий благодаря которым можно определить решится ли проблема за несколько минут или же потребует дополнительного анализа. В первое время сталкиваясь с простыми ошибками тратил уйму времени на то, чтобы с ними разобраться. Конечно, интернет сильно помогает в таких вопросах, но не всегда есть возможность им воспользоваться. Поэтому надеюсь, что эта статья поможет кому-нибудь сэкономить время.
Установка и настройка
В данном разделе представлена инструкция по установки и настройке PostgreSQL для разных ОС
Установка
Если установка происходит на macOS, то процесс установки можно запустить командой:
brew install postgresql
На Linux СУБД устанавливается так:
sudo apt-get install postgresql postgresql-contrib
После того, как все загружено и установлено, можно проверить, все ли в порядке, и какая стоит версия PostgreSQL. Для этого выполните следующую команду:
postgres --version
Инструкция по установке в цифровом формате
Настройка
Работа с PostgreSQL может быть произведена через командную строку (терминал) с использованием утилиты psql – инструмент командной строки PostgreSQL.
Необходимо ввести следующую команду:
psql postgres (для выхода из интерфейса используйте \q)
Этой командой запускается утилита psql. Хотя есть много сторонних инструментов для администрирования PostgreSQL, нет необходимости их устанавливать, т. к. psql удобен и отлично работает.
Если нужна помощь, введите (или ) в psql-терминале. Появится список всех доступных параметров справки. Вы можете ввести , если вам нужна помощь по конкретной команде. Например, если ввести в консоли psql, отобразится синтаксис команды .
1 Description update rows of a table
2 WITH RECURSIVE with_query [,
3 UPDATE ONLY table_name * AS alias
4 SET { column_name = { expression | DEFAULT } |
5 ( column_name [, ) = ( { expression | DEFAULT } [, ) |
6 ( column_name [, ) = ( sub-SELECT )
7 } [,
8 FROM from_list
9 WHERE condition | WHERE CURRENT OF cursor_name
10 RETURNING * | output_expression AS output_name [,
Для начала необходимо проверить наличие существующих пользователей и баз данных. Выполните следующую команду, чтобы вывести список всех баз данных:
\list или \l
Рисунок 1 — Результат выполнения операции \l
На рисунке выше вы видите три базы данных по умолчанию и суперпользователя postgres, которые создаются при установке PostgreSQL.
Чтобы вывести список всех пользователей, выполните команду . Атрибуты пользователя postgres говорят нам, что он суперпользователь.
Рисунок 2 — Результат выполнения операции \du
Преимущества и особенности СУБД PostgreSQL
СУБД PostgreSQL использует для своих баз данных реляционную модель, поддерживая стандартный язык запросов SQL. При этом PostgreSQL предоставляет широкий спектр возможностей. Можно сказать, что Postgres обладает почти всеми возможностями, существующими в других базах данных (как коммерческих, так и Open Source), а также рядом дополнительных.
Сегодня СУБД PostgreSQL работает почти на всех UNIX-платформах, в том числе и на UNIX-подобных системах (FreeBSD и Linux). Вы сможете использовать эту базу данных и на Windows NT Server, и на Windows 2000 Server, и для разработки рабочих станций ME.
Рассмотрим краткий перечень преимуществ и функциональных возможностей СУБД PostgreSQL:
1. Надежность. Надёжность СУБД PostgreSQL проверена и доказана. Она обеспечивается соответствием принципам ACID (атомарность, изолированность, непротиворечивость, сохранность данных), многоверсионностью, наличием Write Ahead Logging (WAL) — общепринятого механизма протоколирования всех существующих транзакций. Сюда же стоит отнести и возможность восстановления базы данных Point in Time Recovery (PITR), репликацию, поддержку целостности данных на уровне схемы.
2. Производительность. В СУБД PostgreSQL она основана на применении индексов, наличии гибкой системы блокировок и интеллектуального планировщика запросов, использовании системы управления буферами памяти и кэширования. Не стоит забывать и про отличную масштабируемость при конкурентной работе.
3. Расширяемость. Для СУБД PostgreSQL это означает, что пользователь может настроить систему посредством определения новых функций, типов, языков, агрегатов, индексов и операторов. А объектная ориентированность СУБД PostgreSQL даёт возможность переносить логику приложения на уровень базы данных, а это, в свою очередь, заметно упрощает разработку клиентов, ведь вся бизнес-логика находится в БД. При этом функции в Postgres однозначно определяются названием, типами и числом аргументов.
4. Поддержка SQL. Её уже упоминали, однако кроме главных возможностей, которые присущи любой SQL-базе, PostgreSQL поддерживает схемы, подзапросы, внешние связки, правила, курсоры, наследование таблиц, триггеры и много чего ещё.
5. Поддержка многочисленных типов данных. СУБД PostgreSQL поддерживает численные (целые, денежные, с фиксированной/плавающей точкой), булевые, символьные, составные, сетевые типы данных, а также перечисление, типы «дата/время», геометрические примитивы, массивы, XML- и JSON-данные. Плюс можно создавать свои типы данных.
Конечно, это далеко не всё, но для общего понимания возможностей СУБД PostgreSQL вполне достаточно. Естественно, база данных заслуживает внимания, особенно если учесть, что она имеет открытый исходный код и распространяется свободно. Освоить эту СУБД вы cможете на курсе в OTUS.
Управление таблицами
Создание новой или временной таблицы
CREATE TABLE table_name( pk SERIAL PRIMARY KEY, c1 type(size) NOT NULL, c2 type(size) NULL, ... );
Добавление нового столбца в таблицу:
ALTER TABLE table_name ADD COLUMN new_column_name TYPE;
Удаление столбца в таблице:
ALTER TABLE table_name DROP COLUMN column_name;
Переименовать столбец:
ALTER TABLE table_name RENAME column_name TO new_column_name;
Установите или удалите значение по умолчанию для столбца:
ALTER TABLE table_name ALTER COLUMN
Добавление первичного ключа к таблице.
ALTER TABLE table_name ADD PRIMARY KEY (column,...);
Удаление первичного ключа из таблицы.
ALTER TABLE table_name DROP CONSTRAINT primary_key_constraint_name;
Переименовать таблицу.
ALTER TABLE table_name RENAME TO new_table_name;
Удаление таблицы и зависимых от нее объектов:
DROP TABLE table_name CASCADE;
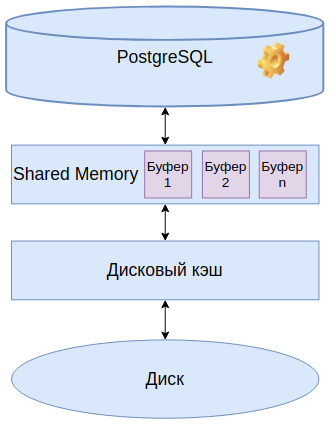
Устройство буферного кэша
Кэш нужен чтобы читать востребованные данные ни с диска а с более быстрой оперативной памяти. Предварительно данные приходится загружать с диска в буферных кэш оперативной памяти.
В общей памяти отводится определённый кусок памяти под массив буферов. В каждом буфере хранится одна страница памяти. Страница памяти это 8 КБ. Когда мы собираем PostgreSQL из исходных кодов мы можем изменить размер этой страницы. А после сборки это изменить уже не получится.
Есть 3 варианта размера страниц:
- 8 КБ
- 16 КБ
- 32 КБ
Буферный кэш занимает большую часть общей памяти.
Если процессу понадобятся какие-то данные он их вначале ищет в буферном кэше. Если данных в кэше не оказалось, то мы просим операционную систему прочитать эту страничку и поместить в буферный кэш. Операционная система имеет свой дисковые кэш, и ищет эту страничку там, если не находит, то читает с диска и помещает в дисковый кэш. Затем из дискового кэша страничка помещается в буферный кэш для PostgreSQL.
Так как буферный кэш находится в общей памяти, то чтобы разные процессы не мешали друг другу, к нему применяют различные блокировки.
Загрузка и установка PostgreSQL
PostgreSQL поддерживает все основные операционные системы. Процесс установки прост, поэтому я постараюсь рассказать
о нем как можно быстрее.

Для Windows и Mac ты можешь загрузить установщик
с
веб-сайта EDB
.
EDB больше не предоставляет пакеты для систем GNU/Linux. Вместо этого они рекомендуют вам использовать диспетчер
пакетов твоего дистрибутива.
Установщики включают в себя разные компоненты.
Вот самые важные из них:
- Сервер PostgreSQL (очевидно)
- pgAdmin, графический инструмент для управления базами данных
- Менеджер пакетов для загрузки и установки дополнительных инструментов и драйверов
Windows
Скачав установщик, запусти его как любой другой исполняемый файл. Процесс довольно прямолинеен,
но некоторые вещи все же заслуживают внимания.
Диалоговое окно «Выбрать компоненты» позволяет выборочно устанавливать компоненты.
Если у тебя нет веской причины что-то менять — оставляй все как есть.
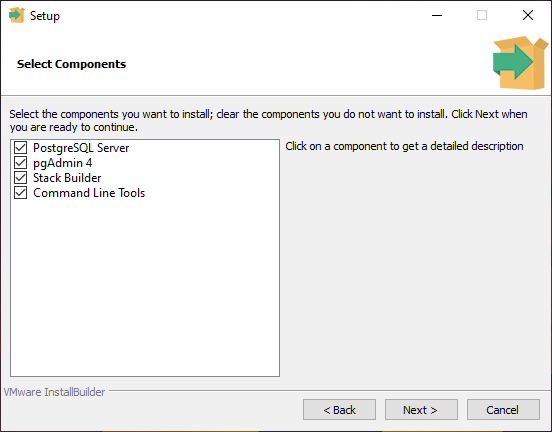
По умолчанию PostgreSQL создает суперпользователя с именем (воспринимай его как учетную запись
администратора сервера базы данных).
Во время установки тебе нужно будет указать пароль для суперпользователя (root).
Позже ты сможешь создать других пользователей и назначать им отдельные доступы и роли.
Мы вернемся к этому позже, а сейчас тебе понадобится учетная запись суперпользователя, чтобы начать использовать СУБД.
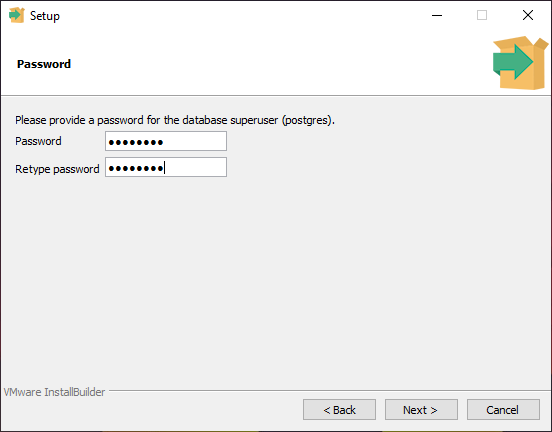
Чтобы запустить сервер разработки на твоем компьютере или , необходимо
назначить ему порт.
Порт по умолчанию — 5432. Если ты устанавливаешь PostgreSQL впервые, то он скорее всего свободен.
Если окажется, что этот порт уже занят другим экземпляром PostgreSQL, ты можешь указать другое значение, например 5433.
После завершения установки ты сможешь запустить SQL Shell, поставляемый с Postgres.
Шаг за шагом ты выберешь сервер, какую базу данных использовать, порт, имя пользователя и пароль.
Используй данные, которые ты вводил на предыдущих шагах.
Поздравляю! Настройка для Windows завершена, и скоро мы начнем писать первые SQL запросы.
Ниже список вариантов установки для других операционных систем.
macOS
Для macOS у тебя есть разные варианты. Можно скачать установщик с сайта EDB и запустить его.
Кроме того, можно использовать , простое приложение для macOS.
После запуска у тебя появится сервер PostgreSQL, готовый к использованию.
Завершить работу сервера можно просто закрыв приложение.
Кроме того, ты также можете использовать , менеджер пакетов для macOS.
GNU/Linux
Ты можешь найти PostgreSQL в репозиториях большинства дистрибутивов Linux. Установить его можно одним щелчком мыши
из выбранного графического диспетчера пакетов.
Альтернативно, можно использовать установку через терминал.
Ты можешь обратиться к документации твоего дистрибутива для получения дополнительных сведений.
Arch
Запуск оболочки PostgreSQL
После установки PostgreSQL, нужно запустить оболочку(shell), с помощью которой ты получишь возможность управлять базой данных.
Открой терминал и введи:
— это оболочка Postgres, аргумент используется для указания пользователя.
Поскольку ты еще не создавал других
пользователей, ты войдешь в систему как суперпользователь .
После этого нужно будет ввести пароль
суперпользователя, который ты выбрал во время установки.
Как только пароль установлен, база данных PostgreSQL готова к работе!
Если сервер PostgreSQL по какой-то причине не запускается, можешь попробовать запустить его вручную.
Специальные схемы, временные объекты
К специальным схемам относят:
- public – по умолчанию входит в путь поиска, если ничего не менять, все объекты будут в этой схеме.
- Схема, одноимённая с пользователем – по умолчанию входит в search_path, но не существует. Если сделать, например схему postgres, то пользователь postgres будет по умолчанию работать с этой схемой.
- pg_catalog – схема для объектов системного каталога. Если pg_catalog не прописан, то это схема будет там подразумеваться первой.
Временные таблицы – существуют на время сеанса или транзакции. Они не журналируются и не попадают в общую память. Чтобы реализовать временную таблицу в postgres применяет временные схемы.
Схема pg_temp_N – автоматически создается для временных таблиц. Такая схема тоже по умолчанию находится в search_path. По окончанию все объекты временной схемы удаляются, а сама схема остается. Оставшаяся временная схема может использоваться для новых временных таблиц, новой транзакции или сеанса.
Формат выводимой информации
Когда вы вводите и выполняете какой-нибудь запрос в терминале psql, то в выводе видите результат этого запроса. По умолчанию такой вывод показывается в форме таблички. Но вы можете настроить формат выводимой информации сами:
- – с выравниванием / без выравнивания
- – отображение строки заголовка и итоговой строки / без такого отображения
- – можно задать разделитель (по умолчанию используется вертикальная черта ‘|’)
- – расширенный режим, когда нужно вывести много столбцов одной таблицы, они будут выведены в один столбец
Например, получим информацию из представления pg_tables. Затем поменяем формат и снова получим информацию. А затем все вернем на место:
postgres@s-pg13:~$ psql psql (13.3) Type "help" for help. postgres=# SELECT * FROM pg_tables LIMIT 5; schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | hastriggers | rowsecurity ------------+-----------------------+------------+------------+------------+----------+-------------+------------- pg_catalog | pg_statistic | postgres | | t | f | f | f pg_catalog | pg_type | postgres | | t | f | f | f pg_catalog | pg_foreign_table | postgres | | t | f | f | f pg_catalog | pg_authid | postgres | pg_global | t | f | f | f pg_catalog | pg_statistic_ext_data | postgres | | t | f | f | f (5 rows) postgres=# \t \a \pset fieldsep ' ' Tuples only is on. Output format is unaligned. Field separator is " ". postgres=# SELECT * FROM pg_tables LIMIT 5; pg_catalog pg_statistic postgres t f f f pg_catalog pg_type postgres t f f f pg_catalog pg_foreign_table postgres t f f f pg_catalog pg_authid postgres pg_global t f f f pg_catalog pg_statistic_ext_data postgres t f f f postgres=# \t \a \pset fieldsep '|' Tuples only is off. Output format is aligned. Field separator is "|". postgres=# SELECT * FROM pg_tables LIMIT 5; schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | hastriggers | rowsecurity ------------+-----------------------+------------+------------+------------+----------+-------------+------------- pg_catalog | pg_statistic | postgres | | t | f | f | f pg_catalog | pg_type | postgres | | t | f | f | f pg_catalog | pg_foreign_table | postgres | | t | f | f | f pg_catalog | pg_authid | postgres | pg_global | t | f | f | f pg_catalog | pg_statistic_ext_data | postgres | | t | f | f | f (5 rows)
А вот пример использования расширенного режима (\x). Выглядит это так, как будто табличку перевернули:
postgres=# \x Expanded display is on. postgres=# SELECT * FROM pg_tables LIMIT 5; ----------------------- schemaname | pg_catalog tablename | pg_statistic tableowner | postgres tablespace | hasindexes | t hasrules | f hastriggers | f rowsecurity | f ----------------------- schemaname | pg_catalog tablename | pg_type tableowner | postgres tablespace | hasindexes | t hasrules | f hastriggers | f rowsecurity | f ----------------------- schemaname | pg_catalog tablename | pg_foreign_table tableowner | postgres tablespace | hasindexes | t hasrules | f hastriggers | f rowsecurity | f ----------------------- schemaname | pg_catalog tablename | pg_authid tableowner | postgres tablespace | pg_global hasindexes | t hasrules | f hastriggers | f rowsecurity | f ----------------------- schemaname | pg_catalog tablename | pg_statistic_ext_data tableowner | postgres tablespace | hasindexes | t hasrules | f hastriggers | f rowsecurity | f